如何让GPT支持中文
上一篇已经讲解了如何构建自己的私人GPT,这一篇主要讲如何让GPT支持中文。
privateGPT 本地部署目前只支持基于llama.cpp 的 gguf格式模型,GGUF 是 llama.cpp 团队于 2023 年 8 月 21 日推出的一种新格式。它是 GGML 的替代品,llama.cpp 不再支持 GGML。
本文主要采用国产YI-34B-CHAT模型。
1.模型下载
yi模型下载:TheBloke/Yi-34B-Chat-GGUF · Hugging Face
下载后放置在 models 文件夹下
embedding模型下载:BAAI/bge-small-en-v1.5 · Hugging Face
下载后放置在models/cache文件夹下,bge is short for BAAI general embedding,FlagEmbedding 可以将任何文本映射到低维密集向量,该向量可用于检索、分类、聚类或语义搜索等任务。它还可以用于法学硕士的矢量数据库
2.settings.yaml 文件修改:
主要修改local部分,使用YI模型使用prompt_style: "tag"类型的提示词模板
llm_hf_model_file: yi-34b-chat.Q4_K_M.gguf
prompt_style: "tag"3.代码修改
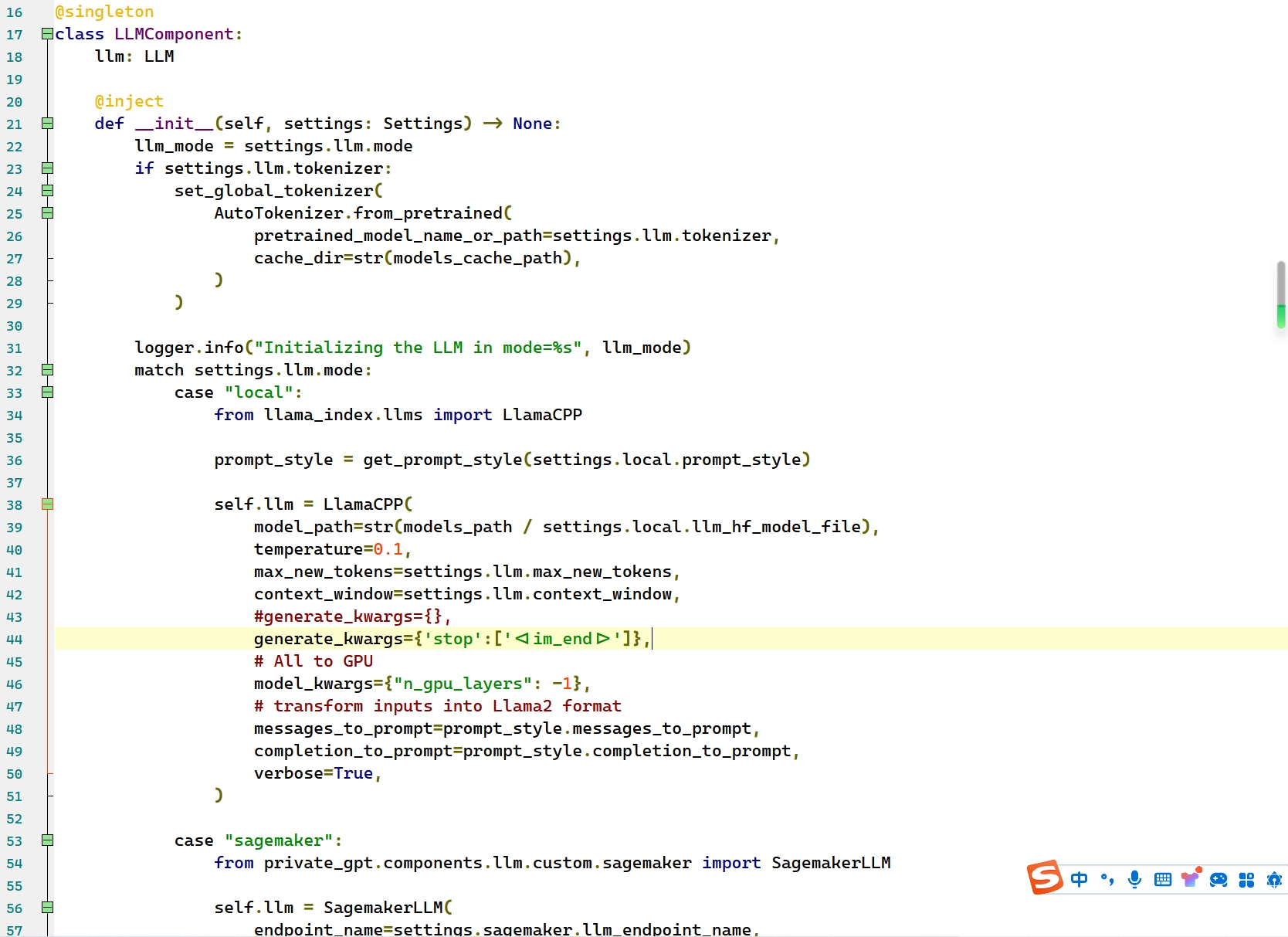
使用YI-34B-CHAT模型,源码要简单修改下,修改如下
