Redis基础系列-哨兵模式
Redis基础系列-哨兵模式
1. 引言
Redis是一种流行的内存数据库,具有快速、灵活和可扩展的特性。然而,在应用程序对数据可用性和可靠性要求更高时,Redis主从复制会遇到一些限制和弊端,主机宕机之后,整个redis服务只能读不能写。为了解决这些问题,Redis引入了哨兵模式。
2. 什么是哨兵模式?
Redis 哨兵模式是一种用于构建高可用性 Redis 集群的解决方案。它通过监控 Redis 实例的状态并自动进行故障转移,提供了客户端重定向机制以确保应用程序可以正常访问 Redis。

其中:
- 三个哨兵:自动监控和维护集群,不存放数据,只做吹哨人
- 1主2从:用于读取和存放数据
哨兵模式能干嘛:
- 主从监控:监控reids主从是否正常运行
- 消息通知:哨兵可以将故障转移的结果发送给客户端
- 故障转移:如果Master异常,则会进行主从切换,将其中一个Slave作为新的Master
- 配置中心:客户端通过连接哨兵来获得当前Redis服务的主节点地址
3. 哨兵模式的配置
- 在
/myredis目录下创建sentinel26379.conf(也可以从redis的解压路径中复制sentinel.conf配置文件来重命名),内容如下:
#服务监听地址,用于客户端连接,默认本机地址
bind 0.0.0.0
#是否已后台daemon方式启动
daemonize yes
#安全保护模式
protected-mode no
#哨兵端口
port 26379
#日志文件路径
logfile "/myredis/sentinel26379.log"
#pid文件路径
pidfile /var/run/redis-sentinel26379.pid
#工作目录
dir /myredis
