innodb底层原理和MySQL日志机制

server层
1. 连接器
客户端连接数据库需要输入账号、密码。连接器进行校验账号密码以及权限。
2. 查询缓存
连接器连接以后,比如输入一个select语句,这时候第一步就会先根据sql语句作为key给查询缓存中查看这条sql有没有已经被查询过,如果有直接返回,如果没有就接着到分析器。查询缓存是以key-value的形式存在的。
MySQL8版本是没有查询缓存的,因为存入缓存其实是很耗费性能的,比如一张表,当查询语句查询完成以后那么就会将对应的数据和sql放到查询缓存中,但是如果有其他操作需要更新这个表,就会将查询缓存删除掉,重新等待其他查询查完以后再放到缓存中,等到更新又删除,但是表如果不是那种字典表不经常修改数据的话,其他表就要频繁删除缓存,基本就相当于用不上查询缓存。而且缓存也有像redis这种。
查询缓存的三种策略设置
my.cnf
#query_cache_type有3个值 0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)代表当sql语句中有SQL_CACHE关键
词时才缓存
query_cache_type=23. 分析器

输入的sql语句分析器会进行分析,分析完成的sql会做成一个语法树。比如select * fro table; 其中应该是from但是输入了fro那么分析器就会分析出来语法不对。

4. 优化器
会根据sql进行优化,比如联合查询left 会决定执行那张表。比如会决定走不走索引,以及成本计算和成本比较决定走什么方式最好。
5. 执行器
调用搜索引擎,正式开始操作。但是之前会先判断有没有权限,如果走的查询缓存会在返回结果的时候校验权限。然后再去调用比如innodb搜索引擎
innodb
操作一条数据执行器操作innodb流程
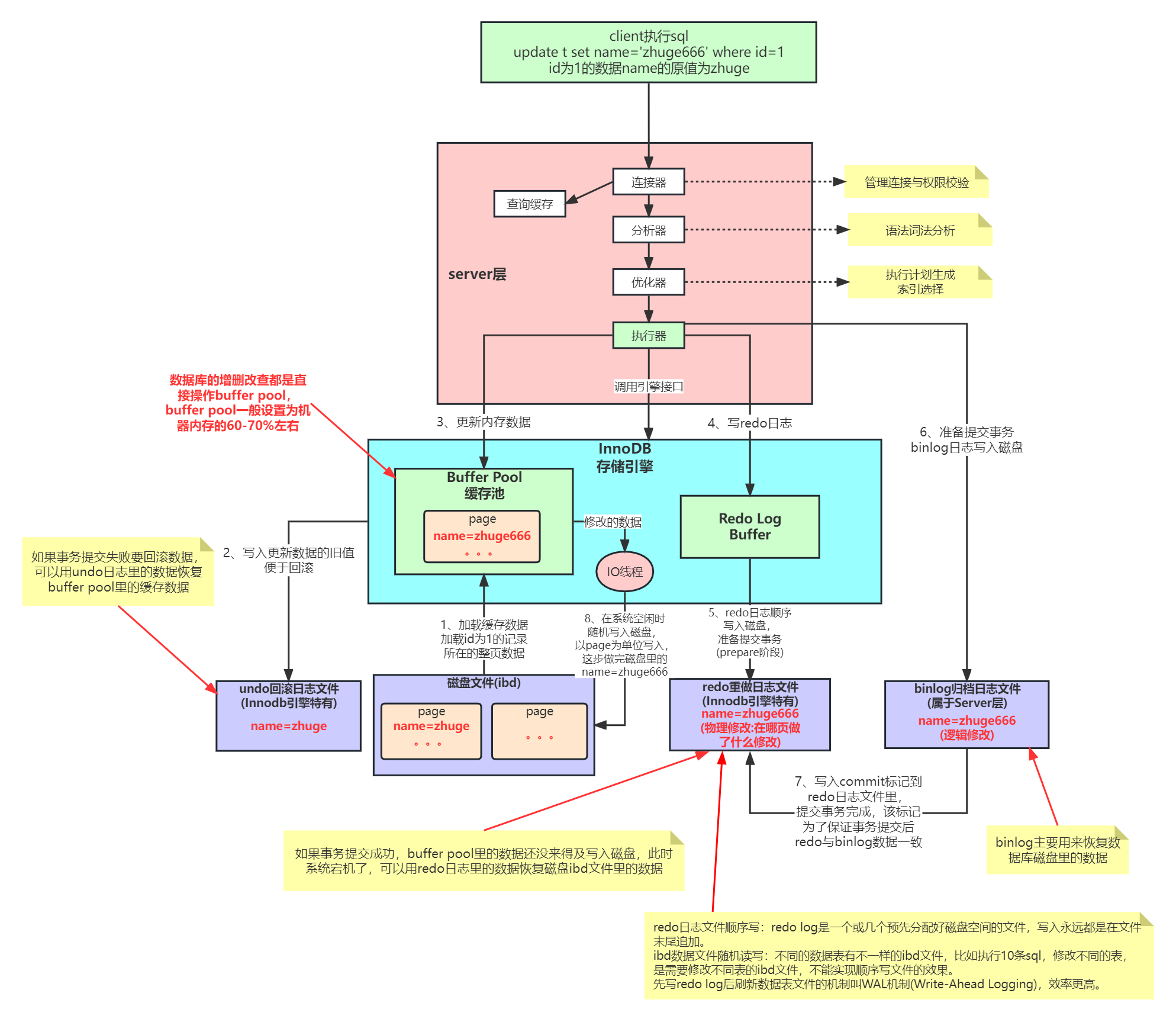
这个图片代表一整个更新语句的执行流程。
- 连接器校验权限和账号密码
- 进入到分析器分析语法的准确性
- 优化器 优化sql 成本计算
- 执行器调用innodb引擎
- 查询buffer pool中有没有该数据,如果没有从ibd磁盘文件中将这条数据对应的 一页数据拿出来(一页数据在b+tree是16 kb)放到缓存buffer pool
- 将更新前的旧址放到undolog 作用就是留作 回滚以及mvcc
- 更新内存的值 这时候并没有真正更新磁盘文件只是更新的缓存
- 更新redolog 先把数据更新到redolog对应的缓存中,再去顺序写到redolog磁盘文件中 方便持久化数据 即使提交数据 之后 数据库宕机ibd文件更新到最新数据也可以重启以后根据redolog恢复数据
- 更新binlog 方便恢复数据,比如不小心删除了数据可以根据binlog记录的sql日志恢复数据
- redolog 和 binlog都执行完成以后提交事务
