YOLOv5改进 | 2023卷积篇 | DWRSeg扩张式残差助力小目标检测
一、本文介绍
本文内容给大家带来的DWRSeg中的DWR模块来改进YOLOv5中的C3和Bottleneck模块,主要针对的是小目标检测,主要创新点可以总结如下:多尺度特征提取机制的深入研究和创新的DWR模块和SIR模块的提出,这种方法使得网络能够更灵活地适应不同尺度的特征,从而更准确地识别和分割图像中的物体。?通过本文你能够了解到:DWRSeg的基本原理和框架,并且能够在你自己的网络结构中进行添加(DWRSeg需要增加一定的计算量一个DWR模块大概增加0.4GFLOPs)。
?推荐指数:????
训练结果对比图->??
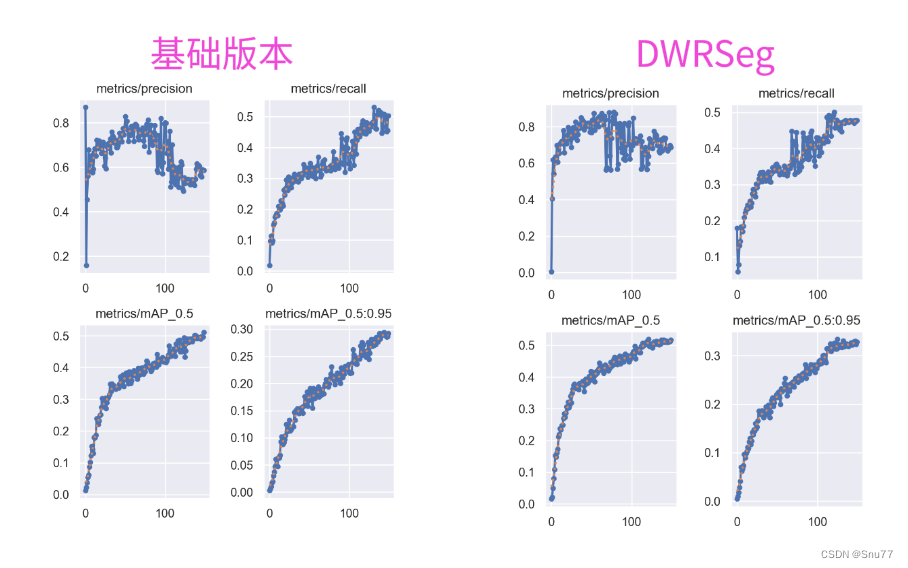 ?
?
目录
二、DWRSeg的原理介绍
 ?论文地址:官方论文地址
?论文地址:官方论文地址
代码地址:该代码目前还未开源,我根据论文内容进行了复现内容在文章末尾。
 ?
?
2.1 DWRSeg的主要思想?
DWRSeg的主要创新点可以总结如下:
-
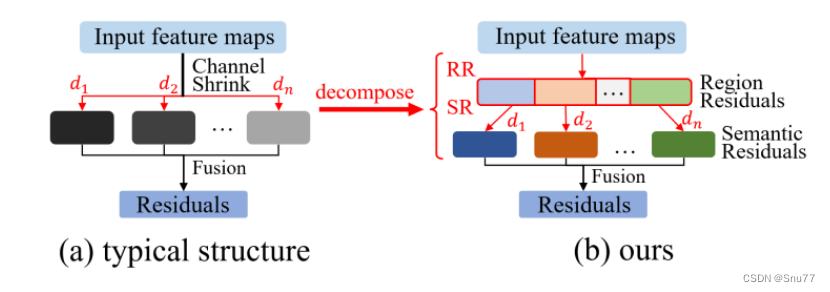
多尺度特征提取机制的深入研究:利用深度分离扩张卷积进行多尺度特征提取,并设计了一种高效的两步残差特征提取方法(区域残差化 – 语义残差化)。这种方法显著提高了实时语义分割中捕获多尺度信息的效率。
-
创新的DWR模块和SIR模块的提出:提出了一个新颖的DWR(扩张残差)模块和SIR(简单反向残差)模块。这些模块具有精心设计的接收场大小,分别用于网络的上层和下层。
 ?
