人类行为动作数据集大合集
最近收集了一大波关于人类行为动作的数据集,主要包括:动作识别、行为识别、活动预测、动作行为分类等数据集。废话不多说,接下来就给大家介绍这些数据集!!
1、用于自动视频编辑的视频Blooper数据集
用于自动视频编辑的视频Blooper数据集
数据说明:
根据网上的消息,基本的视频编辑每分钟需要30分钟到一个小时。这就不鼓励用户制作周期性的内容。目前,自动视频编辑仅限于视频增强和简单的机制,如沉默或鼓掌检测已被应用在商业工具。为了有更智能的探测器,我们需要识别复杂的动作,如bloopers。失误是指一个人在屏慕上犯的错误。独白是一个完美的设置为漏洞检测,因为固定的条件。独白包括屏幕上的一个人和固定的摄像机位置。在这段视频中,我们收集了YouTube上的视频,并将简短的视频片段分成了bloper和no bloper视频剪辑。这可以帮助程序员训练能够在全长视频中检测错误的模型。
视频数量:600视频
时间长度:每个视频剪辑1到3秒之间
批次:训练、验证和测试批次
训练:464个视频
测试:66个视频
验证:66个视频
分类:2个分类
数据查看地址:https://www.dilitanxianjia.com/14224/

2、包含通常执行的人类操作的图像数据集
包含通常执行的人类操作的数据集
数据说明:
该数据集是一个结构化的数据集,分为训练和测试,每个包含15个类。这些课程是打电话、鼓堂、骑自行车、跳舞、喝酒、吃饭、打架、拥抱、大笑、听音乐、跑步、坐着、睡觉、发短信和使用笔记本电脑。总共有12600幅图像,分割率为85-15%,分别用于训练和测试。
这个数据集的目的是通过计算机来识别人的行为。它不可能包括所有的行为。因此,只提供了15种常规行动。
数据查看地址:https://www.dilitanxianjia.com/14218/

3、识别图像中行走动作预测数据集
识别图像中的视图后预测行走的动作数据集
数据说明:
问题描述:
而具有GPS功能的设备可以引导您在街道或道路上的路径。这些设备的使用是有限的,因为这些不能帮助在走彻底的封闭空间,如房间等。从而限制盲人在封闭空间内行走。
我们提出了一个想法来模拟第一个人走在房间里出来的房间或封闭的空间一样,每当任何人看到一堵墙在他面前,他向右或向左移动和微调他的方向,走出房间,避免墙壁碰撞。所以我们收集了一些数据来引导一个人,尤其是盲人走出房门。典型的工作流程包括以下方式的计算机视觉方法:
第一人称步行模拟器的数据是在游戏环境中收集的,在这个环境中,房间的地图被创建,图像被捕获,并被前、左、右的类标记为步行。通常人类行走是比较复杂的,但我们在这个阶段只收集了三种作用方式。目的是预测走出房间的方向。
内容:
一个人首先认识到在他面前的观点,然后决定一个行动,采取步伐,在前进,侧身,左,右或更复杂的运动。在数据收集阶段也是这样做的,即我们首先捕获图像,如果代理可以向前移动,则标记为前进,如果他需要右转走出门/房间,则标记为右转。(本数据约有1710个文件)
数据查看地址:https://www.dilitanxianjia.com/14214/

