数据库管理-第125期 融合vs专用(202301221)
数据库管理-第125期 融合vs专用(202301221)
最近参加的两场活动,一次是11月的SACC上海站(《向量数据库技术探索》专场),一次是上周六的《国产数据库共话未来趋势》主题活动,虽然二者讨论内容与范围有很大区别,但是关于是否需要专用向量数据库和时序数据量的讨论,确是一致的,即在一个特定的数据领域是否需要独立的专用类型数据库。我认为这需要从好几个方向考虑。
1 便捷性
其实很多时候吧,业务发展是需要数据库快速跟上的,这一点使用专用数据库的优势就显现出来了,数据库的定制化开发与单一功能的实现是可以快速实现的,确实可以很快支撑相关业务的发展。在传统数据库融合新功能,往往需要付出很大的努力,往往需要耗费较多的时间,很难实现敏捷上线。
2 性能
这时候又得说出专用数据库的另一个优势了,因为专注于一件事情不需要考虑其他过多的东西,在这个专用场景下往往都能发挥出较好的性能。这一点如果使用传统数据库融合新功能,特别是比较复杂的新功能,数据库没有做好相关研发优化的情况下,往往不能很好的支撑新功能的高性能实现。
回到传统数据库融合的方式来,如果能做到多种类型数据的统一存放统一查询,简化业务研发难度而且性能能够赶上专用数据库(或者能够快于使用专用数据库的架构场景),从SACC的反馈来看,很多业务方会毫不犹豫使用融合数据库。
3 架构
话又说回来,无论专用数据库再怎么厉害,有一件事情是绕不过去的,无论是向量数据还是时序数据抑或是其他类型的非关系型数据,最终产生价值都需要于传统数据做关联,使用专用数据库就会出现数据的多次流转的问题,多次在不同类型数据库之间的分步查询,会产生时间和网络上的更多损耗。另一方面,多一个数据层面的组件也会显著增加了整体数据架构层的复杂度,增加研发和维护的难度。这一点又是传统数据库融合功能的一些优势。
一些观点
- 薛首席在SACC说过:“平时外出,没有特别需求我会用手机拍照;但如果是婚纱照我会找影楼”。
- 熊灿灿上周在《国产数据库共话未来趋势》说:“把复杂留给数据库,把简单送给研发”
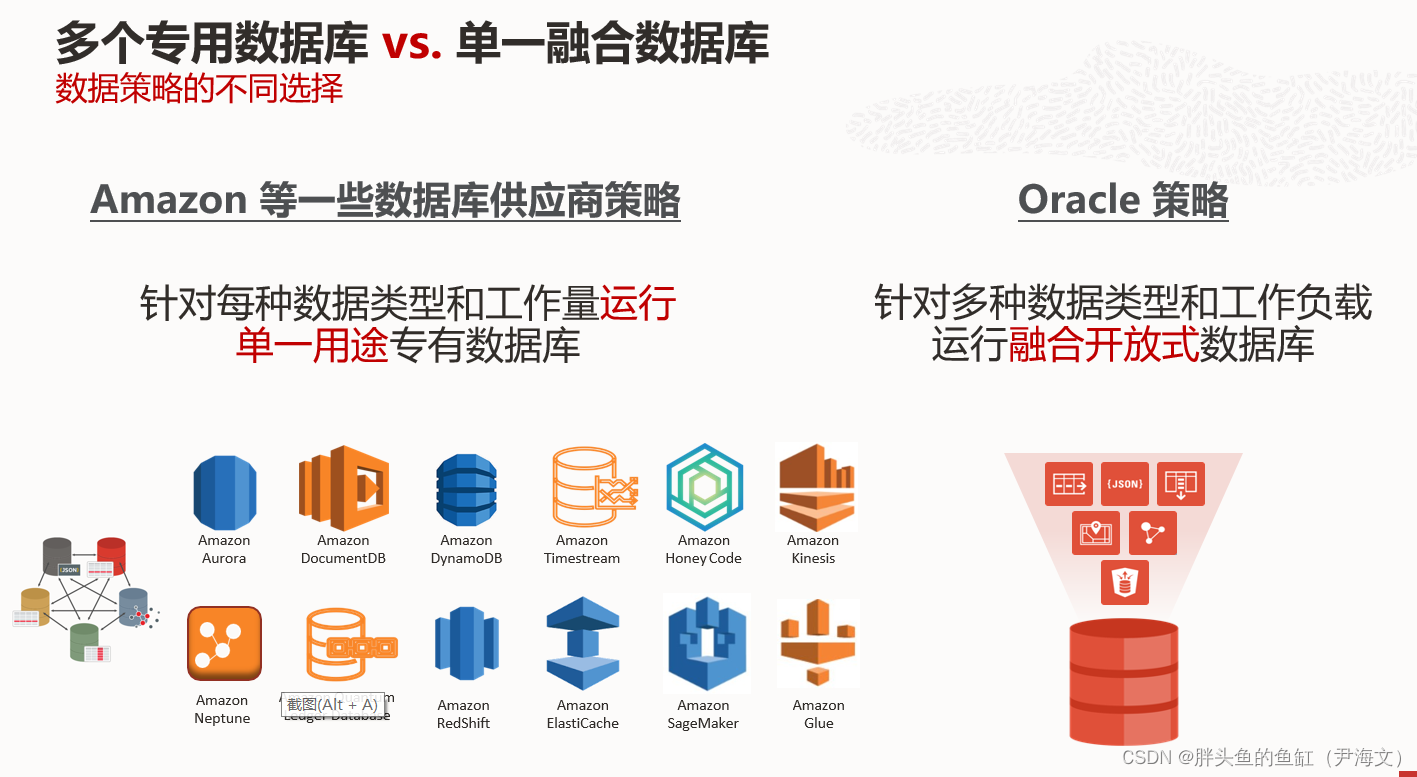
- AWS是针对每种数据类型和工作量运行单一用途的专有数据库
- Oracle是针对多种数据类型和所有工作负载运行融合开放式数据库
等等
我认为吧,还是得从业务场景、上线周期要求、数据量、业务量、性能要求、研发能力、运维能力、云上&云下等维度出发(感觉又说了一堆废话),来选择使用专用数据库还是融合数据库。
老规矩,不知道写了些啥。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python两个字典合并,两个list合并
- 《微信小程序开发从入门到实战》学习六十九
- 条款27:尽量少做转型动作
- 今日前端十个知识点——CSS篇(一)
- 运筹说 第45期丨多目标规划发展及其提出者—— Abraham Charnes和William W. Cooper
- 医院患者满意度调研的概念
- 产品分析 | 数据资产目录竞品分析
- 气动凝结水回收机组 浮球机械泵回收机组工作原理动画讲解介绍
- 【Python】函数
- P21 类神经网络训练不起来怎么办- 自动调整学习率 Adapative learning rate