- 系统空闲时就给ibd磁盘文件更新一次数据
undolog
用作日志版本链,方便回滚。以及mvcc做事务的隔离性。这个笔记有
此处为语雀内容卡片,点击链接查看:MySQL锁机制与优化实践 · 语雀
redolog
数据存储到这个文件是为了保证如果数据库宕机还能将buffer pool没更新到ibd文件的数据重新更新到磁盘中。
比如数据更新到redolog和binlog中这时候事务已经提交了,但是有一个线程是隔一段时间才会从buffer pool把新数据对应的一页数据更新到ibd文件,这时候还没有更新数据库宕机了。就会导致事务也提交了,ibd数据也没来得及更新。但是redolog是可以重启以后接着给ibd同步更新过的数据。
binlog
存储每一次执行的sql语句,能用做恢复数据。
比如不小心把表中数据删除了几行,这时候可以去这个文件将删除之前的sql语句跑一遍就能恢复
redolog的buffer 参数设置
innodb_log_buffer_size:设置redo log buffer大小参数,默认16M ,最大值是4096M,最小值为1M。
1 show variables like '%innodb_log_buffer_size%';
innodb_log_group_home_dir:设置redo log文件存储位置参数,默认值为"./",即innodb数据文件存储位置,其
中的 ib_logfile0 和 ib_logfile1 即为redo log文件。

1 show variables like '%innodb_log_group_home_dir%';
innodb_log_files_in_group:设置redo log文件的个数,命名方式如: ib_logfile0, iblogfile1... iblogfileN。默认2
个,最大100个。
1 show variables like '%innodb_log_files_in_group%';
innodb_log_file_size:设置单个redo log文件大小,默认值为48M。最大值为512G,注意最大值指的是整个 redo
log系列文件之和,即(innodb_log_files_in_group * innodb_log_file_size)不能大于最大值512G。
1 show variables like '%innodb_log_file_size%';
redolog写入磁盘的详细过程

redolog有好几个,其实他们是循环写的,当一个文件写满了设置的最大存储量,就会换另外一个,形成一个闭环,当都写满了就会前边清理之前数据,后面写着新数据。清理的数据其实都是已经让线程同步到ibd文件中数据。
write pos是代表需要新的数据写入的起始位置。
check point 代表需要删除的数据起始位置
当write pos 快要和check point 重叠时,check point 就会开始清除历史数据,清楚之前会让线程把这些清理的数据同步到ibd文件中。