?
DWRSeg网络在实时语义分割领域取得了一定的效果(从论文的结果来看下图),特别是在提高处理速度和减轻模型负担的方面。
 ?
?
2.2 多尺度特征提取机制的深入研究
利用深度分离扩张卷积进行多尺度特征提取。主要内容可以总结如下:
-
两步残差特征提取方法:该方法包括区域残差化(Region Residualization)和语义残差化(Semantic Residualization),旨在提高实时语义分割中多尺度信息捕获的效率??。
-
区域残差化:这一步骤中,首先将区域特征图分成几组,然后对这些组进行不同速率的深度分离扩张卷积。这样做可以智慧地根据第二步中的接收场大小来学习特征图,以反向匹配接收场??。
-
语义残差化:在这一步中,仅使用一个具有期望接收场的深度分离扩张卷积对每个简洁的区域形式特征图进行基于语义的形态学过滤。这改变了多速率深度分离扩张卷积在特征提取中的角色,从尝试获取尽可能多的复杂语义信息转变为对每个简洁表达的特征图进行简单的形态学过滤??。
-
精细化的扩张率和容量设计:为了充分利用每个网络阶段可以实现的不同区域大小的特征图,需要精心设计扩张率和深度分离卷积的容量,以匹配每个网络阶段的不同接收场要求??。
通过这种多尺度特征提取机制的深入研究和创新设计,论文提高了实时语义分割任务中多尺度信息捕获的效率(第一小节的图片)。
2.3?创新的DWR模块和SIR模块的提出
提出的DWR模块和SIR模块的创新点如下:
DWR(Dilation-wise Residual)模块(本文复现的就是这个DWR模块)
- 应用场景:DWR模块主要应用于网络的高阶段,采用设计的两步特征提取方法??。
- 特征提取:该模块利用两步残差特征提取方法(区域残差化 – 语义残差化),有效提高实时语义分割中多尺度信息捕获的效率。
- 接收场大小设计:DWR模块针对网络的上层设计了精细化的接收场大小。
SIR(Simple Inverted Residual)模块
- 应用场景:SIR模块专门为网络的低阶段设计,以满足小接收场的需求,保持高效的特征提取效率??。
- 结构调整:
- 移除了多分支扩张卷积结构,仅保留第一分支,以压缩接收场。
- 移除了对提取效果贡献较小的3x3深度分离卷积(语义残差化),因为输入特征图的大尺寸和弱语义使得单通道卷积收集的信息太少。因此,在低阶段,单步特征提取比两步特征提取更高效。
 ?
?
总结:这两个模块的设计改进对于提高实时语义分割网络的性能至关重要,高效处理多尺度上下文信息的能力方面。
三、DWR模块代码
3.1 DWR模块复现代码
使用方法请看章节四
import torch
import torch.nn as nn
class Conv(nn.Module):
# 包含BN和ReLU
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
super(Conv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class DWR(nn.Module):
def __init__(self, c) -> None:
super().__init__()
self.conv_3x3 = Conv(c, c, 3, padding=1)
self.conv_3x3_d1 = Conv(c, c, 3, padding=1, dilation=1)
self.conv_3x3_d3 = Conv(c, c, 3, padding=3, dilation=3)
self.conv_3x3_d5 = Conv(c, c, 3, padding=5, dilation=5)
self.conv_1x1 = Conv(c * 3, c, 1)
def forward(self, x):
x_ = self.conv_3x3(x)
x1 = self.conv_3x3_d1(x_)
x2 = self.conv_3x3_d3(x_)
x3 = self.conv_3x3_d5(x_)
x_out = torch.cat([x1, x2, x3], dim=1)
x_out = self.conv_1x1(x_out) + x
return x_out
class DWRSeg_Conv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, groups=1, dilation=1):
super().__init__()
self.conv = Conv(in_channels, out_channels, 1)
self.dcnv3 = DWR(out_channels)
self.bn = nn.BatchNorm2d(out_channels)
self.gelu = nn.GELU()
def forward(self, x):
x = self.conv(x)
x = self.dcnv3(x)
x = self.gelu(self.bn(x))
return x
class Bottleneck_DWRSeg(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = DWRSeg_Conv(c_, c2, k[1], 1, groups=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = DWRSeg_Conv(c_, c2, 3, 1, groups=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.Dattention(self.cv2(self.cv1(x))) if self.add else self.Dattention(self.cv2(self.cv1(x)))
class C3_DWRSeg(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
四、手把手教你添加DWRSeg和C3_DWR模块
?4.1 细节修改教程
4.1.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。
?
