【论文阅读笔记】SegVol: Universal and Interactive Volumetric Medical Image Segmentation
Du Y, Bai F, Huang T, et al. SegVol: Universal and Interactive Volumetric Medical Image Segmentation[J]. arXiv preprint arXiv:2311.13385, 2023.[代码开源]

【论文概述】
本文思路借鉴于自然图像分割领域的SAM,介绍了一种名为SegVol的先进医学图像分割模型,旨在构建一种图像分割基础模型,这是一个面向体积医学图像分割的通用和交互式模型。SegVol的设计目的是通过处理各种解剖类别来提高医学图像分割的准确性和效率。该模型通过在9万个未标记的计算机断层扫描(CT)体积和6千个标记的CT体积上进行训练,能够支持超过200个解剖类别的分割,模型利用语义和空间prompts来实现。SegVol通过使用轻量级架构实现高效率,采用**“缩小-放大”机制减少计算成本**,同时能保持精确的分割。通过一系列实验,SegVol在多个分割基准测试中展现出卓越性能,尤其在复杂病变数据集上的表现显著超过现有先进模型如nnU-Net。
【一.Introduction总结】
这篇论文的Introduction写得很好,提供了对SegVol模型背景、动机、特点和性能的全面概览,这里特别总结如下:
- 体积医学图像分割的重要性:论文首先强调体积图像分割在医学图像分析中的重要作用,特别是在提取感兴趣区域(如器官、病变和组织)方面。体积分割对于多种临床应用至关重要,包括肿瘤监测、手术规划、疾病诊断和治疗优化等。
- 现有研究的局限性:尽管在医学图像分割方面取得了显著进展,但现有的解决方案仍存在关键限制,特别是在处理复杂任务(如肝脏肿瘤或结肠癌分割)和实际任务(如交互式分割)方面。现有模型通常受到可用数据集大小和类别差异性的限制,难以泛化到不同的数据集。此外,传统模型在分割复杂结构(如肿瘤和囊肿)时性能不佳,主要是因为数据不足和无法通过用户交互利用空间信息。最后,现有解决方案在推理过程中计算成本高,通常采用滑动窗口方法进行推理,这不仅耗时,而且由于仅包含局部信息而视野狭窄。
- SegVol模型的介绍:为了克服上述限制,论文引出了SegVol——一种通用且交互式的体积医学图像分割模型。SegVol旨在分割200多种解剖类别,准确分割器官、组织和病变。该模型基于轻量级架构构建,确保其在实际医学图像分析中的高效性。
- SegVol的关键特性:论文概述了SegVol的几个关键特点:
- 预训练:在96k CT体积上进行预训练,并利用伪标签减少数据集和分割类别之间的虚假相关性。
- 文本提示分割:集成语言模型,通过在25个数据集的200多个解剖类别上的训练,实现文本提示分割。
- 语义和空间提示的协同策略:通过协调语义提示和空间提示,实现高精度分割。
- 缩小-放大机制:显著降低计算成本,同时保留精确分割。
- 性能评估:SegVol在多个分割数据集上进行了广泛评估,主要涉及重要解剖类别的实验,展示了其通用分割能力,并与四种最先进方法进行了比较,显示出其显著优势,特别是在难分割的类别中。
【二.数据处理】
数据预处理
本文收集了25个开源数据集,首先基于每个Voxels的平均体素值计算一个阈值。高于此阈值的体素被视为前景。计算前景体素的99.95百分位和0.05百分位,并将其作为剪切原始体素的上下界,进一步使用均值和标准偏差对前景体素进行归一化。
伪掩模生成和去噪