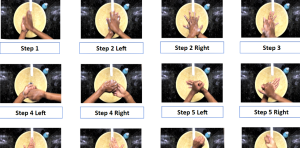
4、洗手图像数据集
洗手数据集
数据说明:
洗手数据集包括292个单独的洗手视频(每个洗手有12个步骤,总共3504个片段),在不同的环境中,以提供尽可能多的差异。方差对于确保模型的可靠性和可在多个环境中工作非常重要。
各种参数为:
- 照明
- 背景
- 源摄像机位置
- 视野
- 洗手的个人
之所以这样做,是因为Hand Wash Dataset旨在模拟动作识别解决方案的潜在应用的现实世界约束,例如:固定摄像头位置.实时反馈、变化照明、静态背景,并应用于特定领域的细粒度动作任务。下一步是确定程序中涉及的每一个步骤。因此,世界卫生组织最初规定的7个步骤被进一步分解为12个行动,这些行动考虑到了一个人洗手时可能采取的每一个行动。1. Step 1
- Step 2 Left
- Step 2 Right
- Step 3
- Step 4 Left
- Step 4 Right
- Step 5 Left
- Step 5 Right
- Step 6 Left
- Step 6 Right
- Step 7 Left
- Step 7 Right
数据查看地址:https://www.dilitanxianjia.com/14211/
5、人类行为和情感识别数据集
人类行为和情感识别数据集
数据说明:
这个独特的数据集包括动作和情绪类别,为开发能够从视觉数据中识别这两种类型信息的机器学习模型提供7宝贵的资源。从单个数据源中提取多个输出的能力在使用多个传感器或数据源可能具有挑战性或不切实际的实际设置中特别有吸引力。利用先进的计算机视觉技术,这种方法有可能为理解人类行为和开发能够适应人类需求的智能系统打开新的机会。(本数据约有957个文件)
数据查看地址:https://www.dilitanxianjia.com/14208/

6、11个类别的人类动作识别图像数据集
UCF的11个类别的动作识别数据集
数据说明:
UCF11数据集,也被称为YouTube动作数据集,封装了1160个视频,分为11个不同的动作类。由于摄像机的运动、物体的外观和姿态、物体的尺度、视点、杂乱的背景和视频剪辑固有的光照条件的变化,数据集被设计成一个挑战。
数据集包括以下11个行动类别:
1.篮球投篮
2.自行车/骑自行车
3潜水
4.高尔夫挥杆
5.骑马
6.足球杂耍
7.动
8.网球摇摆
9.蹦床跳跃
10排球扣球
11.与狗散步
数据查看地址:https://www.dilitanxianjia.com/14202/
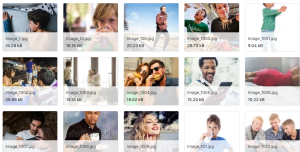
7、人类动作识别(HAR)数据集
人类动作识别(HAR)数据集
数据说明:
该数据集包含了15种不同的人类活动。大约12k+标签图像,包括验证图像。
- 每个图像只有一个人类活动类别,并保存在标签类的单独文件夹中
- 人类动作识别(HAR)旨在了解人类的行为,并为每个动作分配一个标签。它有着广泛的应用,因此在计算机视觉领域受到越来越多的关注。人类的行为可以使用各种数据模式来表示,如RGB、骨骼、深度、红外线、点云、事件流、音频、加速、、雷达和WiFi信号,这些数据模式编码了不同来源的有用而独特的信息,并根据应用场景具有不同的优势。
- 因此,许多现有的作品试图调查不同类型的方法,HAR使用各种模式。
- 可使用CNN建立一个图像分类模型,对人类正在进行的活动进行分类。
- 数据查看地址:https://www.dilitanxianjia.com/14199/
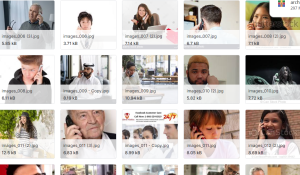
8、15类人类动作图像数据集
人类动作数据集
数据说明:
人体动作检测数据集包含15个类,每个类有1000幅图像用于训练,200幅图像用于测试.
班(类别)
- calling
- clapping
- cycling
- dancing
- drinking
- eating
- fighting
- hugging
- laughing
- listening to music
- running
- sitting
- sleeping
- texting
- using laptop
数据查看地址:https://www.dilitanxianjia.com/14196/
9、人体动作检测、人工智能分类、计算机视觉数据集
人体动作检测人工智能分类计算机视觉数据集
数据说明:
此数据集为一个人工智能CNN软件,可以检测和分类人类的动作。训练了9个现成的模型,并在软件中添加了1个创建的36层CNN人工智能算法(模型)。为了使代码具有指导性和可理解性,在笔记本标题的帮助下解释了代码块。(本数据集共有18K个文件)
数据查看地址:https://www.dilitanxianjia.com/14193/