?
?4.1.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。

?
4.1.3 修改三?
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加。)
 ????
????
4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->
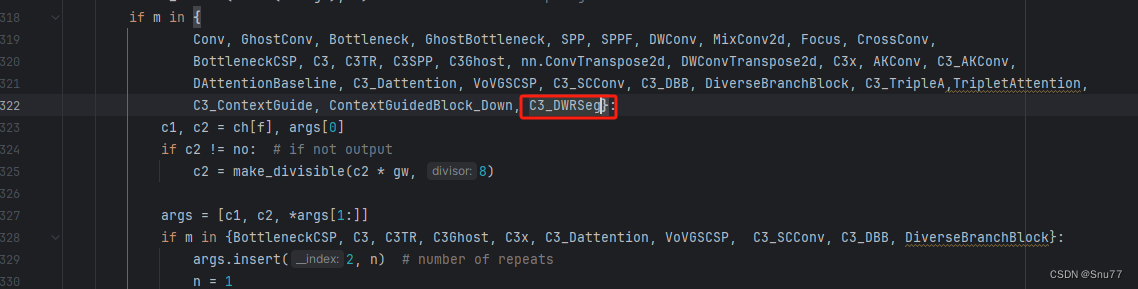
到此就修改完成了,复制下面的ymal文件即可运行。
4.2 DWRSeg的yaml文件(仔细看这个否则会报错)
4.2.1 DWRSeg的yaml文件一
下面的配置文件为我修改的DBB的位置,参数的位置里面什么都不用添加空着就行,大家复制粘贴我的就可以运行,同时我提供多个版本给大家,根据我的经验可能涨点的位置。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3_DWRSeg, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3_DWRSeg, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3_DWRSeg, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
4.2.2 DBB的yaml文件二
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_DWRSeg, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_DWRSeg, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_DWRSeg, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_DWRSeg, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