[C#]Onnxruntime部署Chinese CLIP实现以文搜图以文找图功能
【官方框架地址】
https://github.com/OFA-Sys/Chinese-CLIP
【算法介绍】
在当今的大数据时代,文本信息处理已经成为了计算机科学领域的核心议题之一。为了高效地处理海量的文本数据,自然语言处理(NLP)技术应运而生。而在诸多NLP技术中,文本分割是一种基础且重要的任务。Chinese Clip算法正是在这样的背景下被提出,用于解决中文文本的分割问题。
Chinese Clip算法的主要目标是解决中文文本的词边界确定问题,即确定每个字符是属于哪个词。这看似简单,实则复杂。由于中文的书写系统与英文等字母文字存在显著差异,中文文本的词边界往往不是由空格等明显标识符来分隔,而是依赖于上下文和语境。因此,对于中文文本的词分割,需要深入理解语言的内在结构和语义信息。
Chinese Clip算法的核心思想是利用上下文信息来预测词边界。具体来说,该算法首先构建一个上下文模型,该模型能够捕获文本中相邻字符间的关系。然后,利用这个上下文模型对文本中的每个字符进行分类,判断其是否为词的边界。为了实现这一目标,Chinese Clip算法采用了一种深度学习的方法,特别是使用循环神经网络(RNN)和长短时记忆网络(LSTM)来构建上下文模型。这两种网络结构能够帮助算法捕获文本中的长期依赖关系,从而更准确地判断词边界。
在训练过程中,Chinese Clip算法采用了监督学习的方法。这意味着它需要大量的已标注数据来进行训练。这些标注数据包含了每个字符所属的词边界信息,使得算法能够学习到如何根据上下文信息预测词边界。为了提高模型的泛化能力,Chinese Clip算法还采用了诸如数据增强等技术,通过对原始数据进行各种变换来生成更多的训练数据。
除了核心的词边界预测任务外,Chinese Clip算法还可以用于其他相关的NLP任务。例如,它可以作为其他自然语言处理任务的基础模块,如分词、词性标注、命名实体识别等。通过将Chinese Clip算法与其他NLP技术相结合,可以实现更复杂、更高级的语言处理任务。
在性能方面,Chinese Clip算法展现出了优异的性能。与传统的基于规则或简单统计模型的词分割方法相比,Chinese Clip算法具有更高的准确率和更低的错误率。这主要归功于深度学习模型的强大表示能力和对上下文信息的有效捕获。
然而,尽管Chinese Clip算法在许多方面都表现出色,但它也存在一些局限性。例如,它依赖于大量的标注数据,这在实际应用中可能是一个挑战。此外,深度学习模型通常需要大量的计算资源和时间进行训练和推理,这可能会限制其在资源有限环境中的应用。
总的来说,Chinese Clip算法是一种有效的中文文本分割方法。通过利用深度学习技术,它能够准确地预测词边界,并为其他NLP任务提供有力的支持。虽然存在一些局限性,但其在解决中文文本分割问题上的表现仍值得肯定。随着技术的不断进步和应用场景的不断拓展,我们期待Chinese Clip算法在未来能够取得更大的突破和进步。
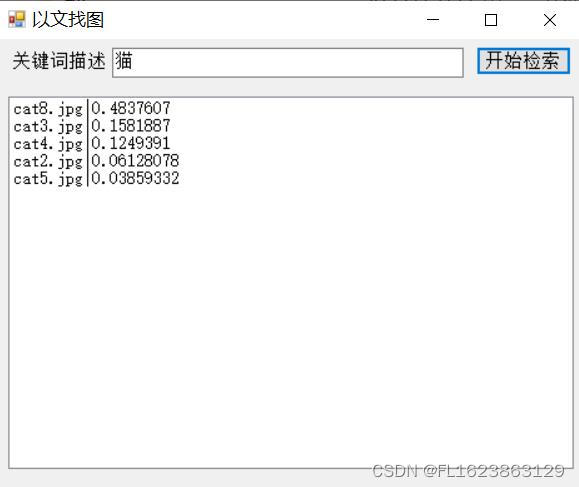
【效果展示】
【实现部分代码】
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespace FIRC
{
public partial class Form1 : Form
{
ClipManager ClipNet = new ClipManager();
float[] features;
string image_path = Application.StartupPath+"\\images";
public Form1()
{
InitializeComponent();
}
private void Form1_Load(object sender, EventArgs e)
{
ClipNet.LoadWeights(Application.StartupPath + "\\weights\\image_model.onnx", Application.StartupPath + "\\weights\\text_model.onnx", Application.StartupPath+"\\weights\\vocab.txt");
features = ClipNet.generate_imagedir_features(image_path);
}
private void button1_Click(object sender, EventArgs e)
{
if(string.IsNullOrEmpty(tb_keyword.Text))
{
return;
}
List<Dictionary<string, float>> top5Result = ClipNet.StartSearch(tb_keyword.Text, features);
listBox1.Items.Clear();
for(int i=0;i<top5Result.Count;i++)
{
foreach (var item in top5Result[i])
listBox1.Items.Add(Path.GetFileName(item.Key)+"|"+item.Value);
}
}
}
}
【视频演示】
https://www.bilibili.com/video/BV1NG411B7Co/
【源码下载】
【测试环境】
vs2019
opencvsharp4.8.0
onnxruntime1.16.3
使用框架:chinese Clip
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!