#设置要监控的master服务器,quorum表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数
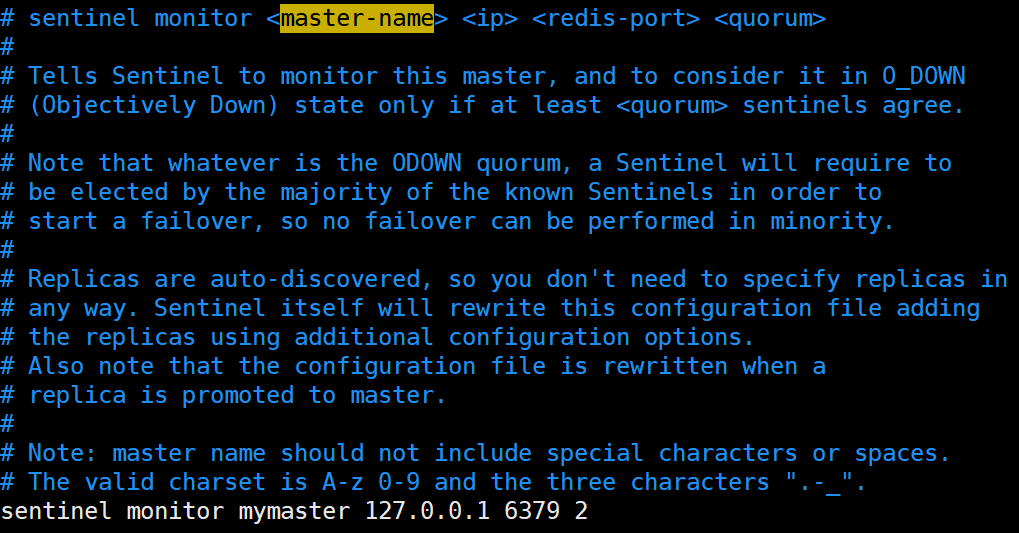
sentinel monitor mymaster 192.168.10.110 6379 2
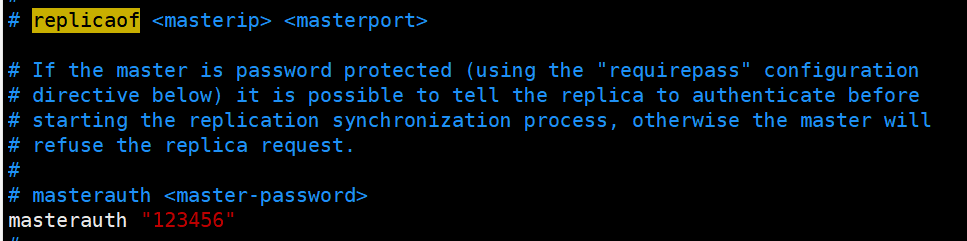
#master设置了密码,连接master服务的密码
sentinel auth-pass mymaster 123456
其他配置(一般不需要配置,默认就可以)
#指定多少毫秒之后,主节点没有应答哨兵,此时哨兵主观上认为主节点下线
sentinel down-after-milliseconds <master-name> <milliseconds>:
#表示允许并行同步的slave个数,当Master挂了后,哨兵会选出新的Master,此时,剩余的slave会向新的master发起同步数据
sentinel parallel-syncs <master-name> <nums>:
#故障转移的超时时间,进行故障转移时,如果超过设置的毫秒,表示故障转移失败
sentinel failover-timeout <master-name> <milliseconds>:
#配置当某一事件发生时所需要执行的脚本
sentinel notification-script <master-name> <script-path> :
#客户端重新配置主节点参数脚本
sentinel client-reconfig-script <master-name> <script-path>:
- 同样的在
/myredis目录下创建sentinel26380.conf内容如下:
#服务监听地址,用于客户端连接,默认本机地址
bind 0.0.0.0