redolog的写入策略设置
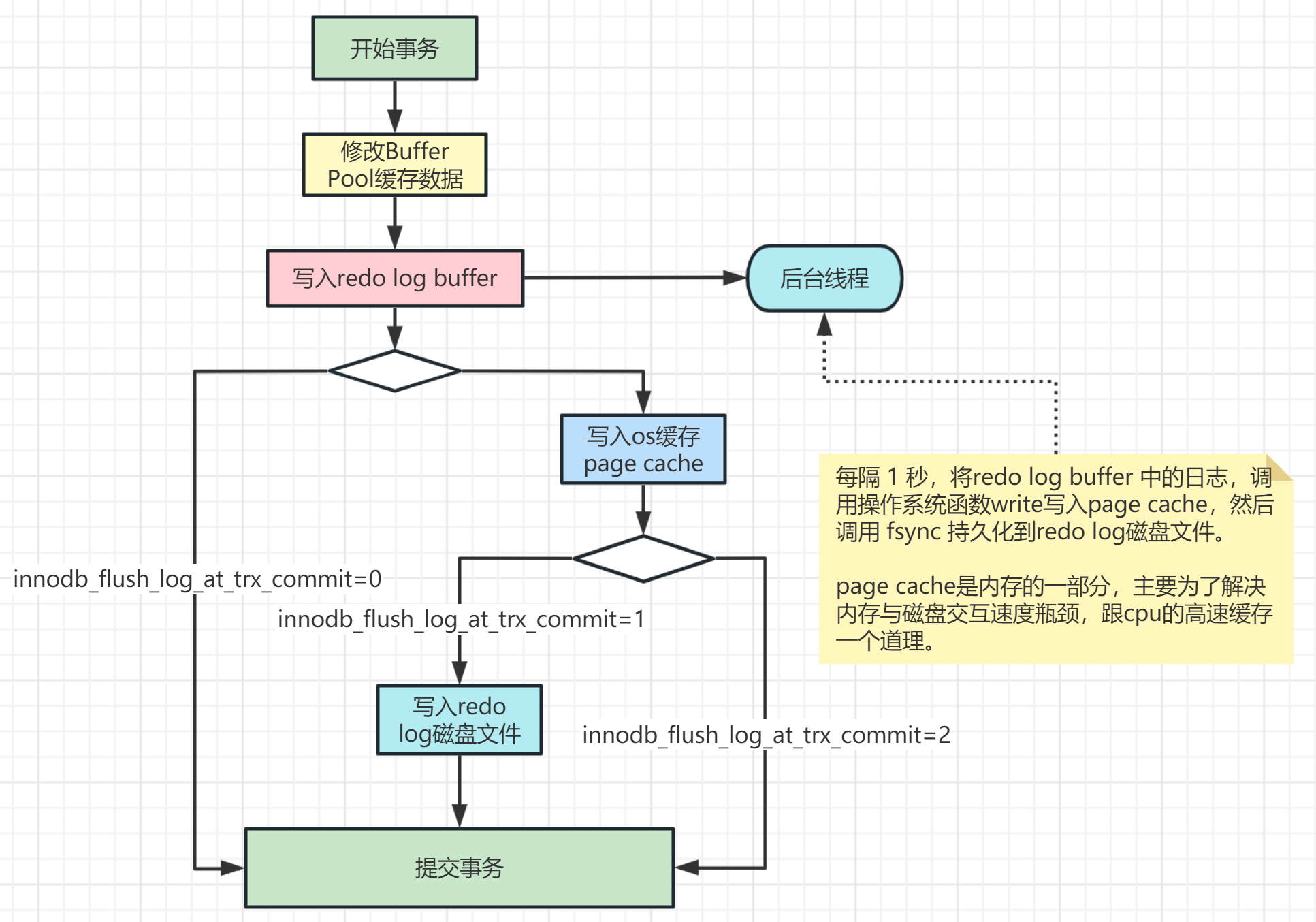
innodb_flush_log_at_trx_commit:这个参数控制 redo log 的写入策略,它有三种可能取值:
设置为0:表示每次事务提交时都只是把 redo log 留在 redo log buffer 中,数据库宕机可能会丢失数
据。
设置为1(默认值):表示每次事务提交时都将 redo log 直接持久化到磁盘,数据最安全,不会因为数据库
宕机丢失数据,但是效率稍微差一点,线上系统推荐这个设置。
设置为2:表示每次事务提交时都只是把 redo log 写到操作系统的缓存page cache里,这种情况如果数
据库宕机是不会丢失数据的,但是操作系统如果宕机了,page cache里的数据还没来得及写入磁盘文件的话就
会丢失数据。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 操作系统函数 write 写到文件系统的
page cache,然后调用操作系统函数 fsync 持久化到磁盘文件。
redo log写入策略参看下图:
binlog的文件内容记录三种格式
用参数 binlog_format 可以设置binlog日志的记录格式,mysql支持三种格式类型:
STATEMENT:基于SQL语句的复制,每一条会修改数据的sql都会记录到master机器的bin-log中,这种 方式日志量小,节约IO开销,提高性能,但是对于一些执行过程中才能确定结果的函数,比如UUID()、 SYSDATE()等函数如果随sql同步到slave机器去执行,则结果跟master机器执行的不一样。
ROW:基于行的复制,日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改记录下每一行数据修改的细节,可以解决函数、存储过程等在slave机器的复制问题,但这种方式日志量较 大,性能不如Statement。举个例子,假设update语句更新10行数据,Statement方式就记录这条update语句,Row方式会记录被修改的10行数据。
MIXED:混合模式复制,实际就是前两种模式的结合,在Mixed模式下,MySQL会根据执行的每一条具 体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种,如果sql里有函数或一些
在执行时才知道结果的情况,会选择Row,其它情况选择Statement,推荐使用这一种。
binlog写入磁盘的过程
binlog写入的方式比如是row方式,首先会将数据存储到操作系统(windows这种)中的page cache中,就自认为是完成了,就相当于是rabbitmq这种异步,生产者将数据丢给mq就认为自己已经成功了,这个是将数据丢给page cache中,每隔一段时间(时间看系统心情)会将page cache的数据刷到binlog文件中。