文件路径 privateGPT/private_gpt/components/llm/llm_component.py
第44行,添加如下内容:
generate_kwargs={'stop':['<|im_end|>']},如图:
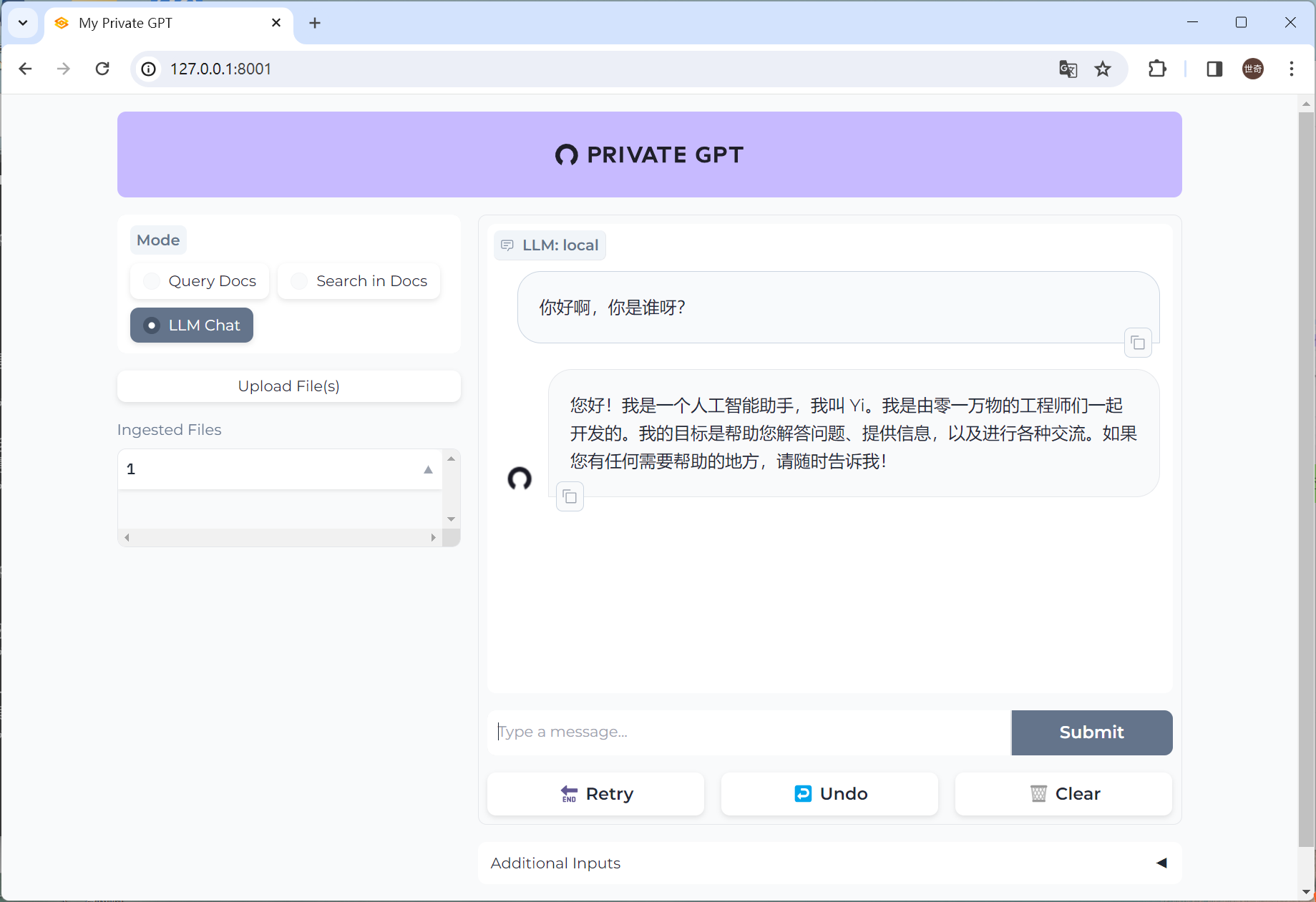
导航到 UI:在浏览器中打开 http://localhost:8001/。
?
原理解析
这套方法使用了 LangChain, GPT4All, LlamaCpp, Chroma and SentenceTransformers.
LangChain 用来生成文本向量,Chroma 存储向量。GPT4All、LlamaCpp用来理解问题,匹配答案。基本原理是:问题到来,向量化。检索语料中的向量,给到最相似的原始语料。语料塞给大语言模型,模型回答问题。基本原理和chatpdf没大差别。
创建自己的模型
Llama2 模型使用16位浮点数作为权重进行训练。我们可以将其缩小到4位整数以进行推理,而不会失去太多的功率,但会节省大量的计算资源(特别是昂贵的 GPU RAM)。这是已经被证实的。这个过程叫做量化。
GGUF格式专为 LLM 推理设计。它支持 LLM 任务,如语言编码和解码,使其比 PyTorch 更快、更容易使用。
使用 convert.py 实用程序将一个 PyTorch 模型转换为 GGUF 。你只需给出包含 PyTorch 文件的目录。这里的 GGUF 模型文件是完整的16位浮点模型