#是否已后台daemon方式启动
daemonize yes
#安全保护模式
protected-mode no
#哨兵端口
port 26380
#日志文件路径
logfile "/myredis/sentinel26380.log"
#pid文件路径
pidfile /var/run/redis-sentinel26380.pid
#工作目录
dir /myredis
#设置要监控的master服务器,quorum表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数
sentinel monitor mymaster 192.168.10.110 6379 2
#master设置了密码,连接master服务的密码
sentinel auth-pass mymaster 123456
- 同样的在
/myredis目录下创建sentinel26381.conf内容如下:
#服务监听地址,用于客户端连接,默认本机地址
bind 0.0.0.0
#是否已后台daemon方式启动
daemonize yes
#安全保护模式
protected-mode no
#哨兵端口
port 26381
#日志文件路径
logfile "/myredis/sentinel26381.log"
#pid文件路径
pidfile /var/run/redis-sentinel26381.pid
#工作目录
dir /myredis
#设置要监控的master服务器,quorum表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数
sentinel monitor mymaster 192.168.10.110 6379 2
#master设置了密码,连接master服务的密码
sentinel auth-pass mymaster 123456
- 一主二从的配置前面已介绍过,就不过多赘述:
Redis基础系列-主从复制
4. 哨兵模式的启动和验证
- 先启动一主二从,并验证主从是否正常
- 然后启动三个哨兵
redis-sentinel sentinel26379.conf --sentinel
redis-sentinel sentinel26380.conf --sentinel
redis-sentinel sentinel26381.conf --sentinel
看看启动成功了
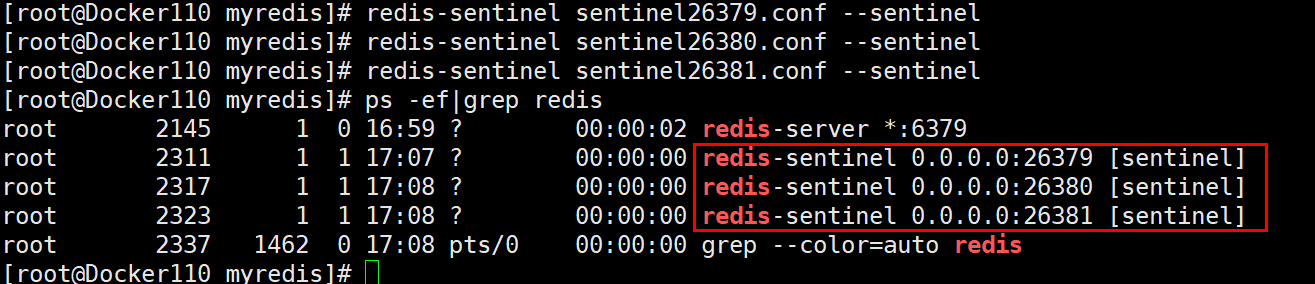
我们在瞅瞅日志
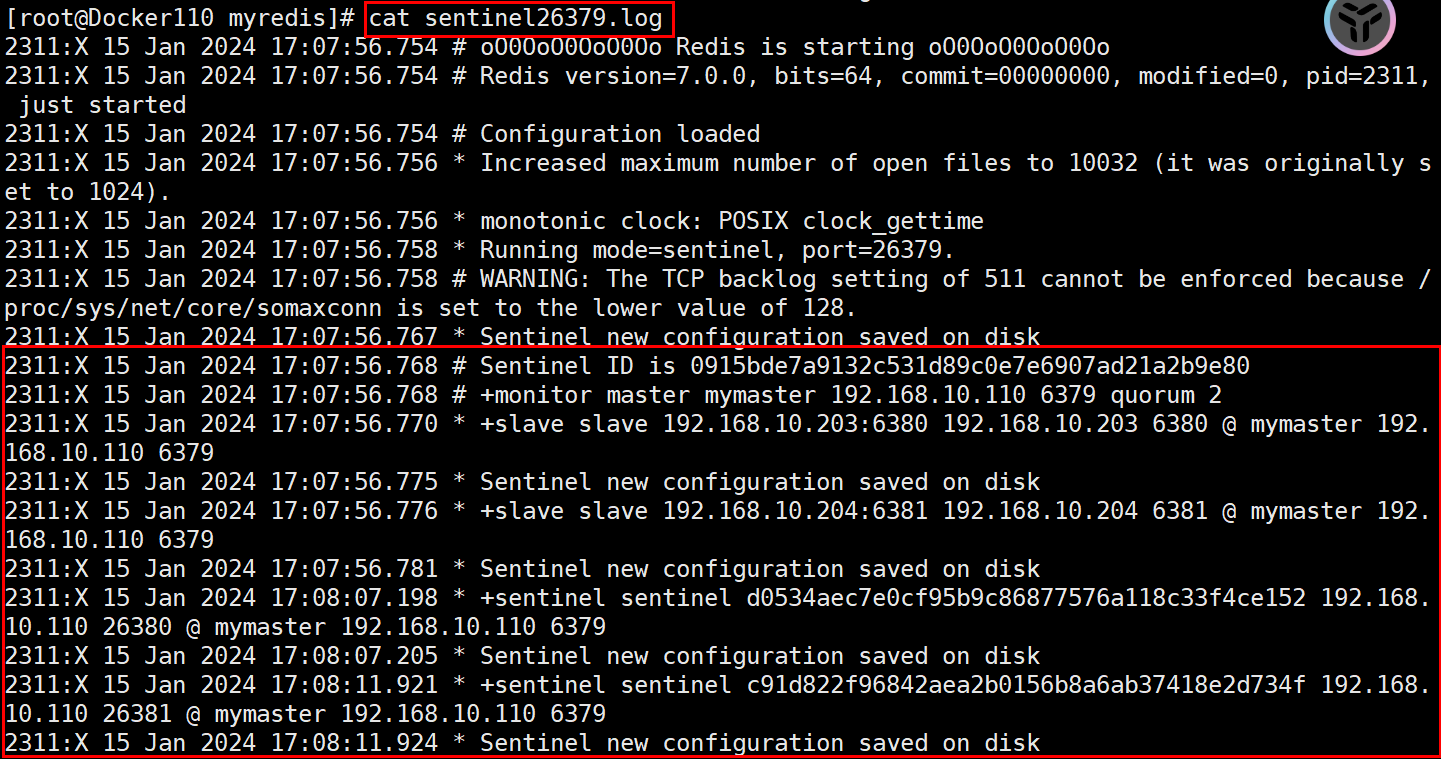
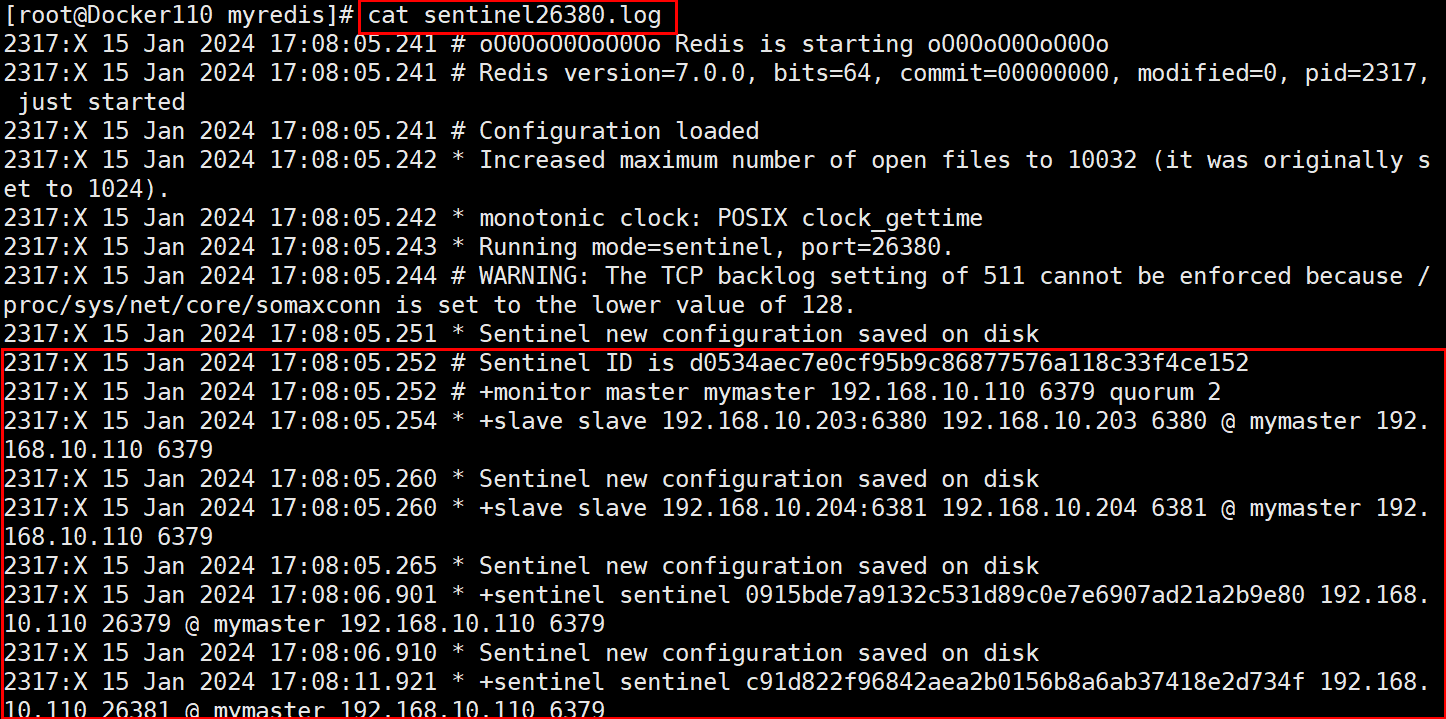

4.1 主master宕机,看会出现什么问题

6380从机会出现一段时间不能连接,自动连接之后还是从机

6381从机会出现一段时间不能连接,自动连接之后晋升为主机
我们在看看哨兵配置文件会发生什么变化

上述图片是哨兵26379的配置文件变化,其它两个哨兵的配置文件也是类似变化,这里就不在赘述。
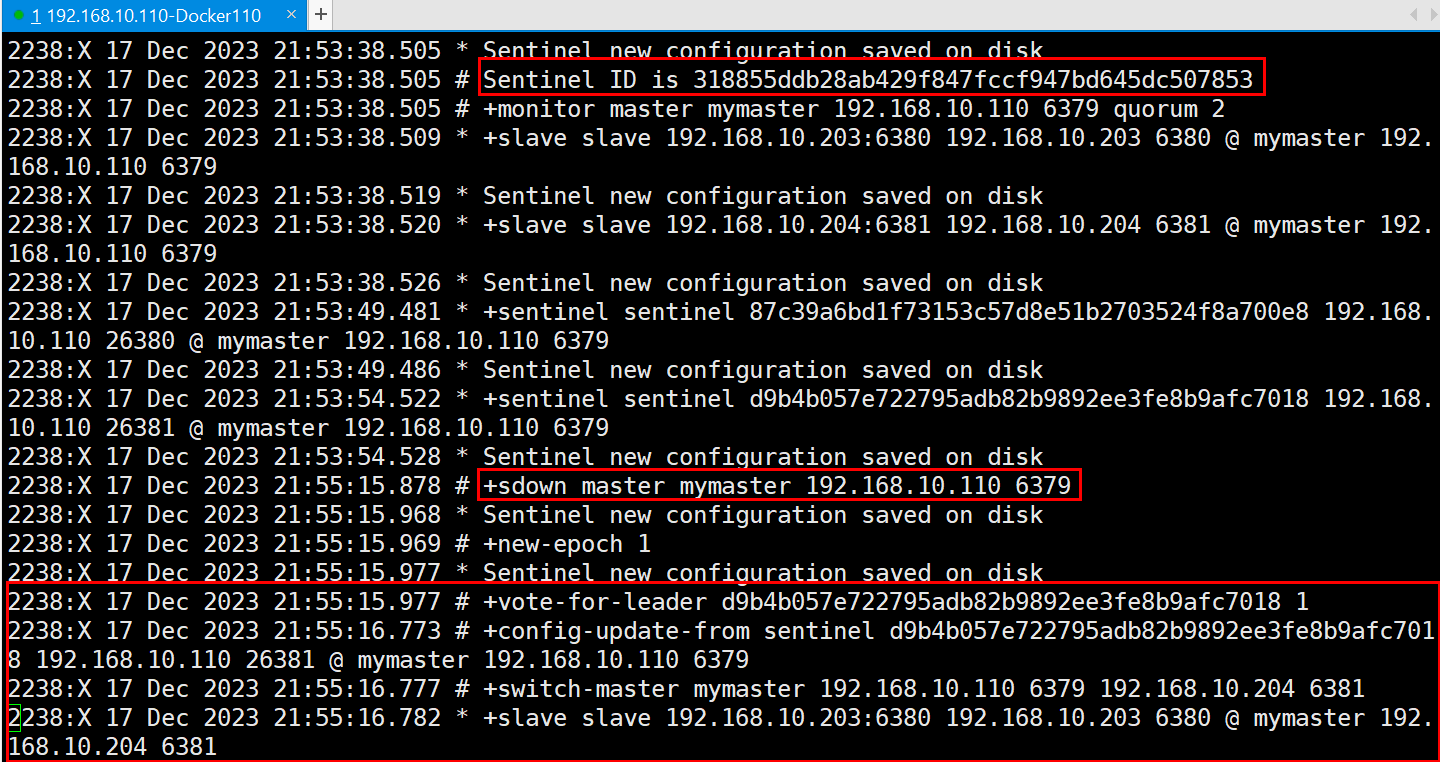
我们再查看一下哨兵26379日志的变化

我们能明显的看到6379的主观下线,选举leader以及主master切换的日志
我们再看一下6380和6381两个从机的配置文件

6380从机明显修改了主master的配置
再看一下6381的配置文件
6381从机明显删除了主master的配置,摇身一变成为主机
其实6379宕机变化
- 三个哨兵配置文件的变化
- 2个从机配置文件发生了变化(6379启动之后也能看到发生了变化)
