逆向分析爬取网页动态
发布时间:2024年01月12日
本例子以爬取人民邮电出版社网页新书的信息为例
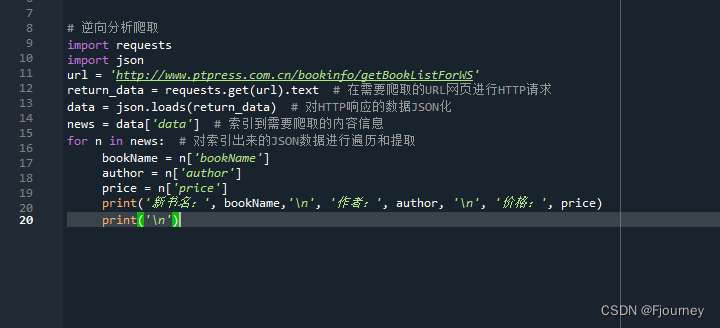
?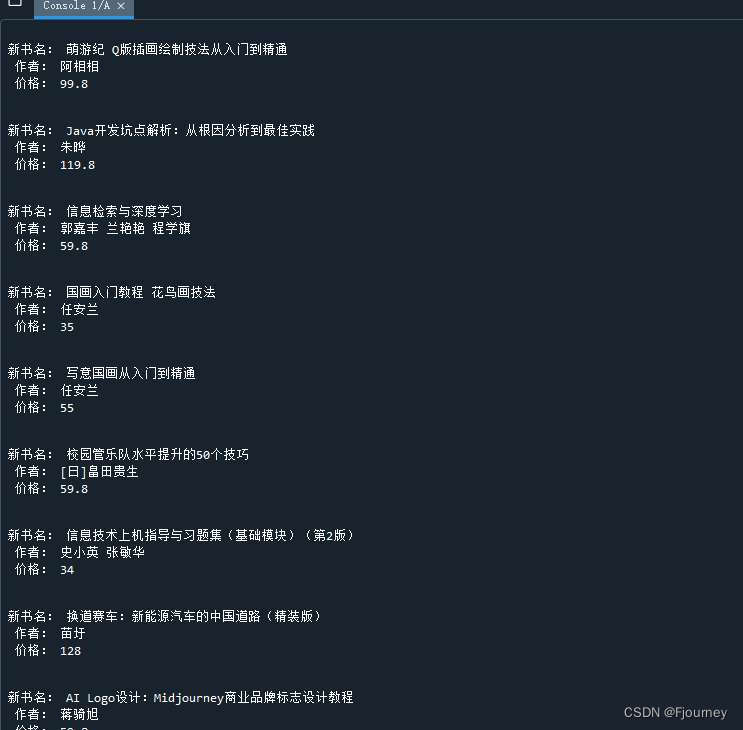
?由于页面是动态的,信息会不停地更新,所以不同时间的爬取结果会不同。
文章来源:https://blog.csdn.net/Fjourney/article/details/135563558
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!