关于gltf模型格式文件的学习
目录
因为笔者自己在检测自己学习webgl的质量于是写一个webgl的小框架。
地址:webglWF: 这个是自己学习完毕《weblg编程指南》2遍之后,打算自己先封装一个2D的给予webgl的矿建。用于检验自己的学习质量。与提升自己的webgl的能力
遇见了gltf模型的加载问题。所以我会一边学习一边完善这篇文章
glTF模型
?gltf中各个字段的对用关系
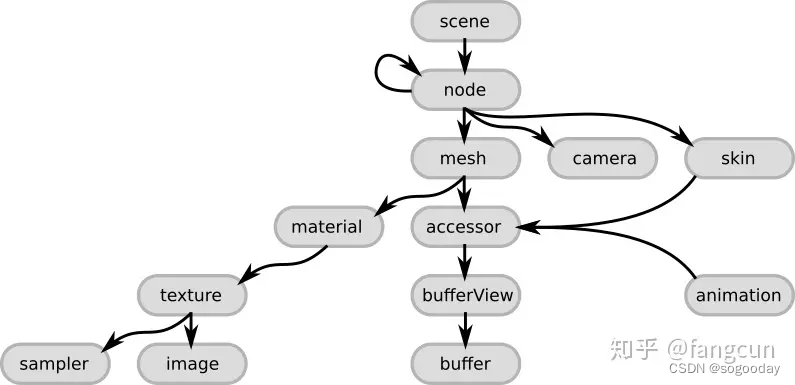
小黄鸭的gltf模型
{
"asset": { "generator": "COLLADA2GLTF", "version": "2.0" },
"scene": 0,
"scenes": [{ "nodes": [0] }],
"nodes": [
{ "children": [2, 1], "matrix": [0.009999999776482582, 0, 0, 0, 0, 0.009999999776482582, 0, 0, 0, 0, 0.009999999776482582, 0, 0, 0, 0, 1] },
{
"matrix": [
-0.7289686799049377, 0, -0.6845470666885376, 0, -0.4252049028873444, 0.7836934328079224, 0.4527972936630249, 0, 0.5364750623703003, 0.6211478114128113,
-0.571287989616394, 0, 400.1130065917969, 463.2640075683594, -431.0780334472656, 1
]
},
{ "mesh": 0 }
],
"meshes": [{ "primitives": [{ "attributes": { "NORMAL": 1, "POSITION": 2, "TEXCOORD_0": 3 }, "indices": 0, "mode": 4, "material": 0 }], "name": "LOD3spShape" }],
"accessors": [
{ "bufferView": 0, "byteOffset": 0, "componentType": 5123, "count": 12636, "max": [2398], "min": [0], "type": "SCALAR" },
{
"bufferView": 1,
"byteOffset": 0,
"componentType": 5126,
"count": 2399,
"max": [0.9995989799499512, 0.999580979347229, 0.9984359741210938],
"min": [-0.9990839958190918, -1, -0.9998319745063782],
"type": "VEC3"
},
{
"bufferView": 1,
"byteOffset": 28788,
"componentType": 5126,
"count": 2399,
"max": [96.17990112304688, 163.97000122070312, 53.92519760131836],
"min": [-69.29850006103516, 9.929369926452637, -61.32819747924805],
"type": "VEC3"
},
{
"bufferView": 2,
"byteOffset": 0,
"componentType": 5126,
"count": 2399,
"max": [0.9833459854125975, 0.9800369739532472],
"min": [0.026409000158309937, 0.01996302604675293],
"type": "VEC2"
}
],
"materials": [{ "pbrMetallicRoughness": { "baseColorTexture": { "index": 0 }, "metallicFactor": 0 }, "emissiveFactor": [0, 0, 0], "name": "blinn3-fx" }],
"textures": [{ "sampler": 0, "source": 0 }],
"images": [{ "uri": "https://gw.alipayobjects.com/zos/OasisHub/267000040/4580/DuckCM.png" }],
