众安保险实习Java一面
说一下事务的ACID属性
原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。
一致性(Consistency):事务按照预期生效,数据的状态是预期的状态
隔离性(Isolation):事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability):事务一旦被提交,它对数据库中数据的改变就是永久性的
说一下mysql中两种字符串char和varchar的不同
两种类型介绍
CHAR(M) 为固定长度字符串。M 表示列的长度,范围是 0~255 个字符。会自动删除插入数据的尾部空格。MyISAM 存储引擎推荐使用。
例如:CHAR(4) 定义了一个固定长度的字符串列,包含的字符个数最大为 4。当检索到 CHAR 值时,尾部的空格将被删除。
VARCHAR(M)是长度可变的字符串,M 表示最大列的长度,M 的范围是 0~65535。不会删除尾部空格。VARCHAR 的最大实际长度由最长的行的大小和使用的字符集确定,而实际占用的空间为字符串的实际长度加 1。InnoDB存储引擎推荐使用。
例如:VARCHAR(50) 定义了一个最大长度为 50 的字符串,如果插入的字符串只有 10 个字符,则实际存储的字符串为 10 个字符和一个字符串结束字符。VARCHAR 在值保存和检索时尾部的空格仍保留。
存储引擎对于选择 CHAR 和VARCHAR 的影响:
对于 MyISAM 存储引擎,最好使用固定长度的数据列代替可变长度的数据列。这样可以使整个表静态化,从而使数据检索更快,用空间换时间。
对于 InnoDB 存储引擎,最好使用可变长度的数据列,因为 InnoDB 数据表的存储格式不分固定长度和可变长度,因此使用 CHAR 不一定比使用 VARCHAR 更好,但由于 VARCHAR 是按照实际的长度存储,比较节省空间,所以对磁盘 I/O 和数据存储总量比较好。
TEXT 类型
TEXT 列保存非二进制字符串,如文章内容、评论等。当保存或查询 TEXT 列的值时,不删除尾部空格。
TEXT 类型分为 4 种:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。不同的 TEXT 类型的存储空间和数据长度不同。
TINYTEXT 表示长度为 255(28-1)字符的 TEXT 列。
TEXT 表示长度为 65535(216-1)字符的 TEXT 列。
MEDIUMTEXT 表示长度为 16777215(224-1)字符的 TEXT 列。
LONGTEXT 表示长度为 4294967295 或 4GB(232-1)字符的 TEXT 列。
讲一下java的IO模型
IO模型分为三种BIO【同步阻塞IO】、NIO【同步非阻塞IO】、AIO【异步非阻塞IO】。
首先可以先简单地体会一下三种IO模型的情景:假设你需要等待开水的煮开: 1. 同步阻塞:你蹲在开水壶旁边,什么都不做,等着开水的煮开。 2. 同步非阻塞:你跑去看书学习,隔一段时间来看看开水是否煮开。 3. 异步非阻塞:你跑去看书学习,当开水煮开的时候会发出响声,听到响声后你再回来。