大多数数据集仅具有少数分割目标的注释,例如几个器官。因此,深度模型可能会学习数据集和分割目标之间的虚假相关性,并在推理阶段产生较差的结果。论文使用经典FH算法先产生伪mask,但由于FH产生的伪mask可能含有噪声或者错误,本文采取以下策略进一步处理:1)在应用时,伪掩码被替换为ground-truth掩码。2)过滤掉小于整个体积的1‰的微小结构。3)对每个mask进行膨胀和腐蚀操作。
论文中用于预处理的FH分割算法,这里补充概述一下:“FH algorithm”指的是Felzenszwalb和Huttenlocher提出的图像分割算法。这种算法是一种用于分割数字图像的高效且有效的方法。其核心思想是将图像视为一个图(graph),其中像素代表节点,而节点之间的边代表像素之间的相似度。算法的目的是将图像分割成多个区域,这些区域内部的像素在某种意义上是相似的,而不同区域的像素则具有较大差异。
FH算法的主要特点包括:
1.基于图的表示:算法将图像表示为图,其中图中的每个节点对应一个像素,节点之间的边表示像素间的相似性。
2.分段准则:算法使用特定的准则来决定是否将图中的两个相邻节点(即两个像素)划分到同一个分割区域。这通常涉及比较节点间的相似性(如颜色、亮度或纹理)和预设的阈值。
3.效率:该算法以其计算效率而闻名,能够快速处理大型图像,使其适合于各种应用。
4.灵活性和广泛适用性:尽管该算法最初是为一般图像分割设计的,但它可以通过调整参数适应不同类型的图像和特定的分割需求。
在医学图像处理领域,这种类型的算法可能被用于生成伪标签或辅助标记,从而帮助训练更复杂的模型(如SegVol),尤其是在标记数据稀缺的情况下。通过使用这些伪标签,可以增强模型对未标记数据的理解,从而提高其在实际医学应用中的性能和准确性。
【三.模型结构】
模型结构图:
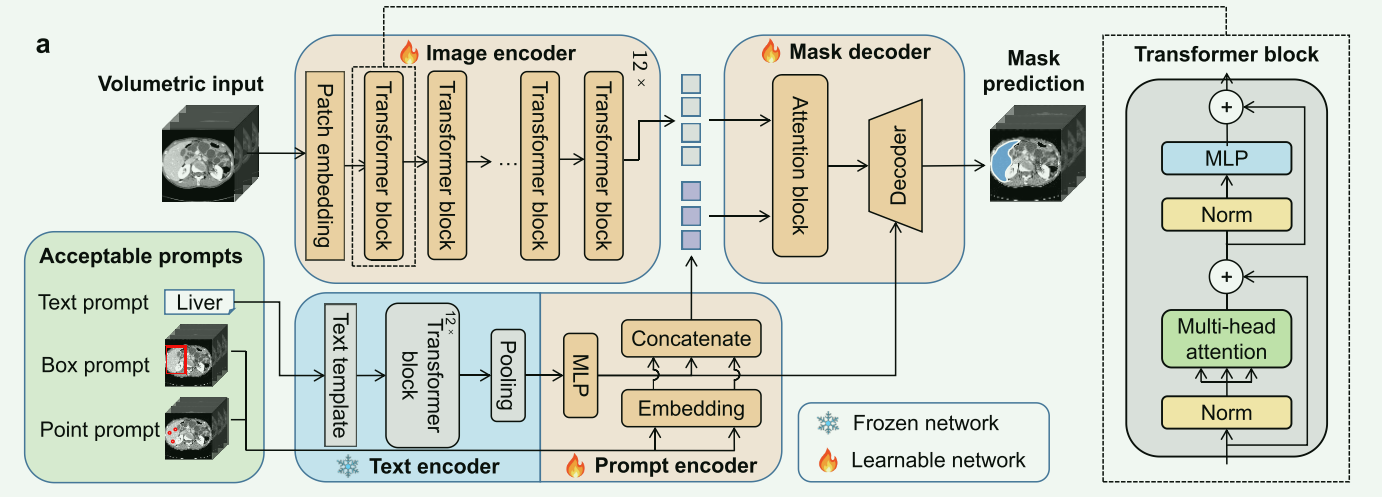
a. SegVol的主要结构包括图像编码器、文本编码器、提示编码器和mask解码器。除了文本编码器外,所有网络都是可学习的。图像编码器提取体积输入的图像嵌入。图像嵌入与提示嵌入一起输入到解码器中,以预测分割mask
具体组成的各部分概述如下:
- Image encoder
使用VIT,以MAE方式先在96k CTs上自监督训练,然后在6k CT,带有150k标记mask的数据上监督训练。(p.s 这一步就耗费很大了)
-
Text prompt encoder
直接使用CLIP模型对输入的prompts编码,给定一个单词或短语作为提示,使用模板s ='A computerized tomography of a [text prompt]'撰写prompts。然后将 s s s标记化为 t t t。文本编码器接受 t t t作为输入并输出文本嵌入。(p.s直接上多模态模型)
-
Spatial prompt encoder
借鉴SAM,使用了point prompts,box prompts,分别编码为embedding,然后和上一步的文本prompts embeddings 拼接: z prompt? = F P E ( p , b , s , θ P E ) = [ z point? , z box? , z text? ] . \boldsymbol{z}_{\text {prompt }}=\mathcal{F}_{\mathrm{PE}}\left(\boldsymbol{p}, \boldsymbol{b}, \boldsymbol{s}, \boldsymbol{\theta}_{\mathrm{PE}}\right)=\left[\boldsymbol{z}_{\text {point }}, \boldsymbol{z}_{\text {box }}, \boldsymbol{z}_{\text {text }}\right] . zprompt??=FPE?(p,b,s,θPE?)=[zpoint??,zbox??,ztext??].