10、UCFYouTube行为视频数据集
UCFYouTube行动数据集
数据说明:
UCF11数据集,以前称为YouTube动作数据集,是一个全面的1160个视频的集合,分为11个不同的动作类。所代表的行动包括:
1.篮球投篮
2.自行车/骑自行车
3.潜水
4.高尔夫挥杆
5.骑马
6.足球杂耍
7.摆动
8网球摆动
9.蹦床
10.排球扣球
11.和狗一起散步
数据查看地址:https://www.dilitanxianjia.com/14190/

11、视频动作识别视频数据集
UCF101-动作识别数据集
数据说明:
UCF101数据集是一个广泛认可和广泛使用的视频动作识别基准。对于希望开发和评估动作识别模型的研究人数据科学家和机器学习爱好者来说,这是一个非常宝贵的资源。该数据集包括101个动作类别的多样化集,涵盖了从体育和舞蹈到日常行动等广泛的人类活动。
- 大规模数据集:UCF101包含超过13000个视频片段,使其成为训练和测试动作识别模型的重要数据集。
- 不同的行动类别:数据集包含了广泛的人类行动,确保它适用于各种现实世界的应用。·真实世界的视频数据: UCF101中的视频是从YouTube上收集的,这意味着它们包含了真实世界中灯光、背景和摄像机角度的变化。
- 时间信息:每个视频剪辑都有一个代表动作类别的标签,允许训练模型,可以理解和分类视频数据中的时间模式。
。人体姿势和活动识别:UCF101是训练模型识别和分类人体活动和姿势的宝贵工具。这对于监控、机器人和体育分析等应用至关重要。拆分数据集UCF101提供预定义的训练和测试拆分,促进公平和一致的模型评估。基准性能:数据集包括各种动作识别算法的基准性能结果,可以很容易地比较新模型的性能。
数据查看地址:https://www.dilitanxianjia.com/14187/

12、三维人体动作识别数据集
三维人体动作识别数据集
数据说明:
该数据集包含11个动作进行的7名男性和5名女性受试者的范围23-30岁名老年人除外。所有受试者进行5个重复的每个动作,产生约660个动作序列,对应于约82分钟的总记录时间。此外,已经记录了一个T-pose为每个主题,可用于骨架提取和背景数据带和不带在一些活动中使用的椅子)。图1显示了前置摄像头执行的所有操作的快照以及从Kinect数据中提取的相应点云。指定的一组行动包括以下内容: (1) 上肢和下肢都有运动的动作,例如,原地跳跃,跳跃千斤顶,投掷等, (2)上肢有高动力的动作,如挥手、拍手等。以及(3)下肢具有高动力性的动作,例如,坐下、站起来。在每次录制之前,受试者都得到了执行什么动作的指示,但是没有给出具体的细节,应该如何执行的动作(即,性能风格或速度)。因此,受试者在执行某些动作时融入了不同的风格(例如,出拳、投掷》。图2显示了每个摄像机集群的参考摄像机和两个Kinect摄像机的投掷动作快照。该图显示了与单一视角相比,从多视角和深度观测中可以获得的信息量。
数据查看地址:https://www.dilitanxianjia.com/14184/

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [Linux技术]du_命令可以像find_命令那样列出最大的文件吗
- Redis:原理速成+项目实战——Redis常见命令(数据结构、常见命令总结)
- 外包做了5个月,技术退步一大半了。。。
- 老师的课堂行为包括什么内容
- 深度数据恢复,3个有效方法要掌握!
- 学生党有必要买台灯吗?央视公认最好的护眼灯
- html背景图片的使用以及解释
- STL总结
- Kafka为什么在消息积压时不能直接通过消费者水平扩容来提升消费速度?
- CSS 一行三列布局,可换行(含grid网格布局、flex弹性布局/inline-block布局 + 伪类选择器)