python爬虫进阶篇:利用Scrapy爬取同花顺个股行情并发送邮件通知
发布时间:2023年12月19日
一、前言
上篇笔记我记录了scrapy的环境搭建和项目创建和第一次demo测试。本篇我们来结合现实场景利用scrapy给我们带来便利。
有炒股或者其它理财产品的朋友经常会关心每日的个股走势,如果结合爬虫进行实时通知自己,并根据自己预想的行情进行邮件通知(比如某个股票如果到达100块钱就发邮件通知自己),这样会大大提高我们的炒股收益。
二、需求分析
- 目标网站:同花顺A股市场行情
- 目标数据:
- 股票代码
- 股票名称
- 股票价格
- 股票涨跌

三、代码实现
- 设置爬取的目标网页
def start_requests(self):
urls = [
"http://q.10jqka.com.cn/"
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
- 解析目标信息的网页结构
def parse(self, response):
# 股票代码列表
stock_id_list = response.css("div#maincont table.m-table.m-pager-table td:nth-child(2) a::text").extract()
# 股票名称列表
stock_name_list = response.css("div#maincont table.m-table.m-pager-table td:nth-child(3) a::text").extract()
# 股票价格列表
price_list = response.css("div#maincont table.m-table.m-pager-table td:nth-child(4)::text").extract()
# 股票涨跌列表
speed_up_list = response.css("div#maincont table.m-table.m-pager-table td:nth-child(6)::text").extract()
for i in range(len(stock_id_list)):
stock_id = stock_id_list[i]
stock_name = stock_name_list[i]
price = price_list[i]
speed_up = speed_up_list[i]
# 存到item,用来持久化
item = ScrapyDemoItem()
item["stock_id"] = stock_id
item["stock_name"] = stock_name
item["price"] = price
item["speed_up"] = speed_up
yield item
- 处理爬取的目标信息
- 将目标信息存储为html形式
def __init__(self):
self.html = '<html><head><meta charset="utf-8"></head><body><table>'
def process_item(self, item, spider):
self.html = self.html + '<tr>'
self.html = self.html + '<td>%s</td>' % item["stock_id"]
self.html = self.html + '<td>%s</td>' % item["stock_name"]
self.html = self.html + '<td>%s</td>' % item["price"]
self.html = self.html + '<td>%s</td>' % item["speed_up"]
self.html = self.html + '</tr>'
return item
def close_spider(self, spider):
self.html = self.html + '</table></body></html>'
self.send_email(self.html)
print()
- 发送邮件
结合之前写的python发邮件的知识点《Python:发送qq邮箱只需几行代码轻松搞定》,将html内容发送到邮箱中
def send_email(self, html):
# 设置邮箱账号
account = "xxx@qq.com"
# 设置邮箱授权码
token = "xxx"
# 实例化smtp对象,设置邮箱服务器,端口
smtp = smtplib.SMTP_SSL('smtp.qq.com', 465)
# 登录qq邮箱
smtp.login(account, token)
# 添加正文,创建简单邮件对象
email_content = MIMEText(html, 'html', 'utf-8')
# 设置发送者信息
email_content['From'] = 'xxx@qq.com'
# 设置接受者信息
email_content['To'] = '技术总是日积月累的'
# 设置邮件标题
email_content['Subject'] = '来自code_space的一封信'
# 发送邮件
smtp.sendmail(account, 'xxx@qq.com', email_content.as_string())
# 关闭邮箱服务
smtp.quit()
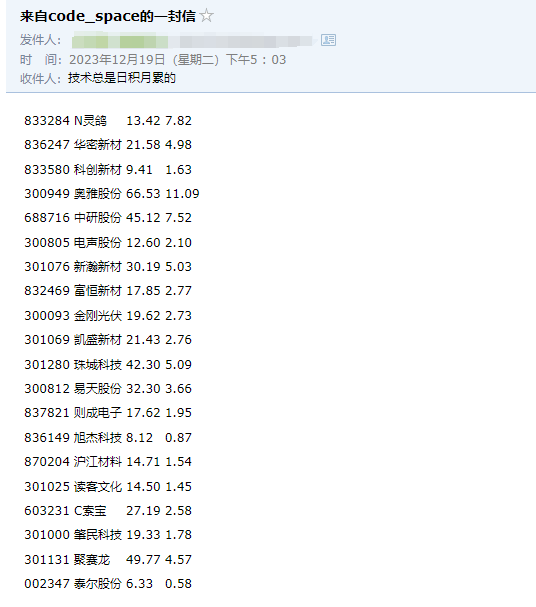
四、拓展
Scrapy是个很好用的框架,结合日常生活中的需求,我们可以写很多给我们带来便利的工具,以后会补上各种我多年来使用过的工具代码,都是基于Scrapy的使用。
文章来源:https://blog.csdn.net/qq_23730073/article/details/135089451
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 连接本机MongoDB报错MongoNetworkError/MongooseServerSelectionError
- 手写操作系统 - 操作系统内核突破512字节
- shell 如何调用多个脚本
- 软件测试基础理论学习-软件测试方法论
- Elasticsearch资源分配
- D1302 高性能、低功耗并附带RAM的涓流充电实时时钟电路芯片
- 如何在页面中加入百度地图
- Pandas.DataFrame.iloc[ ] 筛选数据-自然索引法 详解 含代码 含测试数据集 随Pandas版本持续更新
- Qt5.14.2实现将html文件转换为pdf文件
- 探讨芯片封装的技术、工艺以及与之相关的知识