-
Mask decoder
解码器设计稍微比常规的多了一些:使用自注意力和交叉注意力在两个方向上融合图像嵌入和提示嵌入,然后采用转置卷积和插值操作来生成mask。由于文本嵌入是实现通用分割的关键,并且学习文本与体积区域之间的关联也更为困难,通过在联合提示嵌入 z prompt? \boldsymbol{z}_{\text {prompt }} zprompt??旁引入一个平行的文本输入 z text? \boldsymbol{z}_{\text {text }} ztext??来增强文本信息。进一步在mask解码器中计算转置卷积输出的上采样嵌入与文本嵌入之间的相似度矩阵。在插值之前,将相似度矩阵与mask预测的逐元素乘法应用于模型,之后模型输出mask。
【四.训练方法】
-
Prompt generation
模型支持point、box、text prompts及他们的混合prompts。
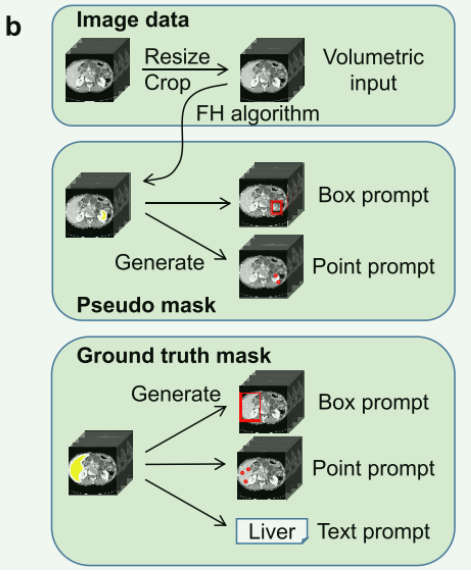
b. 输入图像转换和提示生成的示意图。 - 点提示(Point Prompt):
- 点提示由三种类型的点构成:正点(positive point)、负点(negative point)和忽略点(ignore point)。
- 正点位于目标遮罩区域内,表明这些点属于感兴趣的解剖结构。
- 负点位于目标遮罩区域外,表明这些点不属于感兴趣的结构。
- 忽略点用于输入的完整性,这些点会被模型忽略,确保点提示的长度一致。