"samplers": [{ "magFilter": 9729, "minFilter": 9986, "wrapS": 10497, "wrapT": 10497 }],
"bufferViews": [
{ "buffer": 0, "byteOffset": 76768, "byteLength": 25272, "target": 34963 },
{ "buffer": 0, "byteOffset": 0, "byteLength": 57576, "byteStride": 12, "target": 34962 },
{ "buffer": 0, "byteOffset": 57576, "byteLength": 19192, "byteStride": 8, "target": 34962 }
],
"buffers": [{ "byteLength": 102040, "uri": "https://gw.alipayobjects.com/os/OasisHub/267000040/75/Duck0.bin" }]
}
字段分析
scene
在glTF中,"scene"字段用于指定默认的场景(scene)。一个glTF文件可以包含多个场景,每个场景可以包含多个节点(node),用于描述整个3D场景的内容和结构。
"scene"字段中包含一个整数值,表示默认场景的索引。当加载glTF文件时,渲染引擎会使用该索引来确定默认的场景,从而开始渲染整个3D场景。
通过指定默认场景,可以在包含多个场景的glTF文件中明确指定渲染引擎应该从哪个场景开始渲染,这有助于组织和管理复杂的3D场景结构。
文件中,入口字段
?"scene": 0,代表从
"scenes": [{ "nodes": [0] }],中获取第0个元素也就是
{ "nodes": [0] }nodes
此时的内容为nodes:0,也就是去
"nodes": [
{ "children": [2, 1], "matrix": [0.009999999776482582, 0, 0, 0, 0, 0.009999999776482582, 0, 0, 0, 0, 0.009999999776482582, 0, 0, 0, 0, 1] },
{
"matrix": [
-0.7289686799049377, 0, -0.6845470666885376, 0, -0.4252049028873444, 0.7836934328079224, 0.4527972936630249, 0, 0.5364750623703003, 0.6211478114128113,
-0.571287989616394, 0, 400.1130065917969, 463.2640075683594, -431.0780334472656, 1
]
},
{ "mesh": 0 }
],上述nodes的字段中找第0个元素
{ "children": [2, 1], "matrix": [0.009999999776482582, 0, 0, 0, 0, 0.009999999776482582, 0, 0, 0, 0, 0.009999999776482582, 0, 0, 0, 0, 1] },
?children[2,1]代表nodes[2]与nodes[1]。两个节点
"children": [2, 1] 表示当前节点的子节点。在这个例子中,子节点的索引分别为2和1,这意味着当前节点有两个子节点。
"matrix": [...] 表示了当前节点的变换矩阵。这个矩阵是一个4x4的矩阵,描述了节点的平移、旋转和缩放等变换信息。
综合起来,这段代码描述了一个节点,它有两个子节点,并且具有一个缩放变换。这些信息可以帮助构建出场景中的节点层次结构,以及节点的变换关系。
去哪里找children": [2, 1]中数据呢。当然是nodes字段自己,也就是紧跟着children下面的数据
{"matrix": [ -0.7289686799049377, 0, -0.6845470666885376, 0, -0.4252049028873444, 0.7836934328079224, 0.4527972936630249, 0, 0.5364750623703003, 0.6211478114128113, -0.571287989616394, 0, 400.1130065917969, 463.2640075683594, -431.0780334472656, 1]},
{ "mesh": 0 }在glTF中,每个节点(node)可以代表场景中的一个对象,例如网格、相机、灯光等。每个节点可以包含一些属性,例如变换矩阵、子节点、网格等。在上述数据中,node[1] 和 node[2] 分别代表两个节点,它们的内容可以按照以下方式理解:
node[1]:这个节点包含了一个变换矩阵,用于描述节点的平移、旋转和缩放信息。在您的数据中,node[1]的变换矩阵描述了一个复杂的变换,包括平移、旋转和缩放等信息。这个节点可能代表场景中的一个具体对象,例如一个网格模型。
node[2]:这个节点包含了一个指向网格的引用(mesh)。在您的数据中,node[2]包含了一个指向索引为0的网格的引用,表示这个节点使用了索引为0的网格。这个节点可能代表场景中的一个网格对象。
通过理解节点中的内容,可以构建出场景中的层次结构,描述场景中的对象之间的关系和属性。这有助于渲染引擎正确地呈现场景中的对象,并实现正确的变换和渲染效果。
?meshes
发现nodes[2]的内容是
{ "mesh": 0 }也就是去找meshes的字段
"meshes": [{ "primitives": [{ "attributes": { "NORMAL": 1, "POSITION": 2, "TEXCOORD_0": 3 }, "indices": 0, "mode": 4, "material": 0 }], "name": "LOD3spShape" }],
这段代码描述了一个网格(mesh),具体含义如下:
"primitives": 这是一个包含了网格的基本几何信息的数组。在这个例子中,只有一个primitive,表示这个网格是由一个基本几何构成的。
"attributes": 这个字段包含了描述网格顶点属性的信息。在这里,包含了"NORMAL"、"POSITION"和"TEXCOORD_0",分别表示法线、位置和纹理坐标等顶点属性的索引。这些索引对应了访问器(accessor)中的索引,用于获取实际的顶点数据。
"indices": 这个字段表示了描述网格索引的访问器(accessor)的索引。索引对应了访问器中描述网格索引数据的信息。
"mode": 这个字段表示了绘制网格的模式,比如4表示了以三角形扇的方式绘制网格。
"material": 这个字段表示了网格使用的材质的索引。索引对应了glTF中材质(material)的信息。
"name": 这是网格的名称,用于标识和区分不同的网格。
综合起来,这段代码描述了一个网格,包含了网格的基本几何信息、顶点属性、索引、绘制模式和材质等信息。这些信息可以帮助渲染引擎正确地呈现网格的外观和属性。
通过上述我们知道了
let mesh =?meshes[nodes[scenes[scene].nodes].children[0].mesh
primitives
"primitives"字段可以包含多个元素,每个元素描述一个网格的基本几何信息。
每个"primitives"数组中的元素包含了描述一个网格的基本几何信息,包括顶点属性、索引、绘制模式和材质等信息。这使得glTF能够描述复杂的网格结构,包括多个网格的属性和外观。
?这个信息基本也就是要绘制节点一全部信息了。
下面内容就是一个一个的去需按照对应的数据了,此节点包括顶点,法向量,贴图,绘制模式,material材质信息。
在上文中我们知道?primitives只有一个元素。所以我们只能获取primitives的0元素。如果是多个元素,此时我们需要一个一个去找对应的内容
attributes
在glTF中,"attributes"字段的值是一个包含了顶点属性索引的对象,每个属性对应一个访问器(accessor)的索引,用于获取实际的顶点数据。
"POSITION"、"NORMAL"和"TEXCOORD_0"分别代表了位置、法线和纹理坐标等顶点属性,而它们的值分别是对应访问器的索引,用于获取实际的顶点数据。
通过"attributes"字段,可以明确指定网格的顶点属性,帮助渲染引擎正确地呈现网格的外观和形状。
法线 let NORMAL =?meshes[mesh].primitives[0].attributes.NORMAL
顶点 let POSITION =?meshes[mesh].primitives[0].attributes.POSITION
贴图? let TEXCOORD_0 =?meshes[mesh].primitives[0].attributes.TEXCOORD_0
indices
在glTF中,"indices"字段用于指定网格的索引数据。索引数据描述了如何将顶点连接起来以构成三角形或其他图元。这些索引通常用于描述网格的拓扑结构,以便渲染引擎能够正确地绘制出网格的外观。
"indices"字段的值是一个访问器(accessor)的索引,该访问器包含了描述网格索引数据的信息,包括二进制数据的存储位置、数据类型等。通过"indices"字段,可以明确指定网格的索引数据,帮助渲染引擎正确地构建出网格的拓扑结构。?
