牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于YOLOv7开发构建公共场景下未牵绳遛狗检测识别系统
遛狗是每天要打卡的事情,狗狗生性活泼爱动,一天不遛就浑身难受,遛狗最重要的就是要拴绳了,牵紧文明绳是养犬人的必修课。外出遛狗时,主人手上的牵引绳更多是狗狗生命健康的一道重要屏障。每天的社区生活中,相信大家都会或多或少的在路上遇上一些遛狗的人不讲文明不讲武德,出门就是习惯性的不牵绳子遛狗,对于自己不熟悉的狗狗来说我们自然是害怕的,频频报道的狗咬人的事件也是层出不穷,,“狗狗性格温顺不会咬人的”这一类所谓的说辞不是放纵不牵绳子的理由。

前文我们已经进行了相应了开发实践感兴趣的话可以自行移步阅读:
《牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于DETR(DEtection TRansformer)开发构建公共场景下未牵绳遛狗检测识别系统》
《牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于YOLOv3开发构建公共场景下未牵绳遛狗检测识别系统》
《牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于YOLOv4开发构建公共场景下未牵绳遛狗检测识别系统》
《牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于YOLOv5开发构建公共场景下未牵绳遛狗检测识别系统》
《牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于YOLOv6开发构建公共场景下未牵绳遛狗检测识别系统》
对于此类的现象是否能够从技术的角度来进行思考甚至是干预呢?我想理论上来说也是可行的,本文的主要目的就是站在不牵绳遛狗这个大背景下探索基于技术手段来分析对此类行为干预的可行性,这里主要是基于YOLOv7开发构建对应的目标检测模型,我们的设计初衷就是考虑未来这样的技术手段能够结合路边、河道、社区、门口等等的可用的视频摄像头,对于画面中出现的遛狗目标对象进行实时的智能计算分析,如果发现问题就可以通过语音播报提醒,如果还是不加改正就可以将当前的时段视频发送到相关的部门来跟进处理,当然了,这些比较偏向业务应用层面不是我们开发者所能决定的,这里主要是结合我们的所见所想来开发构建实践性质的项目。
首先看下实例效果:

接下来简单看下实例数据集:

YOLOv7是 YOLO 系列最新推出的YOLO 结构,在 5 帧/秒到 160 帧/秒范围内,其速度和精度都超过了大部分已知的目标检测器,在 GPU V100 已知的 30 帧/秒以上的实时目标检测器中,YOLOv7 的准确率最高。根据代码运行环境的不同(边缘 GPU、普通 GPU 和云 GPU),YOLOv7 设置了三种基本模型,分别称为 YOLOv7-tiny、YOLOv7和 YOLOv7-W6。相比于 YOLO 系列其他网络 模 型 ,YOLOv7 的 检 测 思 路 与YOLOv4、YOLOv5相似,YOLOv7 网络主要包含了 Input(输入)、Backbone(骨干网络)、Neck(颈部)、Head(头部)这四个部分。首先,图片经过输入部分数据增强等一系列操作进行预处理后,被送入主干网,主干网部分对处理后的图片提取特征;随后,提取到的特征经过 Neck 模块特征融合处理得到大、中、小三种尺寸的特征;最终,融合后的特征被送入检测头,经过检测之后输出得到结果。
YOLOv7 网络模型的主干网部分主要由卷积、E-ELAN 模块、MPConv 模块以及SPPCSPC 模块构建而成 。在 Neck 模块,YOLOv7 与 YOLOv5 网络相同,也采用了传统的 PAFPN 结构。FPN是YoloV7的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV7里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。Head检测头部分,YOLOv7 选用了表示大、中、小三种目标尺寸的 IDetect 检测头,RepConv模块在训练和推理时结构具有一定的区别。
这里主要是选择了yolov7-tiny和yolov7这两款不同参数量级的模型来进行开发训练,训练数据配置文件如下:
# txt path
train: ./dataset/images/train
val: ./dataset/images/test
test: ./dataset/images/test
# number of classes
nc: 2
# class names
names: ['dog', 'rope']
在实验阶段保持完全相同的参数设置,等待全部训练完成之后来从多个指标的维度来进行综合的对比分析。
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。对于每个阈值,计算相应的精确率和召回率。将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。

【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
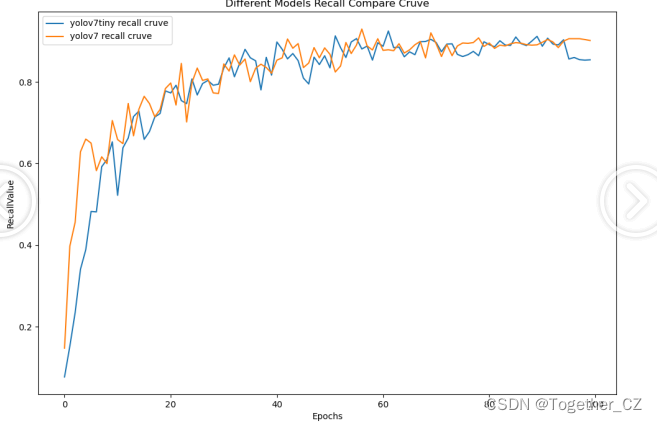
 【Recall曲线】
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
【loss曲线】

从结果对比来看:tiny系列的模型没有被yolov7拉开明显的差距,虽然整体评测效果来说yolov7要优于tiny模型,但是参数量也要高出不少,考虑到cpu推理的时效性,最终决定线上使用tiny系列的模型。
接下来以tiny系列模型为基准,看下详细的结果信息:
【混淆矩阵】

【训练可视化】

【Batch实例】

离线推理实例如下:

感兴趣的话都可以自行动手尝试下!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 前端性能优化之数据存取,存储以及缓存技术
- 位运算的高频算法题(算法村第十一关白银挑战)
- 百亿大模型在GTX1060上的高效运行优化
- c++时间 作业
- alma linux dnf简易使用指南
- 关于java的instanceof类型转换
- 中国电子学会2022年3 月份青少年软件编程Scratch图形化等级考试试卷一级真题(含答案见文章最下方)
- 策略模式学习
- 2010年中国生态系统服务空间数据集
- AT372-6P BDS/GNSS 单频 RTK 模块 规格书基本信息 亿胜盈科