BIO:
在BIO模式下,数据的写入和读取都必须阻塞在一个线程中执行,在写入完成或读取完成前,线程阻塞。
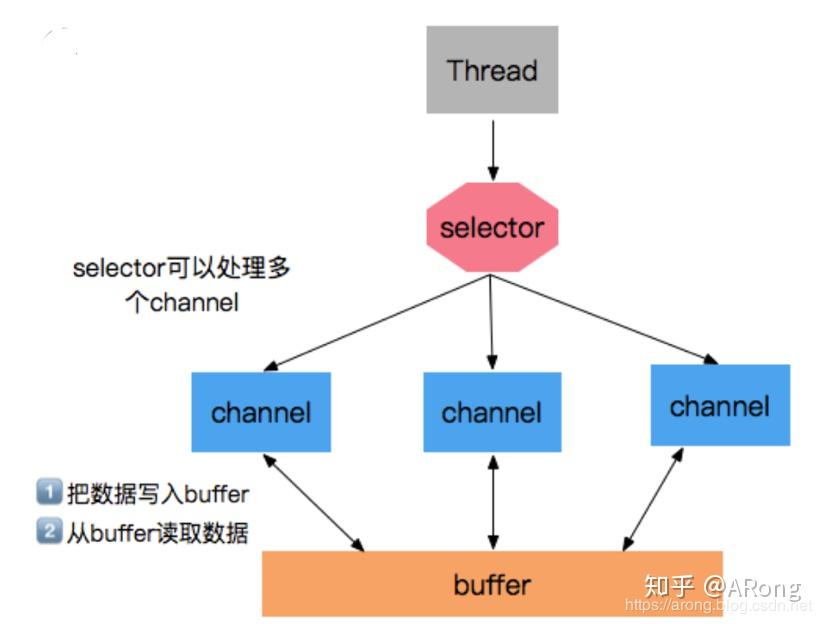
NIO:
NIO相对于BIO来说出现了几个核心的组件,分别是 Selector(选择器) 、 Channle(通道) 和 Buffer(缓冲区)
1.Buffer
缓冲区的出现导致了NIO和BIO的不同:读数据时可以先读一部分到缓冲区中,然后处理其他事情;写数据时可以先写一部分到缓冲区中,然后处理其他事情。读和写操作可以不再持续,所以不会阻塞。当缓冲区满后才会将其放入真正地读/写。
2.Channel
NIO的所有IO操作都从Channle开始: - 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。 - 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
3.Selector
选择器可以让单个线程处理多个通道,达到复用的目的。
AIO:
主要基于事件和回调机制来实现异步处理,在IO操作已经完成后,再给线程发出通知。因此AIO是不会阻塞的,此时我们的业务逻辑将变成一个回调函数,等待IO操作完成后,由系统自动触发。
说一下Java的基本数据类型
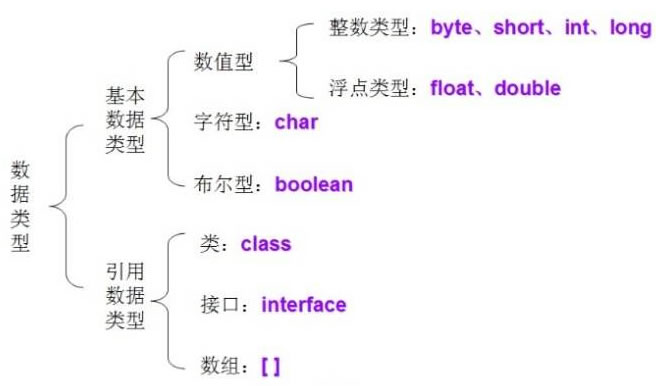
基本数据类型包括 boolean(布尔型)、float(单精度浮点型)、char(字符型)、byte(字节型)、short(短整型)、int(整型)、long(长整型)和 double (双精度浮点型)
引用数据类型建立在基本数据类型的基础上,包括数组、类和接口
说一下了解的分布式组件有哪些
Eureka:服务架构的注册中心,专门负责服务的注册和发现;
Dubbo:做服务地址的管理、服务的注册与发现、服务监控等
Nacos:快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nigix:高性能Web容器
MQ:分布式消息中间件
Zookeeper:服务注册中心、负载均衡、分布式协调、master选举
说一下list的相关类以及如何使用
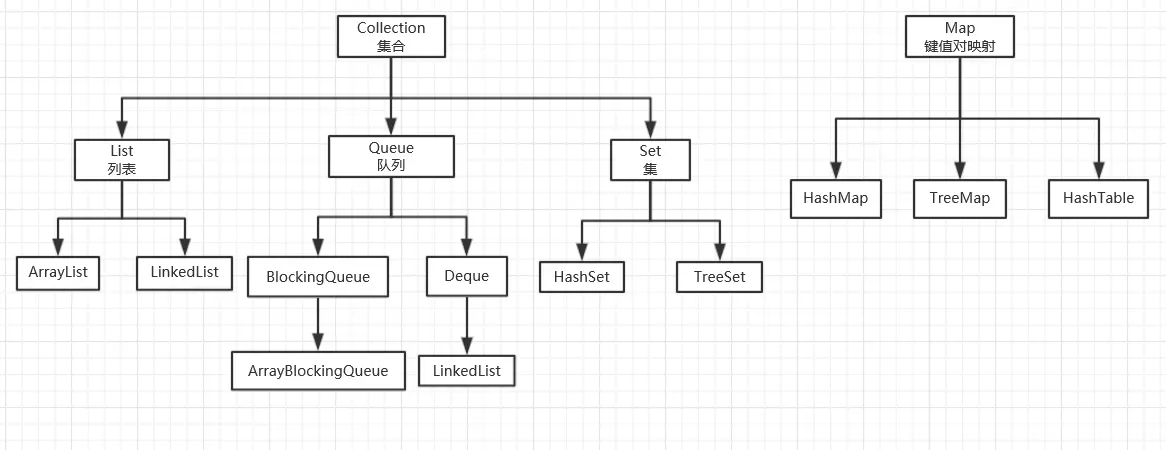
在Collection中,List集合是有序的,开发者可对其中每个元素的插入位置进行精确地控制,可以通过索引来访问元素,遍历元素。
在List集合中,我们常用到ArrayList和LinkedList这两个类。
1.ArrayList
其中,ArrayList底层通过数组实现,随着元素的增加而动态扩容。而LinkedList底层通过链表来实现,随着元素的增加不断向链表的后端增加节点。
ArrayList是Java集合框架中使用最多的一个类,是一个数组队列,线程不安全集合。
它继承于AbstractList,实现了List, RandomAccess, Cloneable, Serializable接口。
(1)ArrayList实现List,得到了List集合框架基础功能;