?此时我们可以创建一个顶点做因的变量
顶点索引?let?indices =??accessors[meshes].primitives[0].indices
mode
"mode": 这个字段表示了绘制网格的模式,比如4表示了以三角形扇的方式绘制网格。
上述的问中mode标识要绘制的类型,下面是对应关系
/**
* 根据传入的mode返回对应的绘制方式名称
* @param {number} mode - 表示绘制方式的值
* @returns {string} - 对应的绘制方式名称,如果mode无效则返回"UNKNOWN"
*/
function getDrawModeName(mode) {
switch (mode) {
case 0:
return "POINTS";
case 1:
return "LINES";
case 2:
return "LINE_LOOP";
case 3:
return "LINE_STRIP";
case 4:
return "TRIANGLES";
case 5:
return "TRIANGLE_STRIP";
case 6:
return "TRIANGLE_FAN";
default:
return "UNKNOWN";
}
}material
"material": 这个字段表示了网格使用的材质的索引。索引对应了glTF中材质(material)的信息
此时此字段的数据需要去materials字段中需按照
accessors
在glTF中,"accessors"字段用于描述访问器(accessor),访问器是用于访问和解释二进制数据的对象。"accessors"字段包含了多个访问器的描述,每个访问器对应了一个包含了二进制数据的缓冲区视图(buffer view),并指定了如何解释这些二进制数据。
每个访问器包含了以下信息:
- "bufferView": 指定了访问器使用的缓冲区视图的索引,用于获取二进制数据。
- "byteOffset": 指定了访问器从缓冲区视图中的哪个字节开始读取数据。
- "componentType": 指定了访问器中每个组件的数据类型,比如浮点数、整数等。
- "count": 指定了访问器包含的元素数量。
- "type": 指定了访问器中每个元素的类型,比如标量(scalar)、矢量(vector)、矩阵(matrix)等。
- "max"和"min": 指定了访问器中数据的最大值和最小值,用于辅助渲染引擎进行优化和处理。
通过"accessors"字段,可以明确描述访问器的属性和数据结构,帮助渲染引擎正确地解释和处理二进制数据,从而呈现出正确的3D模型和场景
"accessors": [
{ "bufferView": 0, "byteOffset": 0, "componentType": 5123, "count": 12636, "max": [2398], "min": [0], "type": "SCALAR" },
{
"bufferView": 1,
"byteOffset": 0,
"componentType": 5126,
"count": 2399,
"max": [0.9995989799499512, 0.999580979347229, 0.9984359741210938],
"min": [-0.9990839958190918, -1, -0.9998319745063782],
"type": "VEC3"
},
{
"bufferView": 1,
"byteOffset": 28788,
"componentType": 5126,
"count": 2399,
"max": [96.17990112304688, 163.97000122070312, 53.92519760131836],
"min": [-69.29850006103516, 9.929369926452637, -61.32819747924805],
"type": "VEC3"
},
{
"bufferView": 2,
"byteOffset": 0,
"componentType": 5126,
"count": 2399,
"max": [0.9833459854125975, 0.9800369739532472],
"min": [0.026409000158309937, 0.01996302604675293],
"type": "VEC2"
}
],上面我们创建了4个变量
法线 let NORMAL =?meshes[mesh].primitives[0].attributes.NORMAL;
顶点 let POSITION =?meshes[mesh].primitives[0].attributes.POSITION;
贴图? let TEXCOORD_0 =?meshes[mesh].primitives[0].attributes.TEXCOORD_0;
顶点索引?let?indices =??meshes[mesh].primitives[0].indices;
上述的4个表变量都是指向accessors字段中的值。此时直接使用数组的形势去获取就好
法线 let NORMAL2 =?accessors[NORMAL];
顶点 let POSITION2 =?accessors[POSITION];
贴图? let TEXCOORD_02 =?accessors[TEXCOORD_0];
顶点索引?let?indices2 =??accessors[indices];
下文中二进制数据指得是buffers字段中得uri地址内容,这个一个二进制得.bin文件,里面储存了,上面4个变量得具体数值内容
"buffers": [{ "byteLength": 102040, "uri": "https://gw.alipayobjects.com/os/OasisHub/267000040/75/Duck0.bin" }]
这段代码描述了一个访问器(accessor),其中包含了对应于三维向量(VEC3)的顶点属性数据。各个字段的含义:
- "bufferView": 指定了访问器使用的缓冲区视图的索引,用于获取二进制数据。
- "byteOffset": 指定了访问器从缓冲区视图中的哪个字节开始读取数据。
- "componentType": 指定了访问器中每个组件的数据类型,这里的取值5126代表浮点数类型(FLOAT)。
- "count": 指定了访问器包含的元素数量,即顶点的数量。
- "max": 指定了访问器中数据的最大值,这里是一个包含三个浮点数的数组,表示每个分量的最大值。
- "min": 指定了访问器中数据的最小值,同样是一个包含三个浮点数的数组,表示每个分量的最小值。
- "type": 指定了访问器中每个元素的类型,这里是"VEC3",表示每个元素是一个三维向量。
除了上述的取值之外,"componentType"字段还可以取其他值,比如5120表示字节类型(BYTE)、5121表示无符号字节类型(UNSIGNED_BYTE)、5122表示短整型(SHORT)等。而"count"、"max"和"min"字段的取值根据实际数据而定,用于描述访问器中数据的数量和范围。
?bufferView
"bufferView": 指定了访问器使用的缓冲区视图的索引,用于获取二进制数据。
此字段应该对应bufferViews的字段中去获取对用的参数内容,此时的获取的就是具体的数值内容了
byteOffset?
