当MySql有字段为null,索引是否会失效
发布时间:2024年01月17日
sql执行过程中,使用is null 或者is not null 理论上都会走索引,由于优化器的原因导致索引失效变成全表扫描,或者说是否使用索引和NULL值本身没有直接关系,和执行成本有关系。
数据行记录如何存储NULL值的?
InnoDB 提供了 4 种行格式
- Redundant:非紧凑格式,5.0 版本之前用的行格式,目前很少使用,
- Compact:紧凑格式,5.1 版本之后默认行格式,可以存储更多的数据
- Dynamic ,Compressed:和Compact类似,5.7 版本之后默认使用 Dynamic 行格式,在Compact基础上做了改进,基础设计原理没变
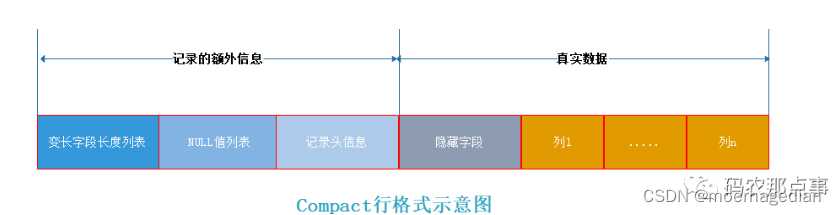
Compact的数据结构示意图
- 表中的列直接存储 NULL 值会比较浪费空间,所以 Compact 行格式把这些为 NULL 的列以逆序二进制位方式存储到 NULL值列表中。
- 二进制位的值为1时,代表该列的值为NULL。
- 二进制位的值为0时,代表该列的值不为NULL。
- NULL 值列表必须用整数个字节的位表示(1字节8位),如果使用的二进制位个数不足整数个字节,则在字节的高位补 0。如果不够(null字段超过8个),会再创建1字节,直到满足长度要求.
- 当数据表的字段都定义成 NOT NULL 的时候,这时候表里的行格式就不会有 NULL 值列表了,所以在设计数据库表的时候,通常都是建议将字段设置为 NOT NULL,这样可以节省至少1 字节的空间(NULL 值列表至少占用 1 字节空间)。
索引是如何存储NULL值的?
聚簇索引
聚簇索引本身是不允许为NULL,所以不用考虑
非聚簇索引
非聚簇索引是通过B+树的方式进行存储的,null值作为最小数看待,全部放在树的最左边,形成链表,如果获取is null的数据,可以从最左开始 直到找到记录不是null结束.
下面我们讨论NULL索引是否会失效?
决定is null或者is not null走不走索引取决于执行成本
- 读取二级索引的成本
- 将二级索引执行回表操作,也就是到聚簇索引中找到完成的用户记录操作所付出的成本。
例如:几乎所有数据都命中,都需要回表.这个时候,优化器会放弃索引,走效率更高全表扫描
文章来源:https://blog.csdn.net/moernagedian/article/details/135640065
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- (分享) 音乐软件Spotify-声破天8.9.4
- 家电补贴一站式服务平台的设计与实现-计算机毕业设计源码12305
- 深度学习预备知识-数据存储、数据预处理
- CAD VBA 导出cass扩展数据到excel
- buuctf-Misc 题目解答分解109-111
- 2.5 KERNEL FUNCTIONS AND THREADING
- Linux进程通信——system V进程间通信
- 初识UDS:基础知识篇
- 数据库-期末考前复习-第4章-数据库安全性
- 【C++】命名空间详解