那我们还有一个疑问,就是6379主机master恢复之后,目前这种主从结构会不会发生变化了,我们重新启动6379redis
4.2 重启6379主机
[root@Docker110 myredis]# redis-server redis6379.conf
[root@Docker110 myredis]#
然后看看运行情况

居然不能写,再看看它的配置文件

看来重启之后不能恢复原有的主从结构
5. 哨兵模式的工作原理和选举原理
当一个主存配置中的master失效之后,sentinel可以选举出一个新的master,用于自动接替master的工作,主从配置中的其他redis服务器自动指向新的master同步数据。一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换
5.1. SDown主观下线(Subjectively Down)
SDown(主观不可用)是单个sentinel自己主观上检测到的关于master的状态,从sentinel的角度来看,如果发送了PING心跳,在一定时间内没有收到合法的回复,就达到了SDown的条件
sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度
所谓主观下线(Subjectively Down, 简称 SDOWN)指的是单个Sentinel实例对服务器做出的下线判断,即单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。
主观下线就是说如果服务器在[sentinel down-after-milliseconds]给定的毫秒数之内没有回应PING命令或者返回一个错误消息, 那么这个Sentinel会主观的(单方面的)认为这个master不可以用了,
sentinel down-after-milliseconds <masterName> <timeout>
表示master被当前sentinel实例认定为失效的间隔时间,这个配置其实就是进行主观下线的一个依据
master在多长时间内一直没有给Sentine返回有效信息,则认定该master主观下线。也就是说如果多久没联系上redis-servevr,认为这个redis-server进入到失效(SDOWN)状态

5.2. ODown客观下线(Objectively Down)
ODown需要一定数量的sentinel,多个哨兵达成一致意见才能认为一个master客观上已经宕机
四个参数含义:
masterName是对某个master+slave组合的一个区分标识(一套sentinel可以监听多组master+slave这样的组合)
quorum这个参数是进行客观下线的一个依据,法定人数/法定票数
意思是至少有quorum个sentinel认为这个master有故障才会对这个master进行下线以及故障转移。因为有的时候,某个sentinel节点可能因为自身网络原因导致无法连接master,而此时master并没有出现故障,所以这就需要多个sentinel都一致认为该master有问题,才可以进行下一步操作,这就保证了公平性和高可用
5.3. 选举出领导者哨兵(哨兵中选出兵王)
当主节点被判断客观下线以后,各个哨兵节点会进行协商,先选举出一个领导者哨兵节点(兵王)并由该领导者节点,也即被选举出的兵王进行failover(故障迁移)
哨兵领导者,也就是兵王是如何选择出来的?Raft算法
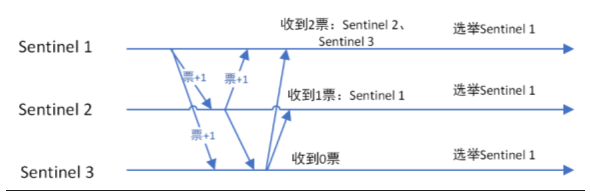
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:
即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者
