Java中HashMap与HashTable的区别
Java中 HashMap与HashTable的区别
HashMap 和 Hashtable 是 Java 中两种用于存储键值对的数据结构,它们之间有几个关键的区别:
- 线程安全性:
HashMap:是非线程安全的。多个线程可以同时修改HashMap,这可能导致不同步的访问。Hashtable:是线程安全的。Hashtable中的方法都是同步的,适用于多线程环境。
我们可以看到 Hashtable 源码中,很多就被 synchronized(同步的) 修饰符修饰,所以可以在多线程环境中安全运行。
public synchronized boolean contains(Object value) { ... }
public synchronized boolean containsKey(Object key) { ... }
public synchronized V get(Object key) { ... }
public synchronized V put(K key, V value) { ... }
public synchronized V remove(Object key) { ... }
... ...
HashMap 源码如下
public boolean containsKey(Object key) { ... }
public V put(K key, V value) { ... }
public V get(Object key) { ... }
public void putAll(Map<? extends K, ? extends V> m) { ... }
public V remove(Object key) { ... }
... ...
我们可以看到,在 HashMap 中,没有 synchronized 修饰,所以在多线程的情况下可能会产生问题,不建议在多线程使用。如果我们不需要同步且只是在单线程的情况下,那么 HashMap 的性能是要比 Hashtable 的性能要好的。从源码中我们可以看出,HashMap 大量使用的是位运算,而不是简单的乘除。
-
性能:
HashMap:由于不是线程安全的,因此在单线程环境下通常比Hashtable性能更好。Hashtable:由于需要维护同步,性能通常较差。在多线程环境中,可能需要使用Hashtable。
-
null 键值:
HashMap:允许键和值都为null,可以存储一个键为null的条目。Hashtable:不允许键和值为null,如果尝试插入null键或值,将抛出NullPointerException。
-
继承关系:
HashMap:继承自AbstractMap类,实现了Map接口。Hashtable:继承自Dictionary类,实现了Map接口,并被认为是遗留类。HashMap是继承自AbstractMap类,而Hashtable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
... ...
}
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
... ...
}
-
迭代器:
HashMap:通过迭代器或者 Java 8 中的 forEach 进行遍历。IteratorHashtable:通过迭代器进行遍历。Enumeration
-
初始容量和加载因子:
HashMap:可以设置初始容量和加载因子,以调整性能。默认初始容量为 16,加载因子为 0.75。Hashtable:默认初始容量为 11,加载因子为 0.75。加载因子是调整表的大小的阈值。
当达到临界值时,扩容机制不同,假设两者的当前容量都为 n,那么扩容后,Hashtable 扩容为 2n + 1,而 HashMap 扩容为 2n
临界值(threshold) = 容量(capacity) * 负载因子(loadFactor)
这里我们简单介绍一下什么是负载因子?
当我们不断向 HashMap 或者 Hashtable 中 put 元素时,可能会产生大量的哈希冲突,所以需要自动扩容。
以下是 Hashtable 的扩容源码。同样,当我们利用 HashMap 进行 put 元素到临界值时,HashMap
同样也会扩容。不论是在 Hashtable 还是在 HashMap,当对其进行扩容后,都必须将原先的元素分配到新的地方存储。
loadFactor 负载因子,表示 Hashtable 或者 HashMap 容量的饱满程度,默认的负载因子是 0.75,也就是说在 Hashtable 或者 HashMap 中元素容量到达 3/4 的时候开始扩容。
这里我们就会有疑惑,底层的数据结构不是 数组 + 链表 吗,根据 hash 算法可以一直链下去,也就是所谓的拉链法,那为什么还需要扩容呢?
