AI预测-VMD-CNN-LSTM时序预测
发布时间:2024年01月22日
AI预测相关目录
AI预测流程,包括ETL、算法策略、算法模型、模型评估、可视化等相关内容
最好有基础的python算法预测经验
- EEMD策略及踩坑
- VMD-CNN-LSTM时序预测
一、VMD介绍
VMD(变分模态分解)是一种信号处理技术,用于将复杂的非线性或非平稳信号分解成多个模态信号。它通过自适应的方式确定信号的模态分解个数,并能够匹配每种模态的最佳中心频率和有限带宽,从而实现信号的有效分解。VMD的核心思想是构建和求解变分问题,以获得给定信号的有效分解成分。
VMD有一些可调参数,例如带宽约束参数alpha、噪声容忍度参数tau、模态数量参数K和直流分量参数DC等。这些参数可以影响VMD的分解效果,通过调整这些参数可以获得更好的分解结果。
对于非线性或非平稳信号,vmd具有比较不错的特征提取效果,可以用于风速等变化规律不明确的数据相关预测类任务。
二、CNN-LSTM
CNN-LSTM是一种结合了卷积神经网络(CNN)和长短期记忆网络(LSTM)的特点的深度学习算法模型。CNN部分通常包含多个卷积层、池化层和激活函数,用于提取输入数据的局部特征。提取出的特征会被送入LSTM部分进行处理。LSTM部分通常包含多个LSTM层,用于处理序列数据。在每个时间步,LSTM层会接收来自CNN部分的特征,并输出一个隐藏状态,该隐藏状态会传递给下一个时间步。LSTM的隐藏状态会在最终时间步被用于生成最终的预测结果或分类标签等。
三、VMD与CNN-LSTM的适配性
VMD-CNN-LSTM模型的设计源自于VMD与CNN-LSTM的适配性。
VMD对时序数据挖掘后,将单维度数据转化为2维度特征矩阵
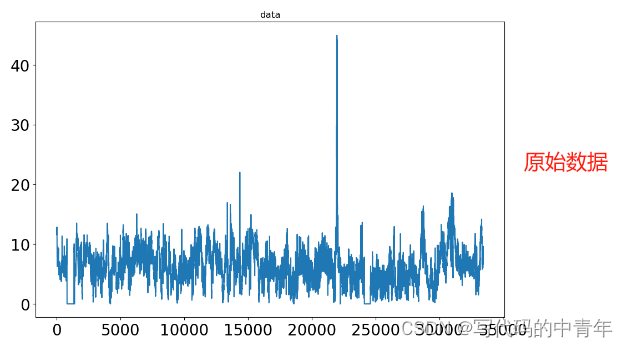
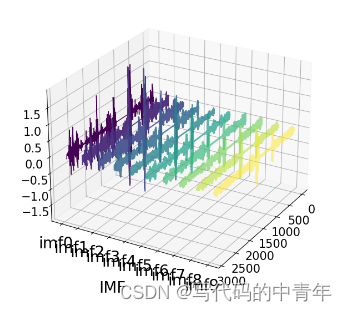
而cnn模型本身是对图像等二维数据进行特征提取效果非常优质是算法,用其对vmd分解后的特征数据进行进一步特征提取后,输入到lstm模型拟合时序时序数据,可以取得比较好的结果。
三、代码示例
1.VMD
def vmd_decompose(series=None, alpha=2000, tau=0, K=10, DC=0, init=1, tol=1e-7, draw=True):
"""
对给定的时间序列进行 VMD 分解。
参数:
- series:输入的时间序列。
- alpha:在 VMD 模型中平衡数据拟合项和平滑项的权重参数。
- tau:控制模式的时间局部性和频率局部性之间权衡的时间步参数。
- K:要分解的模式数量。
- DC:是否包括直流(趋势)分量在分解中的标志。
- init:模式的初始化方法。
- tol:用于确定算法收敛的容差值。
- draw:是否绘制模式的标志。
返回:
- df_vmd:包含 VMD 模式的 DataFrame,每个模式作为列。
"""
# 执行 VMD 分解
imfs_vmd, imfs_hat, omega = VMD(series, alpha, tau, K, DC, init, tol)
# 将 VMD 模式转换为 DataFrame
df_vmd = pd.DataFrame(imfs_vmd.T)
df_vmd.columns = ['imf'+str(i) for i in range(K)]
return df_vmd
2.cnn-lstm
代码如下(示例):
model = Sequential() # 创建Sequential模型。
model.add(LSTM(128, input_shape=(trainX.shape[1], trainX.shape[2]), return_sequences=True)) # 添加LSTM层,指定输入形状和输出形状。
model.add(Conv1D(filters=512, kernel_size=1, activation='relu', input_shape=(trainX.shape[1], trainX.shape[2]))) # 添加一维卷积层。
model.add(MaxPooling1D(pool_size=1)) # 添加最大池化层。
model.add(Dropout(0.2)) # 添加Dropout层,用于正则化。
model.add(Activation('relu')) # 添加激活函数层。
model.add(Flatten()) # 添加扁平化层。
model.add(Dense(1)) # 添加全连接层。
model.compile(loss='mse', optimizer='adam') # 编译模型,指定损失函数、优化器和评估指标。
model.fit(trainX, y_train, epochs=100, batch_size=32, verbose=1, validation_split=0.1) # 训练模型。
总结
完结,撒花!
文章来源:https://blog.csdn.net/qq_43128256/article/details/135693077
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RK3568驱动指南|第九篇 设备模型-第111章 platform总线注册驱动流程实例分析实验
- 正则表达式、文件访问(Python实现)
- 数据管理系统-week6-结构化查询语言(SQL)简介
- 【算法分析与设计】二叉树的层序遍历
- JavaScript实现网页全屏
- 【2023年】一文掌握:吐血记录我用GPT等AI模型做底层数据支持一整年踩的坑 和 解决办法!
- 计算机组成原理第4章-(存储器)【上】
- RDD 缓存 和 Checkpoint
- Google Breakpad使用方法
- 【机器学习】scikit-learn机器学习中随机数种子的应用与重现