上图理解:横向是时间轴,sentinel1向sentinel2、sentinel3发起成为领导者申请,sentinel2和sentinel3之前没有同意过别的sentinel,所以直接同意,故而sentinel得到两票;同理sentinel2向sentinel1和sentinel3发起成为领导者的申请,之前sentinel3同意过sentinel1的申请,所以sentinel只能获得1票;sentinel3向sentinel1和sentinel2发起成为领导者的申请,由于sentinel1和sentinel2都同意过别的sentinel,故而sentinel3只能获得0票
sentinel26379.log
sentinel26380.log
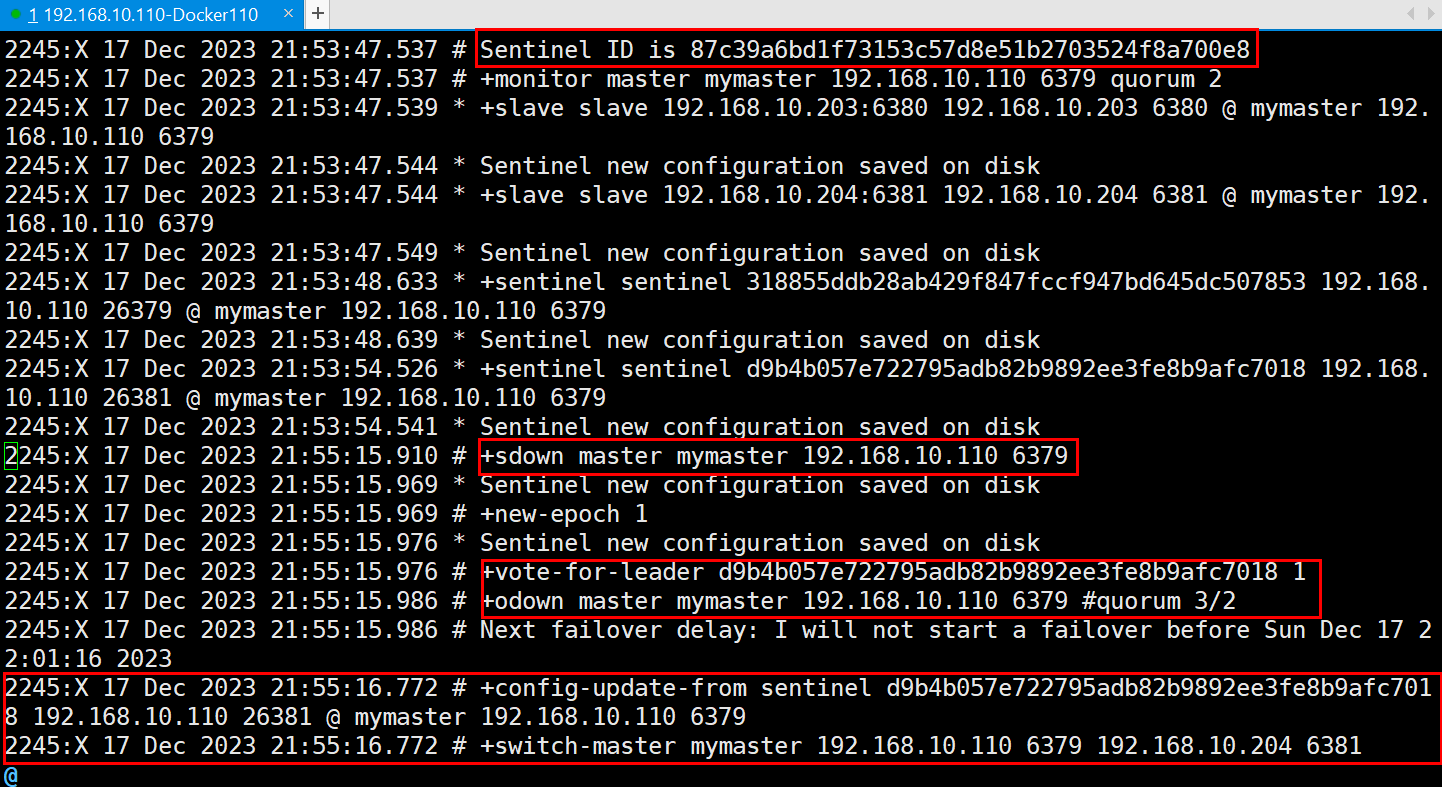
sentinel26381.log
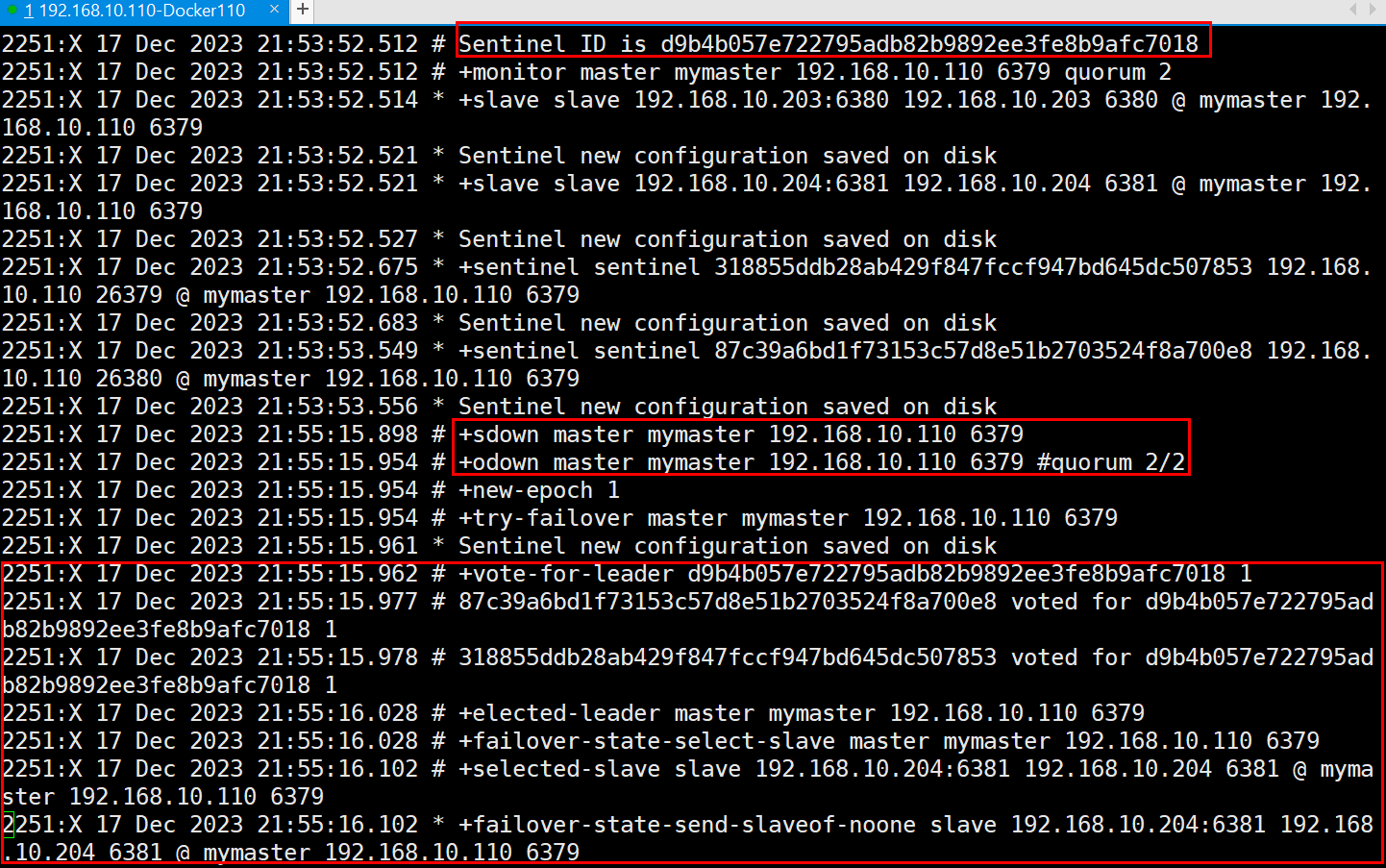

// TODO -odown 和 +odown有啥区别
5.4. 由兵王开始推动故障切换流程并选出一个新的master
5.4.1 步骤1:新主登基(某个Slave被选中成为新的Master)
选出新master的规则,剩余slave节点健康的情况下:
- redis.conf文件中,优先级slave-priority或者replica-priority最高的从节点(数字越小优先级越高)
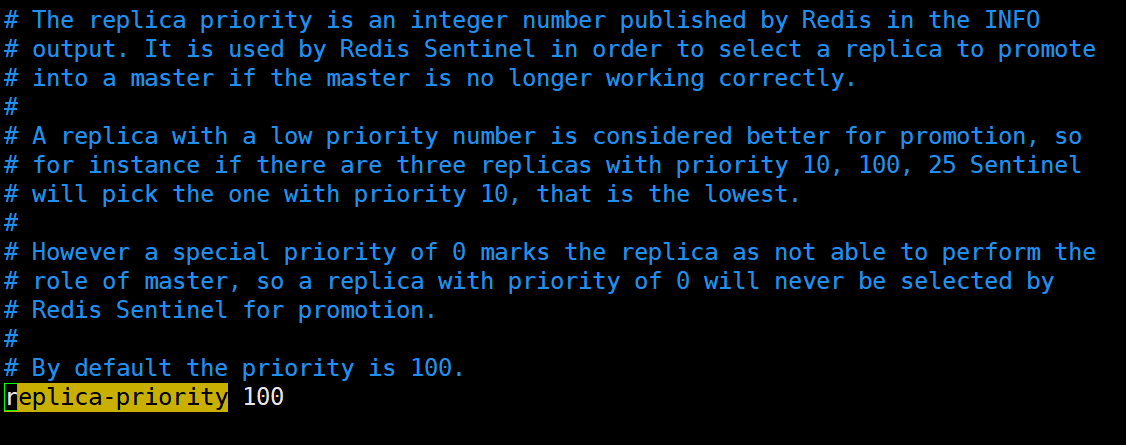
- 复制偏移位置offset最大的从节点// TODO
- 最小Run ID的从节点(字典顺序,ASCII码) // TODO
5.4.2 步骤2:群臣俯首(一朝天子一朝臣,换个码头重新拜)