3_DWRSeg, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3_DWRSeg, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3_DWRSeg, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3_DWRSeg, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
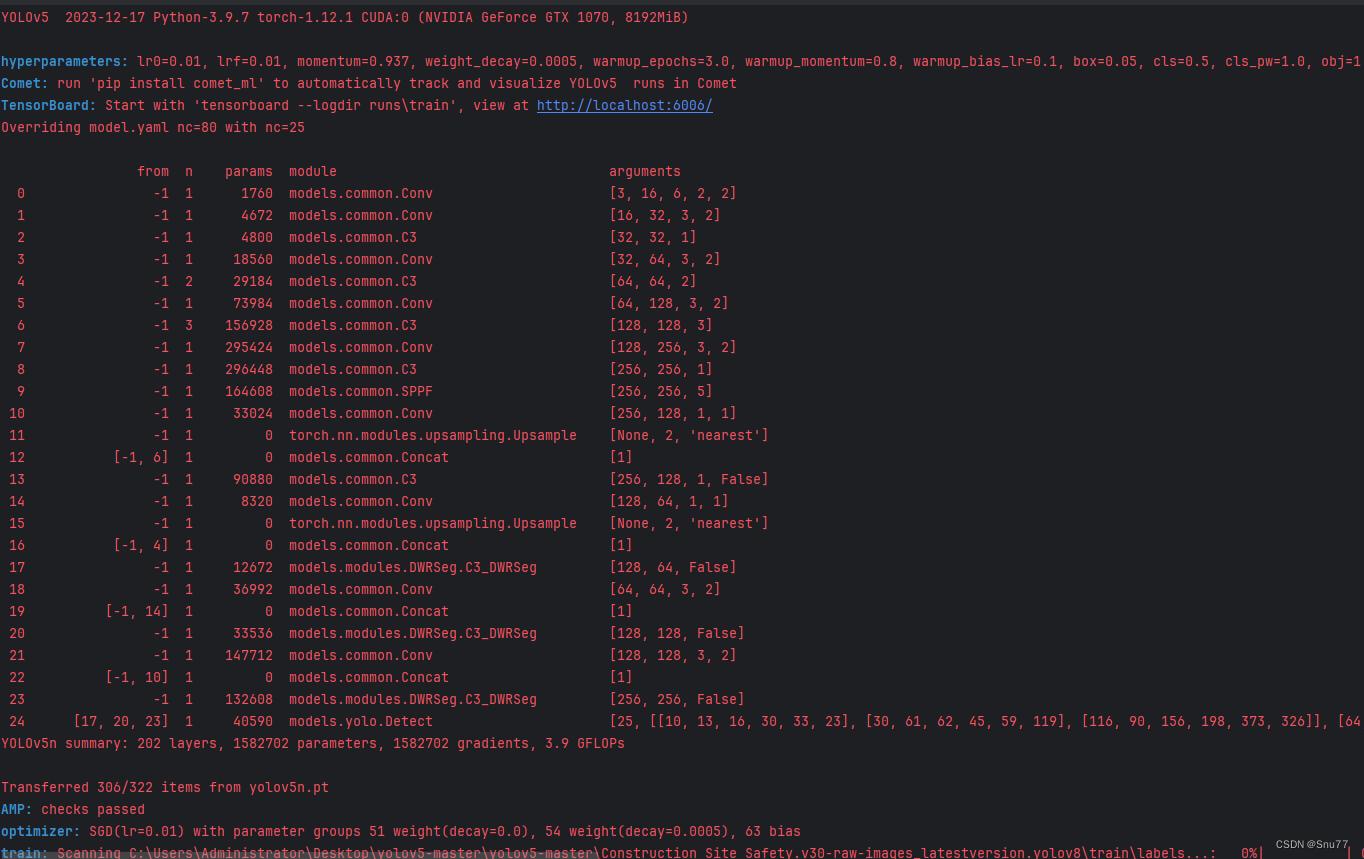
4.3 DWRSeg运行成功截图
附上我的运行记录确保我的教程是可用的。?
4.4 推荐DWRSeg可添加的位置?
DWRSeg是一种即插即用的可替换卷积的模块,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入DWRSeg(yaml文件一)。
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加修改后的C3_DWRSeg可以帮助模型更有效地融合不同层次的特征(yaml文件二)。
检测头中:可以再检测头的内部添加该机制(未提供因为需要修改检测头比较麻烦,后期专栏收费后大家购买专栏之后大家会得到一个包含上百个机制的v5文件里面包含所有的改进机制)
五、本文总结?
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java Swing手搓童年坦克大战游戏(I)
- MariaDB数据库本地部署结合cpolar内网穿透实现远程连接
- 前端密钥怎么存储,以及临时存储一些数据,如何存储才最安全?
- 【文化科技深度融合 铸造新商业文明】第十一届中关村大数据日再启新程
- 离线数据仓库-关于增量和全量
- 欲擒故纵,来回推拉,撩拨心房
- CentOS安装Docker(超详细)
- MySQL数据库基础入门
- Lombok 使用教程+案例
- 如何通过数字孪生技术构建智慧城市