- 点提示是基于真实或伪标注的遮罩(由专业标注或如FH算法产生的伪标注)构建的。
- 框提示(Box Prompt):
- 框提示也是基于真实或伪遮罩生成的,但结合随机抖动,以提高模型的鲁棒性。
- 在为某个伪遮罩生成框提示时,由于不规则的3D形状,框可能会覆盖其他遮罩。
- 为解决这个问题,计算生成的框与包含的伪遮罩之间的交集比(Intersection over Union, IOU)。
- 如果任何遮罩的IOU大于0.9,它也会被集成并视为该框提示对应的目标遮罩的一部分。
- 小结:
- 点提示和框提示可以通过基于真实分割遮罩的点采样来生成。
- 文本提示是基于它们的类别名称构建的。
- 由于非监督的FH算法产生的伪遮罩没有语义信息,因此在使用伪遮罩进行训练时,只使用点提示和框提示。
- 点提示(Point Prompt):
-
损失函数
binary cross-entropy (BCE) loss 和 Dice loss
【五.Zoom-out-zoom-in Mechanism】
这是本文的主要创新点之一,这里稍微详细一点记录一下
-
设计动机
zoom-out-zoom-in机制的设计动机源于处理体积医学图像分割时面临的几个关键挑战:
- 高计算成本:体积医学图像(如CT或MRI扫描)通常包含大量的体素(三维像素),这导致分割这些图像在计算上非常昂贵。传统的分割方法,如滑动窗口技术,虽然可以降低计算负荷,但仍然耗时且效率不高。