"byteOffset": 指定了访问器从缓冲区视图中的哪个字节开始读取数据。
accessors与bufferViews数组中都有byteOffset字段区别如下
"byteOffset"字段在"accessors"和"bufferViews"中的含义略有不同。
在"bufferViews"中,"byteOffset"表示从缓冲区的起始位置(即整个缓冲区的起始位置)开始的偏移量,用于定位该视图的起始位置。这个偏移量是以字节为单位的,指示了该视图在缓冲区中的起始位置。
而在"accessors"中,"byteOffset"表示从关联的缓冲区视图的起始位置开始的偏移量,用于定位访问器的起始位置。同样,这个偏移量也是以字节为单位的。
count
"count": 指定了访问器包含的元素数量,即顶点的数量。
componentType
"componentType": 指定了访问器中每个组件的数据类型,这里的取值5126代表浮点数类型(FLOAT)。
下面是取值内容
// 根据componentType获取字节大小
function getSizeOfComponentType(componentType) {
switch (componentType) {
case 5120: // BYTE
case 5121: // UNSIGNED_BYTE
return 1;
case 5122: // SHORT
case 5123: // UNSIGNED_SHORT
return 2;
case 5126: // FLOAT
return 4;
default:
return 0;
}
}
type?
"type": 指定了访问器中每个元素的类型,这里是"VEC3",表示每个元素是一个三维向量。
下面是的各自取值内容
j
// 根据type获取组件数量
function getNumberOfComponents(type) {
switch (type) {
case "SCALAR":
return 1;
case "VEC2":
return 2;
case "VEC3":
return 3;
case "VEC4":
return 4;
default:
return 0;
}
}materials
"materials": [{ "pbrMetallicRoughness": { "baseColorTexture": { "index": 0 }, "metallicFactor": 0 }, "emissiveFactor": [0, 0, 0], "name": "blinn3-fx" }],
这段代码描述了一个材质(material),其中包含了PBR(Physically Based Rendering)金属粗糙度工作流(pbrMetallicRoughness)的定义。解释一下各个字段的含义:
- "pbrMetallicRoughness": 这个字段包含了PBR金属粗糙度工作流的定义,其中包括了基础颜色纹理(baseColorTexture)和金属度因子(metallicFactor)。
? - "baseColorTexture": 这里的"index"字段指定了基础颜色纹理的索引,用于获取实际的纹理数据。
? - "metallicFactor": 这个字段指定了金属度因子,用于控制材质的金属度属性。- "emissiveFactor": 这个字段指定了发光因子,是一个包含三个分量的数组,表示材质的发光属性。
- "name": 这个字段指定了材质的名称,这里是"blinn3-fx"。
通过这些字段的定义,可以描述材质的外观特性,包括基础颜色、金属度、粗糙度和发光属性等。这些信息对于渲染引擎来说非常重要,可以帮助正确地呈现出材质的外观和特性。
希望这能够帮助您理解这段代码中材质的定义。
?baseColorTexture字段指定了textures字段中获取参数,获取textures数组中的index下角标的参数
textures
"textures": [{ "sampler": 0, "source": 0 }],
这段代码描述了一个纹理(texture),其中包含了对应的采样器(sampler)和图像源(source)的索引。解释一下各个字段的含义:
- "sampler": 这个字段指定了纹理的采样器索引,用于描述纹理的采样参数,比如过滤方式、寻址模式等。
- "source": 这个字段指定了纹理的图像源索引,用于获取实际的图像数据。
通过这些字段的定义,可以将纹理与采样器和图像源进行关联,从而在渲染时正确地应用纹理,并根据采样器的参数进行采样。
?想必大家也基本理解怎么去寻找对应的字段了
let sampler =?textures[0].sampler? 去samplers去寻找
let?source =??textures[0].source 去images
images
"images": [{ "uri": "https://gw.alipayobjects.com/zos/OasisHub/267000040/4580/DuckCM.png" }],
参数主要是存放了图片的相关素材来源
samplers
"samplers": [{ "magFilter": 9729, "minFilter": 9986, "wrapS": 10497, "wrapT": 10497 }],
在glTF中,"samplers"字段用于定义纹理采样器(sampler),它包含了纹理采样时使用的参数和选项。这些参数包括纹理的过滤方式(如最近点采样、线性采样等)和寻址模式(如重复、边缘拉伸等)等。
具体来说,"samplers"字段中的每个条目描述了一个纹理采样器的设置,通常包括以下属性:
- "magFilter": 定义了纹理放大时的过滤方式。
- "minFilter": 定义了纹理缩小时的过滤方式。
- "wrapS": 定义了纹理在S轴上的寻址模式。
- "wrapT": 定义了纹理在T轴上的寻址模式。
- "name": 可选的,用于指定采样器的名称。通过"samplers"字段中的设置,可以为每个纹理指定不同的采样参数,以满足不同的渲染需求和效果。?
