数据库表合并场景实践
发布时间:2024年01月19日
在实际场景中,我们见的比较多的是表拆分,正好遇到一个需要表合并的需求,下面来分析分析
背景
目前是线上有若干张表:a1 a2、b1 b2、c1 c2...,目前需要将这些表进行合并[将b1 c1等表数据都合并到a1,将b2 c2等表合并到a2],但是线上也会有业务在跑,不能停机更新还需要保证迁移的健壮性
因为c1 c2合并的本质与b1 b2一致,故下面以b1 b2合并为例来进行描述
表结构与关系
CREATE TABLE `a1` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`info` varchar(255) COLLATE utf8mb4_croatian_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_croatian_ci;
CREATE TABLE `a2` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`a_id` int(11) DEFAULT NULL COMMENT 'a表id',
`info` varchar(255) COLLATE utf8mb4_croatian_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_croatian_ci;
CREATE TABLE `b1` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`info` varchar(255) COLLATE utf8mb4_croatian_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_croatian_ci;
CREATE TABLE `b2` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`b_id` int(11) DEFAULT NULL COMMENT 'a表id',
`info` varchar(255) COLLATE utf8mb4_croatian_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_croatian_ci;最初做法
性质冲冲完成了,SQL如下
insert into a1 (info) select info from b1;
insert into a2 (a_id,info) select b_id,info from b2;那么来测试下,看结果是否准确,结果如下
select a1.id,a1.info a1info,a2.a_id,a2.info a2info from a1 left join a2 on a1.id = a2.a_id;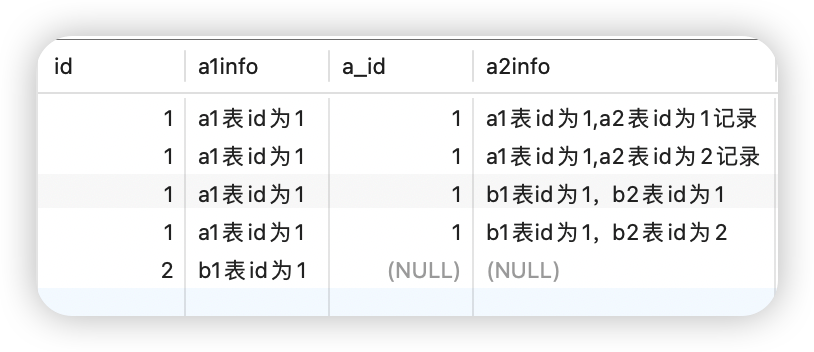
?很明显这个数据错乱了,b2迁移过来的数据与a1原来的数据关联上了,造成了数据混乱
方案改造
分析先前做法,其实是b2在做迁移时,没有考虑到b2中数据要同样与迁移过去的b1数据新的主键关联上,那么如何做呢?接着往下看
- a1表新增一个old_id字段,在b1迁移到a1表后,将b1原本的主键id保存在a1中
- a2表新增一个is_new字段,用来标识哪些是新插入到a2的数据,防止后续修数时将a2中旧数据关联上新迁移到a1中的数据
ALTER TABLE `a1` ADD COLUMN `old_id` int NULL COMMENT '旧表主键id';
ALTER TABLE `a2` ADD COLUMN `is_new` tinyint NULL COMMENT '是否新数据标记 1:正在迁移的数据 0:已迁移完的数据 null:线上在跑的数据' ;
insert into a1 (info,old_id) select info,id from b1;
insert into a2 (a_id,info,is_new) select b_id,info,1 from b2;
update a2,b1,a1 set a2.a_id = a1.id where a1.old_id is not null and a1.old_id = b1.id and a2.is_new = 1 and a2.a_id = a1.old_id;
-- 回滚SQL
ALTER TABLE `a1` DROP COLUMN `old_id`;
ALTER TABLE `a2` DROP COLUMN `is_new`;然后再用同样的SQL来测试
select a1.id,a1.info a1info,a2.a_id,a2.info a2info from a1 left join a2 on a1.id = a2.a_id;
到此为止,需求已经实现,但是还不完美,因为这段SQL仅仅只能跑一次,那么如果执行到一半因为各种原因失败了呢?如何将迁移的数据清理掉重新再次迁移呢?
这样看来我们上面的SQL健壮性还是不够
迁移SQL健壮性改造
-- 第一步:新增三个辅助迁移字段
ALTER TABLE `a1` ADD COLUMN `old_id` int NULL COMMENT '旧表主键id';
ALTER TABLE `a1` ADD COLUMN `is_new` int NULL COMMENT '是否新数据标记 1:是 0:否';
ALTER TABLE `a2` ADD COLUMN `is_new` tinyint NULL COMMENT '是否新数据标记 1:正在迁移的数据 0:已迁移完的数据 null:线上在跑的数据' ;
-- 第二步:开始数据迁移
insert into a1 (info,old_id,is_new) select info,id,1 from b1;
insert into a2 (a_id,info,is_new) select b_id,info,1 from b2;
-- 第三步:修正a2新迁移数据与原数据关联关系
update a2,b1,a1 set a2.a_id = a1.id where a1.old_id is not null and a1.old_id = b1.id and a2.is_new = 1 and a2.a_id = a1.old_id;
-- 第四步:打扫战场,方便后续C表等的迁移
UPDATE a2 SET is_new = 0 where is_new = 1;
-- C表重复第二步~第四步
-- ...
-- ...
-- 第五步迁移结束SQL
ALTER TABLE `a1` DROP COLUMN `old_id`;
ALTER TABLE `a1` DROP COLUMN `is_new`;
ALTER TABLE `a2` DROP COLUMN `is_new`;
-- 迁移失败回滚SQL
delete from a1 where is_new = 1;
delete from a2 where is_new is not null;结语?
希望此表合并场景能够为你提供一些思路,附件有提供SQL供测试使用
文章来源:https://blog.csdn.net/weixin_44700876/article/details/135612337
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 原型和原型链剖析
- 图形图像处理车牌识别系统设计matlab
- GEE机器学习——利用贝叶斯分类器方法进行土地分类和精度评定
- 拾叁[13],NCC模板匹配,函数CreateNccModel/FindNccModel/ReadNccModel/WriteNccModel
- 深入探索C++:面向未来的高效编程
- 封神榜大模型
- 深入探索Qt 6.3:全面了解新特性及应用技巧
- Laravel的知识点
- 利用ufun对部件进行操作(新建、打开、保存、另存、关闭等)
- 第28关 k8s监控实战之Prometheus(六)