- 执行slaveof no noe命令让选出来的从节点成为新的master,并通过slaveof命令让其他节点成为从节点
- Sentinel leader会对选举出的master执行slaveof no one操作,将其提升为master节点
- Sentinel leader向其他slave发送命令,让剩余的slave成为新的master节点的slave
5.4.3 步骤3:旧主拜服(老master回来也认怂)
- 将之前已下线的老master设置为新选出master的从节点,当老master重新上线后,它会成为新master的从节点
- Sentinel leader会让原来的master降级为slave并恢复正常工作
5.4.4 总结
上述的 failover操作均由sentinel自己独自完成,完全无需人工干预
6. 总结
Redis哨兵模式使用建议:
- 哨兵节点的数量应为多个,哨兵本身应该集群,保证高可用
- 哨兵节点的数量应该为奇数
- 各个哨兵节点的配置应为一致
- 如果哨兵节点部署在Docker等容器里面,尤其要注意端口的正确映射
- 哨兵集群+主从覅u之,并不能保证数据零丢失,故障迁移需要一定的时间
7. 参考和感谢
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringBoot分片上传、断点续传、大文件极速秒传功能
- 掌握C++核心:虚函数的原理与高效应用
- SpringBoot整合ElasticSearch实现CRUD操作
- 2024华数杯国际大学生数学建模A题思路+代码+模型+论文
- 调查过程之访谈
- Pandas实战100例 | 案例 72: 计算相关系数矩阵
- 获取域控权限的方法
- 三分钟学会cron 表达式
- Redis经典五大类型源码及底层实现(二)
- 华为OD机试真题-寻找身高相近的小朋友-Java-OD统一考试(C卷)