这里就跟我们上面所说到的 哈希冲突 有关~
底层的数据结构 数组 + 链表 可以很好的化解一些哈希冲突问题,但是如果我们不进行扩容,我们 put 的元素越来越多,那么发生哈希冲突的概率就会越来越大,会从一开始的数组链表最后退化为链表,这时就导致查询速度降低。
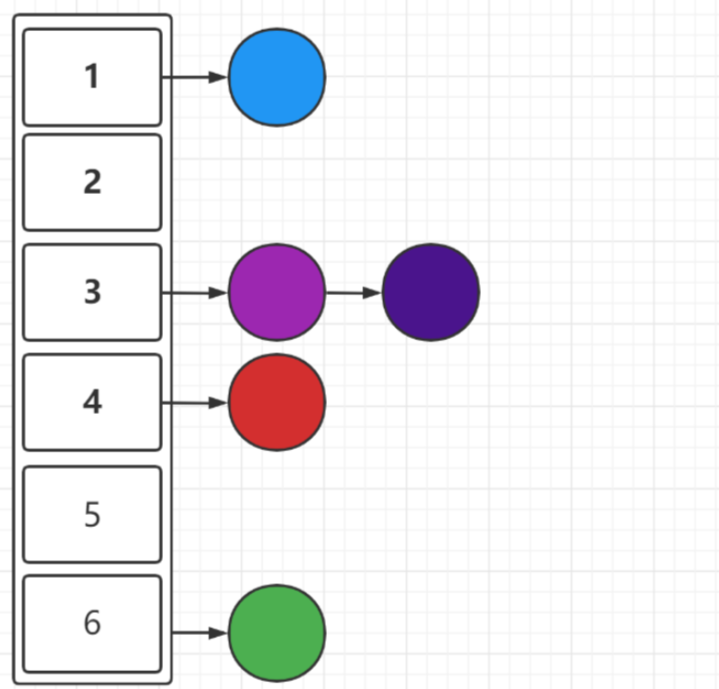
一开始,元素不多的情况下,如图所示:
- Fail-Fast 机制:
HashMap:支持 fail-fast 机制,当在迭代过程中修改了HashMap结构(除非通过迭代器自身的remove方法),将抛出ConcurrentModificationException异常。Hashtable:也支持 fail-fast 机制。
后来,元素慢慢增多,但是不进行扩容,如图所示
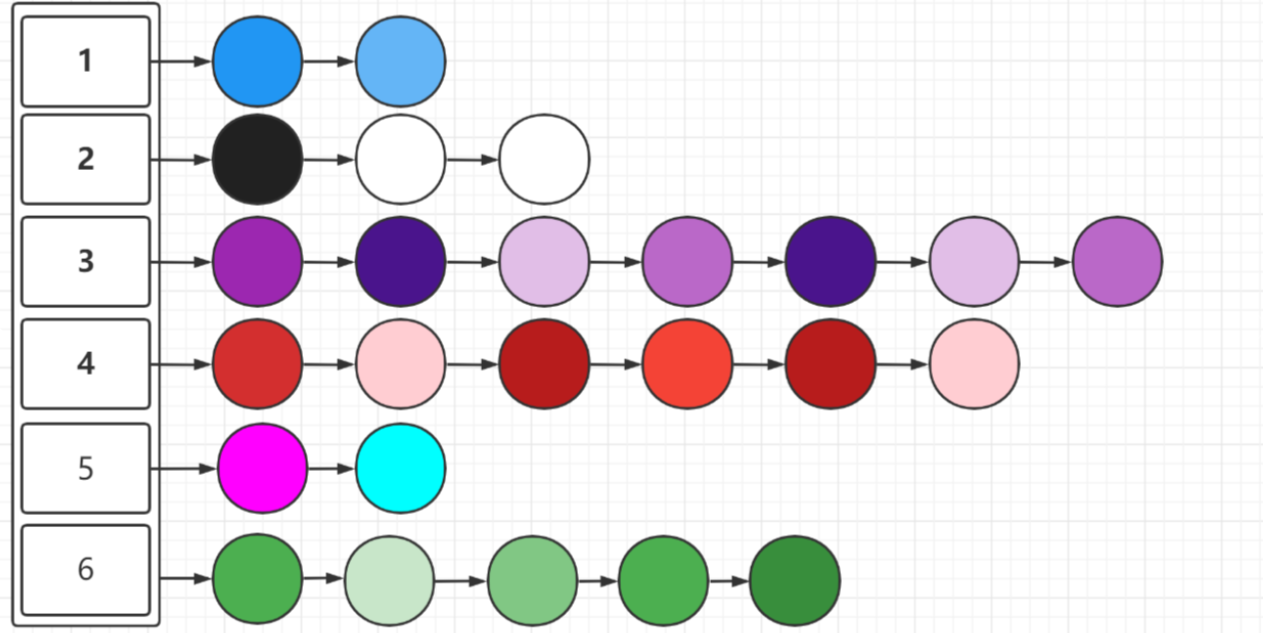
那么,我们应该如何改变这种情况呢?
- 优化 hash 算法(已优化)
- 扩大容量,降低碰撞概率
所以我们需要扩大容量,并在一个特定的临界值下。这样 loadFactor 负载因子就产生了~
那么负载因子的初始值为什么不是其他数值,而是 0.75 呢?
我们可以想到,负载因子不能太大,也不能太小。如果太大,会增加哈希冲突,如果太小,会浪费内存空间,所以经过官方的数学计算和统计,得到了一个在空间和成本上都比较权衡的数据,也就是
0.75,一般情况下,我们不建议去修改这个负载因子的默认值~
在计算 key 的 hash 值时,Hashtable 直接使用的是 hascode( ),HashMap 使用的是自定义的 hash( ) 算法
public synchronized V put(K key, V value) {
... ...
int hash = key.hashCode();
... ...
}
HashMap 源码如下
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
综上所述,一般情况下,推荐使用 HashMap,因为它的性能更好且在大多数应用场景中足够。如果需要线程安全性,也可以考虑使用 ConcurrentHashMap 或者在特殊情况下使用 Hashtable。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!