(2)ArrayList实现RandomAccess,获得了快速随机访问存储元素的功能,RandomAccess是一个标记接口,没有任何方法;
(3)ArrayList实现Cloneable,得到了clone()方法,可以实现克隆功能;
(4)ArrayList实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
ArrayList线程不安全原因:
在add过程中会经过两个步骤:1.判断elementData数组容量是否满足需求。2.在elementData对应位置上设置值
那么可能出现一种情况,当此时Arraylist的元素数量为其容量-1时,两个线程都想加入一个元素,在判断是否扩容的时候都判定不需要扩容,然后其中一个线程写入数据,元素数量++,另一个元素再写入的时候发现数组越界了
2.LinkedList
LinkedList是一个双向链表,每一个节点都拥有指向前后节点的引用。相比于ArrayList来说,LinkedList的随机访问效率更低。
它继承AbstractSequentialList,实现了List, Deque, Cloneable, Serializable接口。
(1)LinkedList实现List,得到了List集合框架基础功能;
(2)LinkedList实现Deque,Deque 是一个双向队列,也就是既可以先入先出,又可以先入后出,说简单些就是既可以在头部添加元素,也可以在尾部添加元素;
(3)LinkedList实现Cloneable,得到了clone()方法,可以实现克隆功能;
(4)LinkedList实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
hashmap是线程安全的吗?如何让他变安全?
他说线程不安全的,原因:
首先介绍他的扩容过程:HashMap的扩容主要分为两步:
1.扩容
创建一个新的Entry空数组,长度是原数组的2倍
2.ReHash
遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
让我们回顾一下Hash公式:
index = HashCode(Key) & (Length - 1)
当原数组长度为8时,Hash运算是和111B做与运算;新数组长度为16,Hash运算是和1111B做与运算。Hash结果显然不同。
在多线程的环境下扩容可能出现环形依赖。
使其变安全的方法:
1.替换成Hashtable,Hashtable通过对整个表上锁实现线程安全,因此效率比较低
2.使用Collections类的synchronizedMap方法包装一下。方法如下:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) 返回由指定映射支持的同步(线程安全的)映射
3.使用ConcurrentHashMap,它使用分段锁来保证线程安全
作者:肖宜
链接:众安Java一面_牛客网
来源:牛客网
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!