- 保持细节信息:在降低图像分辨率以减少计算负担的同时,有必要保持足够的细节信息,以确保分割的准确性。特别是对于较小的或边缘不清的结构,如小肿瘤或细小的解剖结构,保持细节尤为重要。
- 全局和局部信息的平衡:有效的医学图像分割需要同时考虑全局结构(整个器官或身体部位)和局部细节(特定病变或特定解剖特征)。传统方法在处理这两方面信息时往往存在权衡。
基于这些挑战,Zoom-out-zoom-in机制被设计出来,其目标是:
- 提高效率:通过首先在较低分辨率(缩小视图)处理整个图像,快速确定感兴趣区域(ROI),从而减少在高分辨率(放大视图)下需要处理的数据量。
- 保持精确性:在确定了ROI之后,只对这些区域进行高分辨率处理,确保关键细节的准确性和完整性。
- 全局与局部的协调:通过结合全局视图(提供上下文信息和整体结构)和局部视图(提供细节信息),Zoom-out-zoom-in机制在提高效率的同时保持了分割的准确性和细节丰富度。
因此,Zoom-out-zoom-in机制是对现有体积医学图像分割方法的一种重要改进,它使得处理大规模医学图像数据集变得既高效又准确。
-
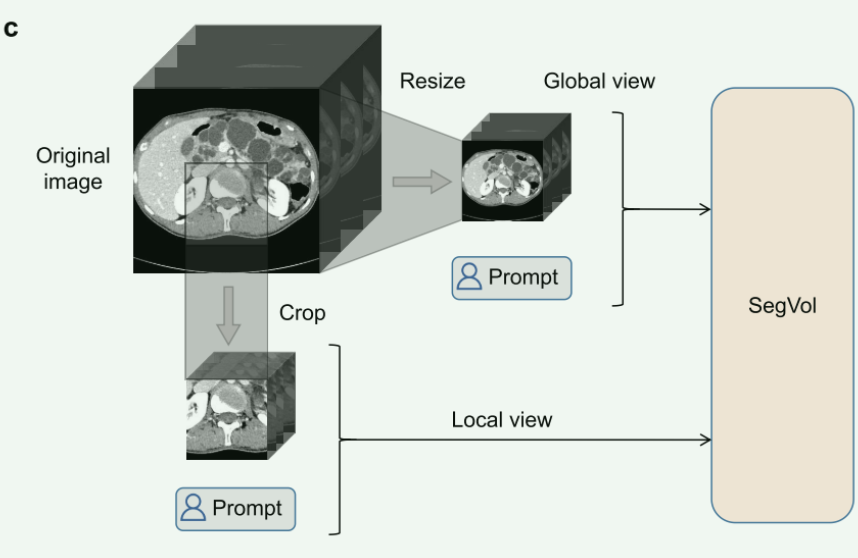
Multi-view training
为了适应不同大小的体数据,并使放大缩小推理,构造了两种训练数据。一种是对大尺寸CT进行缩放以适应模型的输入尺寸,并获得缩小视图的训练数据;另一种方法是将原始的大尺寸CT裁剪成模型输入尺寸的立方体。通过这种方式,获得了放大视图的训练数据。该过程如图C所示。