Llama2 模型,可以使用 llama.cpp 将其转换并量化为 GGUF,使用 convert.py 实用程序将一个 PyTorch 模型转换为 GGUF,quantize 命令行工具量化 FP16 GGUF 文件。下面的命令使用5位 k-量化创建一个新的 GGUF 模型文件。你可以在自己的应用程序中使用 GGUF 模型文件,或者在 Huggingface 上与全世界分享你的模型
构建自己的私人GPT
privateGPT中如何使用国产YI-34B-CHAT模型
如何创建 GGUF 模型文件?
全面了解 PrivateGPT:中文技巧和功能实测
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- element + table 每两行对比相同值列合并
- C++初阶类与对象(三):详解复制构造函数和运算符重载
- 图文证明 等价无穷小替换
- RK3568驱动指南|第九篇 设备树模型-第85章设备模型基本框架-kobject和kset
- 代码+视频,手把手教你R语言使用scitb包绘制倾向性评分匹配后的标准化平均差图
- 华为openEuler使用阿里云yum源
- 物理机与vm文件共享与传输的设置方法
- 【leetcode 2807. 在链表中插入最大公约数】链表插入 & 辗转相除法(欧几里得法) & C++中的gcd
- STA | 什么是Noise噪声检查?
- 【Java万花筒】Java脚本之舞:发现动态脚本的神奇力量