通过binlog数据恢复
# 查看bin‐log二进制文件(命令行方式,不用登录mysql)
mysqlbinlog ‐‐no‐defaults ‐v ‐‐base64‐output=decode‐rows D:/dev/mysql‐5.7.25‐winx64/data/mysql‐bi
nlog.000007
# 查看bin‐log二进制文件(带查询条件)
mysqlbinlog ‐‐no‐defaults ‐v ‐‐base64‐output=decode‐rows D:/dev/mysql‐5.7.25‐winx64/data/mysql‐bi
nlog.000007 start‐datetime="2023‐01‐21 00:00:00" stop‐datetime="2023‐02‐01 00:00:00" start‐
position="5000" stop‐position="20000"可以根据时间段来执行,也可以根据每一个SQL执行前后的上下文类似于上下文标识id一样去执行。
mysql的innodb这套机制这么复杂有什么好处呢?
- 首先可以顺序读写,直接将数据顺序写放到redolog中。
- 数据更新基本都是在缓存中的,比直接操作磁盘文件要快
顺序写是什么?
比如有 一个事务 需要对10张表进行10个sql语句的更新,如果直接更新到ibd磁盘文件,那么就会导致来回的找表,找到表再去更新,循环反复10次。
而MySQL的顺序写将操作记录到redolog中,将需要操作都一次往后写到redolog中就完事儿了,再有空余线程去执行buffer pool刷新到ibd磁盘文件。这样就性能很快,10个表10个更新只需要写到一个redolog文件即可
page cache是什么?
就是计算机的操作系统自己会有一个开辟的空间,目的是为了防止内存和磁盘频繁交互。可以将需要的操作放到page cache中,等到操作系统统一去执行。就类似于mq这种,生产者将数据直接丢到队列中就完事儿了,就认为操作成功了,其他事情不需要自己关系。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TS 类型断言
- 面试数据库八股文五问五答第四期
- 什么是 RFID 及其工作原理?
- 期货股市联动(期股联动助推资本市场上扬)
- 【Python&RS】基于矢量范围批量下载遥感瓦片高清数据(天地图、高德、谷歌等)
- LeetCode 50. Pow(x, n)
- MySQL_12.Innodb存储引擎参数
- 回归预测 | MATLAB实ZOA-LSTM基于斑马优化算法优化长短期记忆神经网络的多输入单输出数据回归预测模型 (多指标,多图)
- 抖音开始内测“AI 搜”功能;提示工程课程
- python_将字典按照列表的顺序进行排序