Hutool--DFA 敏感词工具类
发布时间:2023年12月19日
使用hutool的dfa工具类可以很好的帮助我们来实现敏感词过滤的功能,下面从用例入手来逐步地去j简单了解一下dfa工具类。
字典树
DFA算法的核心是建立了以敏感词为基础的许多敏感词树(字典树)。 它的基本思想是基于状态转移来检索敏感词。
字典树,是一种树形结构树形结构,主要用于统计,排序和保存大量的字符串。
主要思想:利用字符串的公共前缀来节约存储空间,很好地利用了串的公共前缀,节约了存储空间,字典树主要包含插入和查找两种操作。
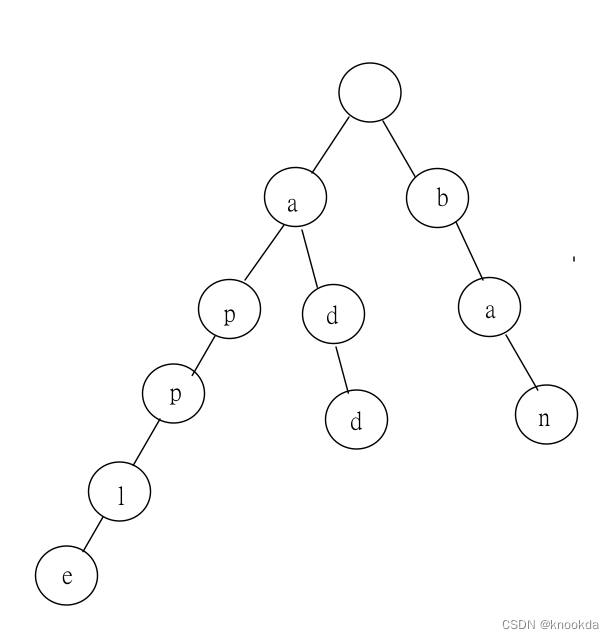
初始化敏感词库
在文本中查找敏感词之前,首先需要一个存放敏感词的词库作为查找标准。
public void initKeyWord() throws IOException {
List<String> strings = new ArrayList<>();
URL path = ResourceUtil.getResource("txtTemplate/words.txt");
File file = FileUtil.file(path);
FileReader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader);
String line = bufferedReader.readLine();
while (line != null) {
strings.add(line);
line = bufferedReader.readLine();
}
SensitiveUtil.init(strings);
}
此段代码通过读取文件中的敏感词来初始化词库,主角自然是SensitiveUtil工具类。此工具类中,有一个棵重要的树:dfa字典树。
private static final WordTree sensitiveTree = new WordTree();
public static void init(Collection<String> sensitiveWords) {
sensitiveTree.clear();
sensitiveTree.addWords(sensitiveWords);
}
可以看到是通过WordTree 的addWords中的添加方法来构建敏感词的字典树的。
ublic WordTree addWord(String word) {
final Filter<Character> charFilter = this.charFilter;
WordTree parent = null;
WordTree current = this;
WordTree child;
char currentChar = 0;
final int length = word.length();
for (int i = 0; i < length; i++) {
currentChar = word.charAt(i);
if (charFilter.accept(currentChar)) {
child = current.get(currentChar);
if (child == null) {
child = new WordTree();
current.put(currentChar, child);
}
parent = current;
current = child;
}
}
if (null != parent) {
parent.setEnd(currentChar);
}
return this;
}
查找敏感词并替换
对传入的文本进行敏感词查找,并将敏感词替换为相应数量的*。
public String replaceKeyWords(String text){
List<FoundWord> matchAll = SensitiveUtil.getFoundAllSensitive(text, false, true);
if (matchAll.size() > 0) {
for (FoundWord match : matchAll) {
String str = match.getFoundWord();
StringBuilder replace = new StringBuilder();
for (int i = 0; i < StrUtil.length(str); i++) {
replace.append("*");
}
text = StrUtil.replace(text, str, replace.toString());
}
}
return text;
}
FoundWord是在工具类中自定义的类,通过getFoundWord()方法可以拿到查找到的单词,详细信息请查阅源码。getFoundAllSensitive方法对敏感词进行查找,返回一个FoundWord集合
public static List<FoundWord> getFoundAllSensitive(String text) {
return sensitiveTree.matchAllWords(text);
}
文章来源:https://blog.csdn.net/m0_60610120/article/details/135095189
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 浅谈对Maven的理解
- Linux内核源码学习 Ext2文件系统布局,文件数据块寻址,VFS虚拟文件系统 转载
- 解决nuxt3中vue3生命周期钩子onMounted不执行的问题
- 转盘寿司(100%用例)C卷 (Java&&Python&&C++&&Node.js&&C语言)
- Gradle笔记
- JVM工作原理与实战(十):类加载器-Java类加载器
- 【setDS】牛客小白月赛83 E
- 2024年回炉计划之搜索算法(二)
- Jmeter测试时遇到的各种乱码问题及解决
- 【ThreeJS入门——】WEB 3D可视化技术——threejs