-
Zoom-out-zoom-in Inference
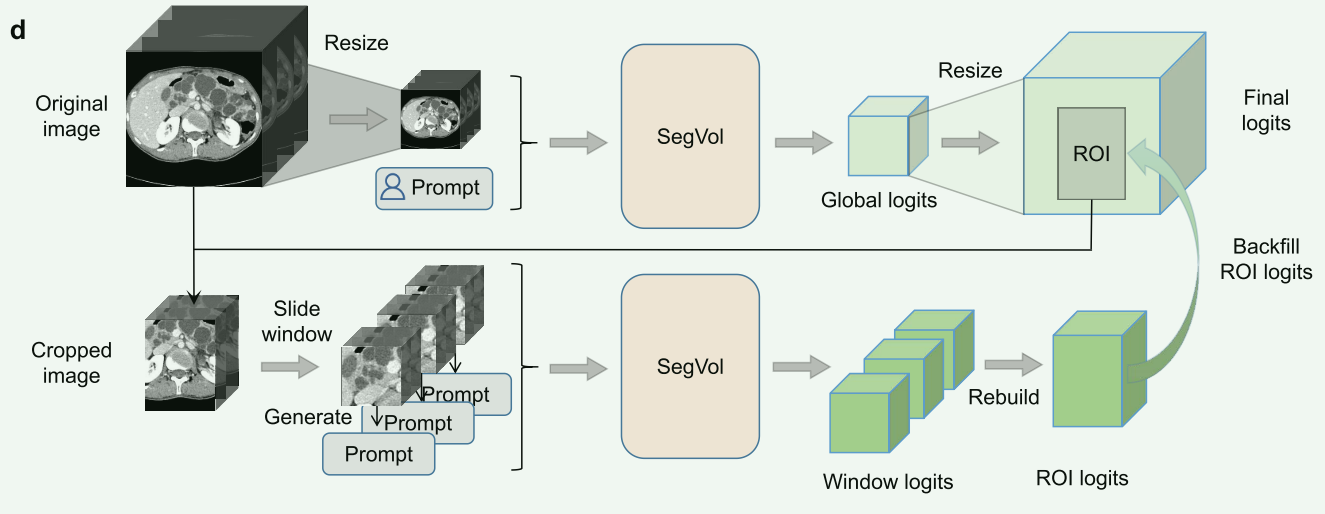 d. 缩小-放大推理:SegVol首先进行全局推理,然后对提取的感兴趣区域(ROI)进行局部推理,以优化结果。
d. 缩小-放大推理:SegVol首先进行全局推理,然后对提取的感兴趣区域(ROI)进行局部推理,以优化结果。步骤总结如下:
-
Zoom-out和全局推理:
- 首先,对大型体积图像进行缩小处理,即降低其分辨率以便于处理。
- 缩小后的图像被输入到SegVol模型中进行全局推理。
- 在全局推理阶段,模型基于用户提供的提示(如文本提示、点提示或框提示)生成全局预测的分割遮罩。
-
定位感兴趣区域(ROI)并Zoom-in:
- 根据全局预测结果,确定感兴趣的区域(ROI)。
- 对这些区域进行放大处理,即从原始尺寸的图像中裁剪出这些区域。
-
应用滑动窗口进行局部推理:
- 在放大的ROI上应用滑动窗口技术,以执行更精确的局部推理。
- 为了适应局部推理,对输入的提示进行调整。当放大时,原始的点提示和框提示可能不再适用于局部区域,因此会忽略位于局部区域外的正点或负点。
-
生成局部框提示:
- 类似于训练中的框提示生成,局部框提示是基于全局预测遮罩在局部区域内视为伪遮罩来生成的。
-
