书生·浦语大模型全链路开源体系(陈恺|上海人工智能实验室 青年科学家)-听课笔记
发布时间:2024年01月06日
-
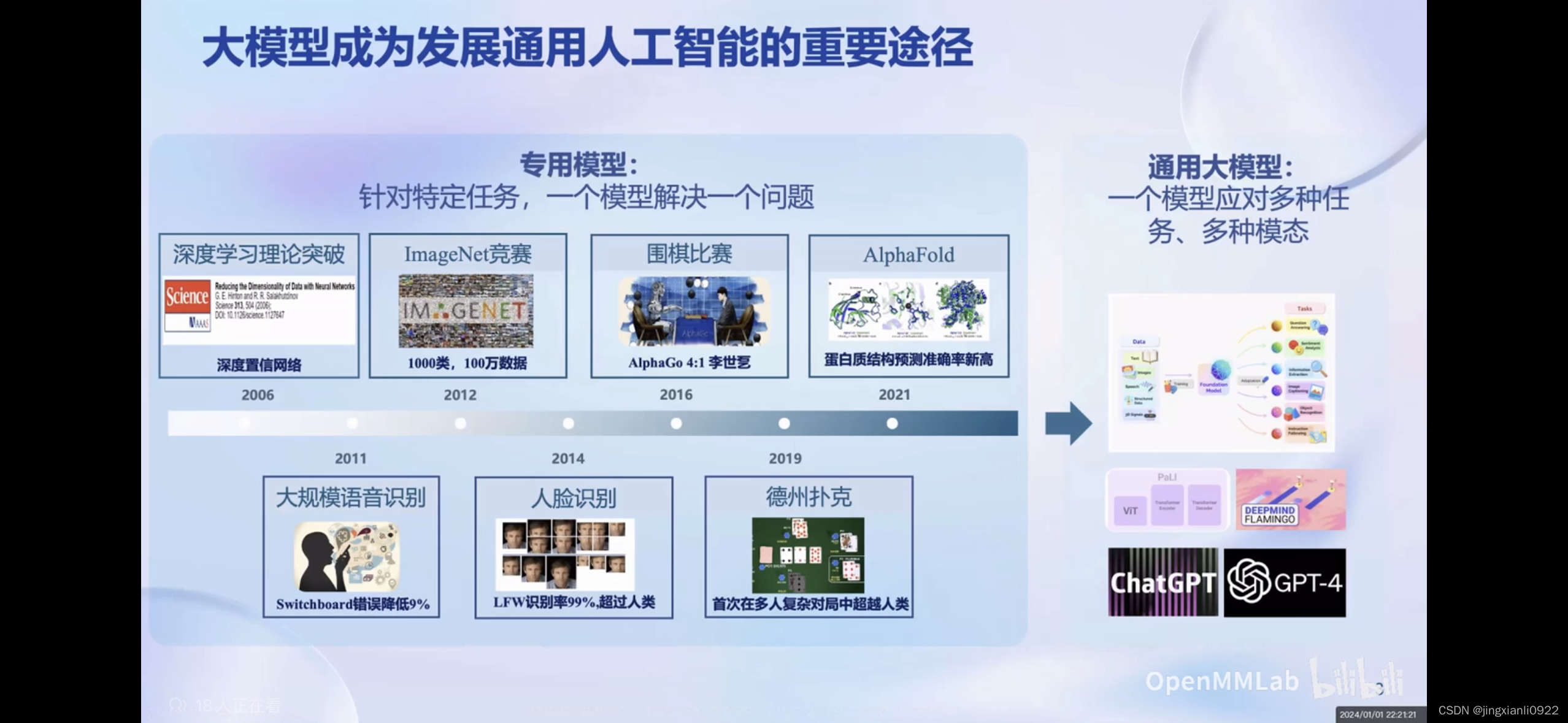
大模型重要性
大模型确实已成为发展通用人工智能(AGI)的重要途径。它们通过整合和处理大量数据,学习语言、图像、声音等多种模式的表示,以此来模拟人类的学习和思维方式。通过不断地学习和优化,这些模型能够在各种任务中表现出越来越高的智能水平,例如自然语言理解、图像识别、策略制定等。大模型的发展涉及到算法创新、计算资源的大规模部署、数据的高效管理等多个方面,是推动人工智能进步的关键因素之一。
书生-浦语大模型开源历程


书生·浦语大模型系列
1.轻量级:InternLM-7B
70亿模型参数
1000亿训练token数据
长语境能力,支持8K语境窗口长度
通用工具调用能力,多种工具调用模板
2.中量级:InternLM-20B
200亿模型参数,在模型能力与推理代价间取得平衡
采用深而窄的结果,降低推理计算量但提高推理能力
4K训练语境长度,推理时可外推至16K
3.重量级:1230亿模型参数,强大的性能
极强推理能力、全面的知识覆盖面、超级理解能力与对话能力
准确的API调用能力,可实现各类Agent
书生·浦语大模型性能评测
“书生·浦语”联合团队选取了20余项评测对其进行检验,其中包含全球最具影响力的四个综合性考试评测集:由伯克利加州大学等高校构建的多任务考试评测集MMLU;微软研究院推出的学科考试评测集AGIEval(含中国高考、司法考试及美国SAT、LSAT、GRE 和 GMAT等),AGIEval的19个评测大项中有9个大项是中国高考,通常也列为一个重要的评测子集AGIEval(GK);由上海交通大学、清华大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集C-Eval;以及由复旦大学研究团队构建的高考题目评测集Gaokao。




?
文章来源:https://blog.csdn.net/jasonjwl/article/details/135391538
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Python常用函数】一文让你彻底掌握Python中的numpy.append函数
- linux基础06—windows下打不开wsl的ubuntu的子系统
- 2023年12月电子学会Scratch图形化编程一级真题及答案
- secureCRT串口助手配置RS232和RS422
- 界面控件DevExpress .NET MAUI v23.1 - 发布一系列新组件
- 【PAT甲级】1175 Professional Ability Test
- 开发安全之:Path Manipulation
- React中简单实现路由守卫(主要演示其原理)
- 笨蛋学设计模式结构型模式-享元模式【13】
- WPF Icon矢量库 MahApps.Metro.IconPacks