Raft算法
发布时间:2024年01月24日
Raft 算法是一种通过对日志复制管理来达到集群节点一致性的算法。这个日志复制管理
发生在集群节点中的 Leader 与 Followers 之间。Raft 通过选举出的 Leader 节点负责管理日志
复制过程,以实现各个节点间数据的一致性。
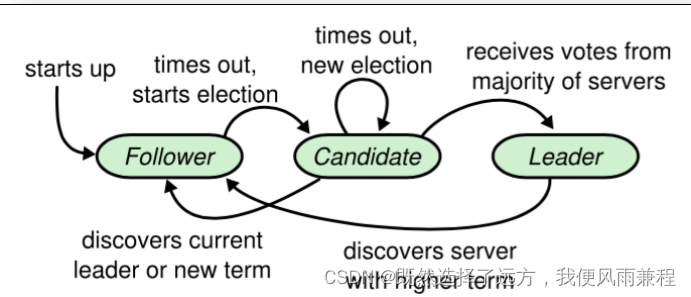
在 Raft 中,节点有三种角色:
- Leader:唯一负责处理客户端写请求的节点;也可以处理客户端读请求;同时负责日志
复制工作 - Candidate:Leader 选举的候选人,其可能会成为 Leader。是一个选举中的过程角色
- Follower:可以处理客户端读请求;负责同步来自于 Leader 的日志;当接收到其它
Cadidate 的投票请求后可以进行投票;当发现 Leader 挂了,其会转变为 Candidate 发起
Leader 选举
leader 选举
(1) 我要选举
若 follower 在心跳超时范围内没有接收到来自于 leader 的心跳,则认为 leader 挂了。此
时其首先会使其本地 term 增一。然后 follower 会完成以下步骤:
- 此时若接收到了其它 candidate 的投票请求,则会将选票投给这个 candidate
- 由 follower 转变为 candidate
- 若之前尚未投票,则向自己投一票
- 向其它节点发出投票请求,然后等待响应
(2) 我要投票
follower 在接收到投票请求后,其会根据以下情况来判断是否投票: - 发来投票请求的 candidate 的 term 不能小于我的 term
- 在我当前 term 内,我的选票还没有投出去
- 若接收到多个 candidate 的请求,我将采取 first-come-first-served 方式投票
(3) 等待响应
当一个 Candidate 发出投票请求后会等待其它节点的响应结果。这个响应结果可能有三
种情况: - 收到过半选票,成为新的 leader。然后会将消息广播给所有其它节点,以告诉大家我是
新的 Leader 了 - 接收到别的 candidate 发来的新 leader 通知,比较了新 leader 的 term 并不比自己的 term
小,则自己转变为 follower - 经过一段时间后,没有收到过半选票,也没有收到新 leader 通知,则重新发出选举
(4) 选举时机
在很多时候,当 Leader 真的挂了,Follower 几乎同时会感知到,所以它们几乎同时会变
为 candidate 发起新的选举。此时就可能会出现较多 candidate 票数相同的情况,即无法选举
出 Leader。
为了防止这种情况的发生,Raft 算法其采用了 randomized election timeouts 策略来解决
这个问题。其会为这些 Follower 随机分配一个选举发起时间 election timeout,这个 timeout
在 150-300ms 范围内。只有到达了 election timeout 时间的 Follower 才能转变为 candidate,
否则等待。那么 election timeout 较小的 Follower 则会转变为 candidate 然后先发起选举,一
般情况下其会优先获取到过半选票成为新的 leader。
数据同步
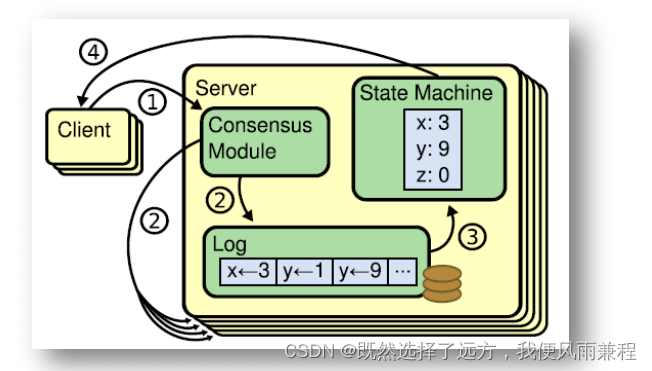
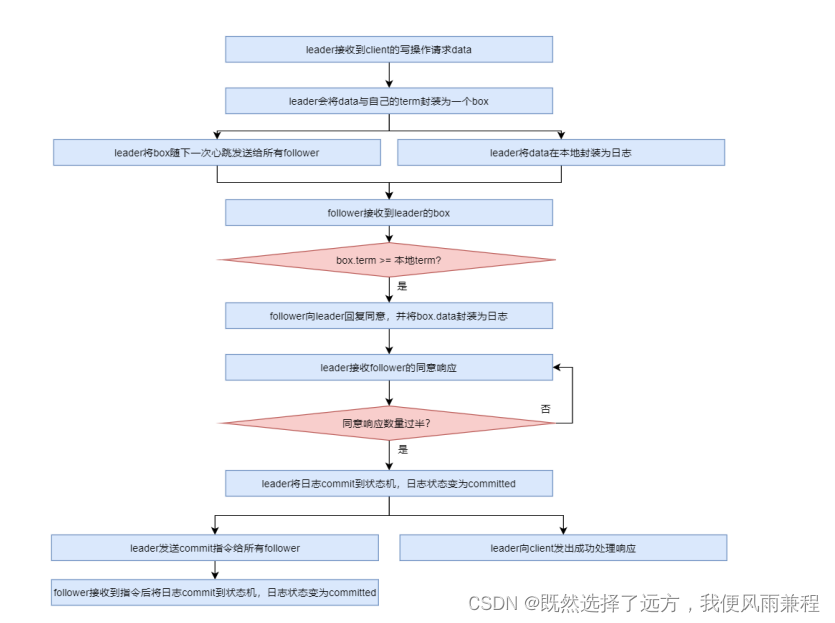
Raft 算法的动画,其非常清晰全面地演示了 Raft 算法的工作原理。
该动画的地址为:Raft
文章来源:https://blog.csdn.net/jingzhou111/article/details/135813097
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux用bash写脚本
- DSC2803X,DSP Pin2Pin with Ti Parts
- 【昕宝爸爸小模块】深入浅出之并发并行
- 《设计模式的艺术》笔记 - 代理模式
- Java字符串:构建和操作字符序列的动态工具
- react 事件函数中 this 绑定问题
- 定制 Electron 窗口标题栏
- Activiti7工作流引擎:Pool + Lane
- 力扣hot100 两数相加 链表 思维
- spring boot支付宝沙箱环境测试支付功能