填充并输出最终结果:
- 最后,将局部推理得到的分割遮罩填充到全局分割遮罩的相应ROI区域中。
- 这样,Zoom-out-zoom-in机制同时实现了高效和精确的推理。
总体来说,这一机制通过首先进行快速的全局分析,然后对关键区域进行更详细的局部分析,有效地平衡了处理速度和分割精度。
-
【六.数据集】
这里就贴图了,不做太多解释。从医学开源数据集中收集了25个CT图像分割数据集,形成了一个综合数据集,涵盖了CT图像分割中的各种热点问题。收集的综合数据集包括四个主要人体区域:头颈部、胸部、腹部和骨盆,包含47个重要区域中的200多个器官、组织和病变类型。共有5772个CT参与了该综合数据集的训练和测试,总共有149199个带有语义的体积mask标签。第二个图展示了来自四个主要人体区域的综合数据集样本,以2D切片形式呈现。为了增强SegVol的空间分割能力,执行了FH算法以生成510k个伪体积mask标签,用于填补这些实例中未标注的区域。此外,为了构建通用的体积医学图像特征提取器,收集了90k个未标注的开源CT进行预训练。这些数据和标注构成了SegVol的基础。
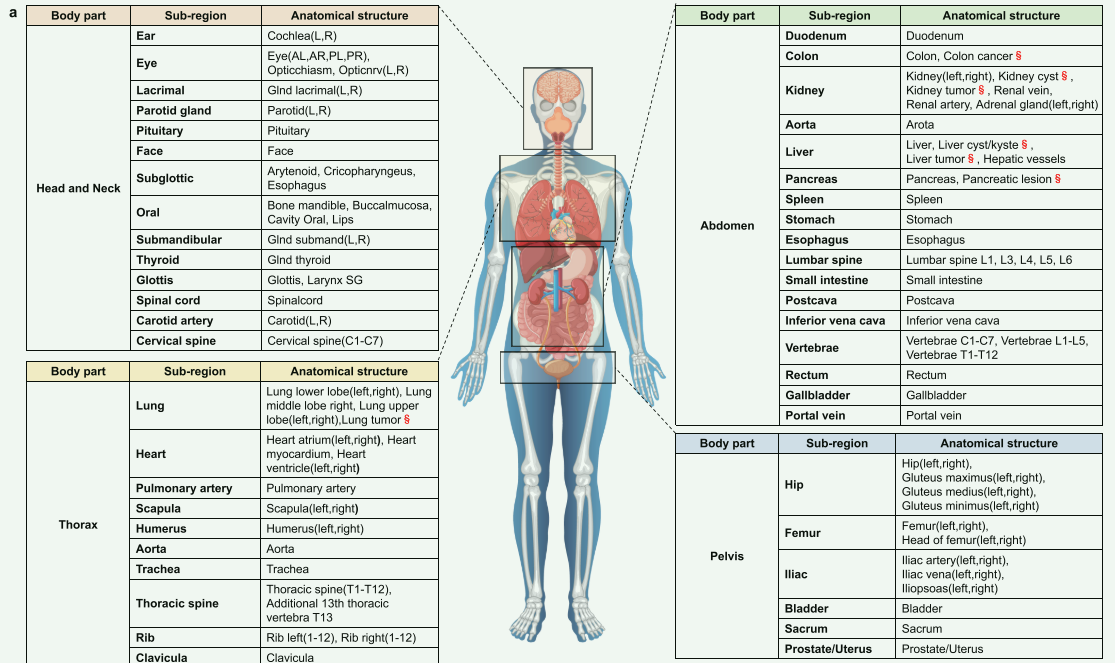
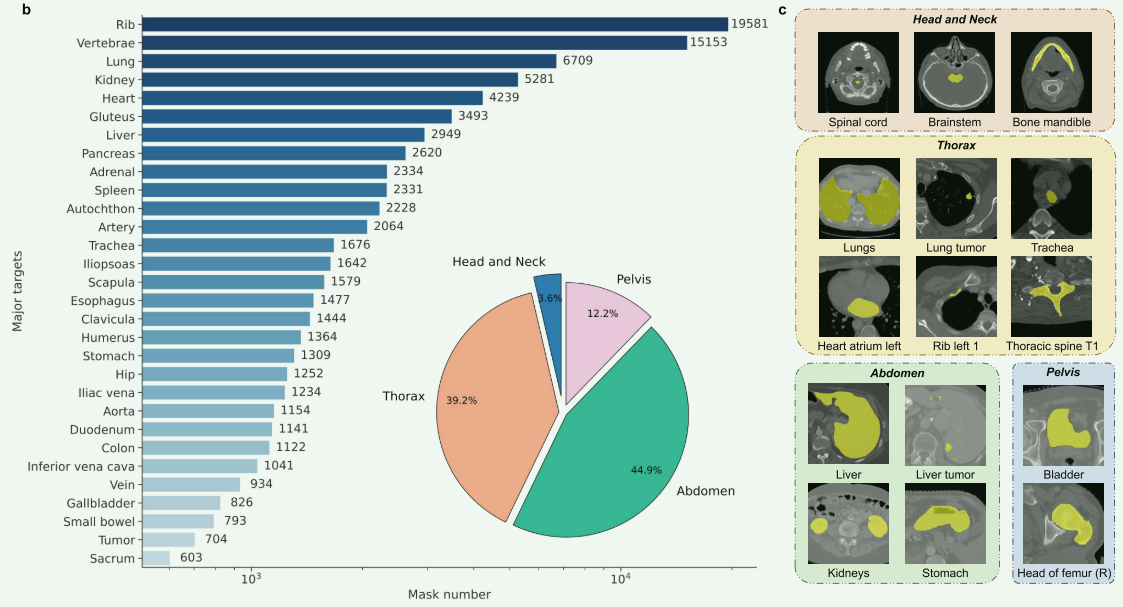