?magFilter与minFilter
"magFilter": 定义了纹理放大时的过滤方式。
"minFilter": 定义了纹理缩小时的过滤方式。
let?magFilter = parseMinFilter(params.magFilter, "TEXTURE_MAG_FILTER");
let?magFilter = parseMinFilter(params.magFilter, "TEXTURE_MAG_FILTER");?
/**
* 解析minFilter
* @param {number} minFilter - minFilter的取值
* @param {string} key - 键名
* @returns {Object} - 包含解析结果的对象
*/
function parseMinFilter(minFilter, key) {
switch (minFilter) {
case 9728:
return {
key: key,
value: "NEAREST",
};
case 9729:
return {
key: key,
value: "LINEAR",
};
case 9984:
return {
key: key,
value: "NEAREST_MIPMAP_NEAREST",
};
case 9985:
return {
key: key,
value: "LINEAR_MIPMAP_NEAREST",
};
case 9986:
return {
key: key,
value: "NEAREST_MIPMAP_LINEAR",
};
case 9987:
return {
key: key,
value: "LINEAR_MIPMAP_LINEAR",
};
default:
return {
key: key,
value: "UNKNOWN",
};
}
}
wrapS与wrapT
?"wrapS": 定义了纹理在S轴上的寻址模式。
?"wrapT": 定义了纹理在T轴上的寻址模式。
? ? let?wrapS = parseWrap(params.wrapS, "S");
? ? let?wrapT = parseWrap(params.wrapT, "T");
/**
* 解析wrapS或wrapT
* @param {number} wrapValue - wrapS或wrapT的取值
* @param {string} axis - 轴向('S'或'T')
* @returns {Object} - 包含解析结果的对象
*/
function parseWrap(wrapValue, axis) {
switch (wrapValue) {
case 33071:
return {
key: `TEXTURE_WRAP_${axis}`,
value: "CLAMP_TO_EDGE",
};
case 33648:
return {
key: `TEXTURE_WRAP_${axis}`,
value: "MIRRORED_REPEAT",
};
case 10497:
return {
key: `TEXTURE_WRAP_${axis}`,
value: "REPEAT",
};
default:
return {
key: `TEXTURE_WRAP_${axis}`,
value: "UNKNOWN",
};
}
}进行解析
下载器
首先我跟需要一个方法去加载,上述的内容,需要一个地址,然后同时把.bin文件下载
export function parseGltfAndDownloadBin(gltfUrl) {
return new Promise((resolve, reject) => {
// 加载glTF文件
fetch(gltfUrl)
.then((response) => response.json())
.then((gltfData) => {
// 获取.bin文件的URL
const binUrl = gltfData.buffers[0].uri;
// 加载.bin文件
fetch(binUrl)
.then((response) => response.arrayBuffer())
.then((binBuffer) => {
console.log('gltfData:',gltfData)
console.log("binBuffer:",binBuffer)
})
.catch((error) => {
reject("Error loading .bin file: " + error);
});
})
.catch((error) => {
reject("Error loading or parsing glTF: " + error);
});
});
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 蓝桥杯训练-水仙花数判断(day3)
- Sui链上存储基金,让你的数据安全且经济的Onchain
- 基于信号完整性的一些PCB设计建议
- 谈?谈你对TCPIP四层模型,OSI七层模型的理解
- 提高BMP像素,卓越图片管理体验,让每一张图片都焕然一新!
- 2012 关闭Windows Defender
- 管理类联考——数学——真题篇——按知识分类——代数——数列
- leetcode—— 腐烂的橘子
- 网络安全知识:严重漏洞可利用在内存中运行恶意代码
- C51--测速小车