联合数据集的概述和示例。A.联合数据集概述。联合数据集包括47个重要区域,每个区域包含该空间区域内的一个或多个重要解剖结构。B.关节数据集的主要类别:其掩码标签数量排名前30位,以及人体四个主要部位的掩码标签计数在关节数据集中所占的比例。C.从关节数据集中采样的15个不同类别的器官、组织和病变的示例,以切片视图呈现。
【七.性能】
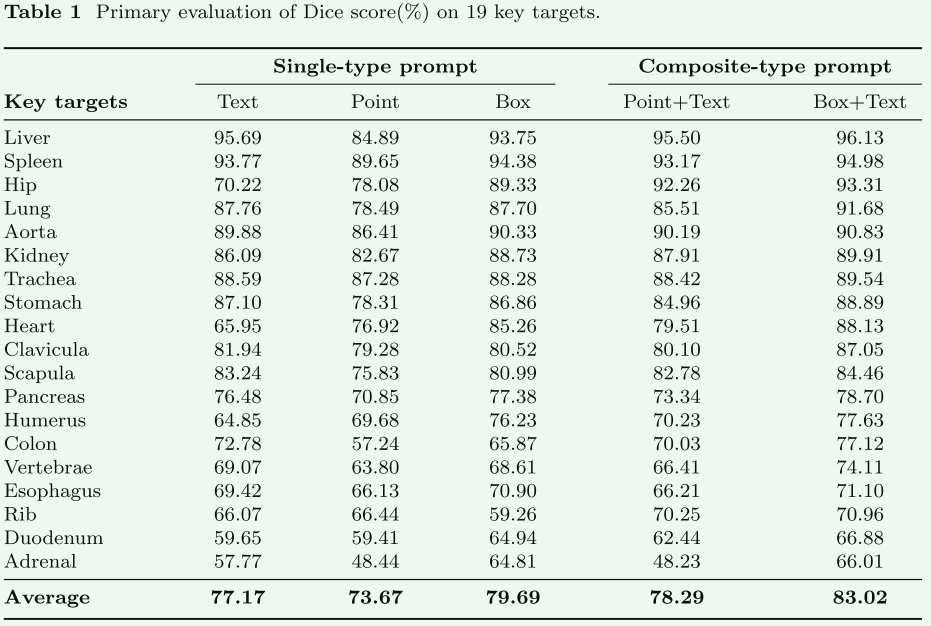
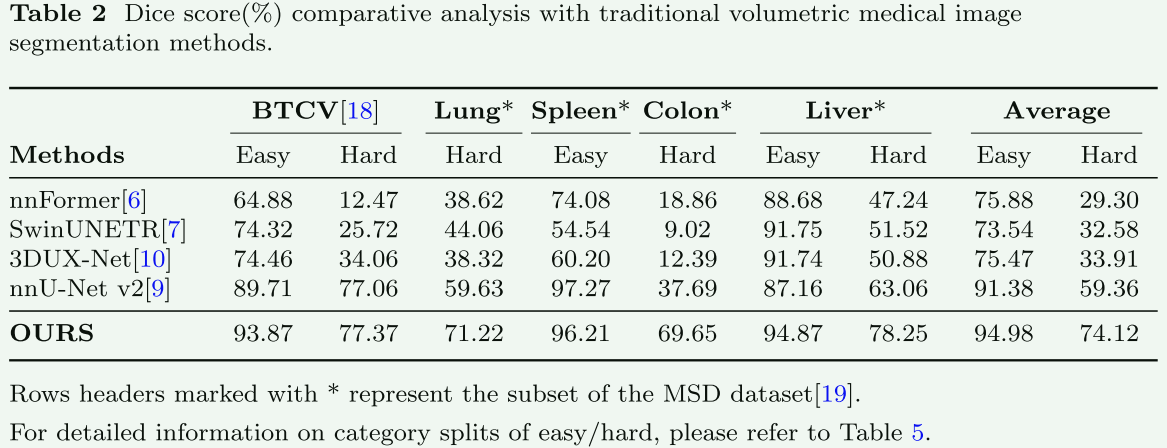

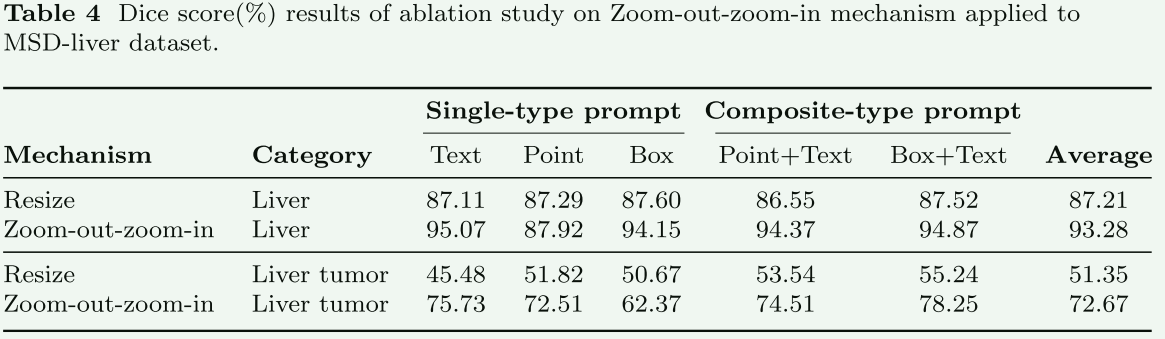
box prompts比point更加有效,组合的比单一的有效,增加Zoom操作涨点
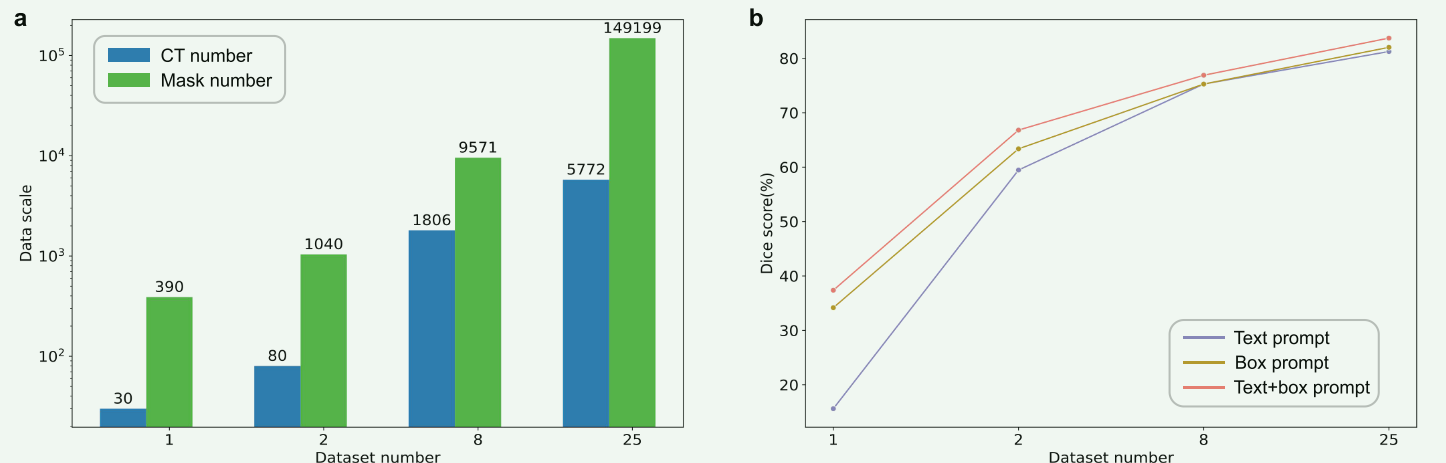
多模态大模型的共性,数据量增长,性能也在持续增长
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 街机模拟游戏逆向工程(HACKROM)教程:[7]68K汇编寄存器
- 在CentOS 7中wordpress的HTTPD方式部署
- HarmonyOS组件属性控制 链式编程格式推荐
- 【TC3xx芯片】TC3xx中断路由IR模块详解
- 第五章 与HTTP协作的Web服务器
- 网络工程师必懂-数据在网络上的转发过程
- 【算法】使用优先级队列(堆)解决算法题(TopK等)(C++)
- [C/C++]——内存管理
- 数据库的数据类型
- 【STC8A8K64D4开发板】第2-9讲:比较器