【OCR识别】PaddleHub实现验证码识别
前言
前面有篇文章介绍了 【网站验证码识别】 ,但是其是利用 tesseract 工具的命令行来实现图片内容的识别。
这几天我突然想起,大学时参加百度 AI 比赛用过其 PaddleHub 框架,而且该工具有支持 Python 的第三方库,这不就可以尝试一下。
无脑安装使用
只要基本熟悉 Python,那么按照官网文档基本没有如何问题。
PaddleHub
Paddle Inference 文档地址:https://www.paddlepaddle.org.cn/inference/v2.5/guides/install/python_install.html#pip-tensorrt
PaddleHub 文档地址:https://www.paddlepaddle.org.cn/tutorials/projectdetail/520792#anchor-2
PaddleHub 模型库地址:https://www.paddlepaddle.org.cn/hublist
首先需要先安装 Paddle,然后再安装 PaddleHub:
pip install paddlepaddle paddlehub -i https://mirror.baidu.com/pypi/simple
Paddle 是飞桨的原生推理库,提供服务器端的高性能推理能力,验证是否安装成功:
import paddle as pp
pp.utils.run_check()
# Jupyter 输出信息
Running verify PaddlePaddle program ...
PaddlePaddle works well on 1 CPU.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
PaddleHub 是飞桨预训练模型应用工具,完成模型的管理和一键预测,验证是否安装成功:
import paddlehub as hub
hub.server_check()
# Jupyter 输出信息
[2023-12-22 22:03:51,546] [ INFO] - Request Hub-Server successfully.
True
寻找预训练模型库
PaddleHub 模型库地址:https://www.paddlepaddle.org.cn/hublist
非常实用的预训练模型库,基本上通用的预训练模型都有,其中就包括了 OCR 文本识别库。
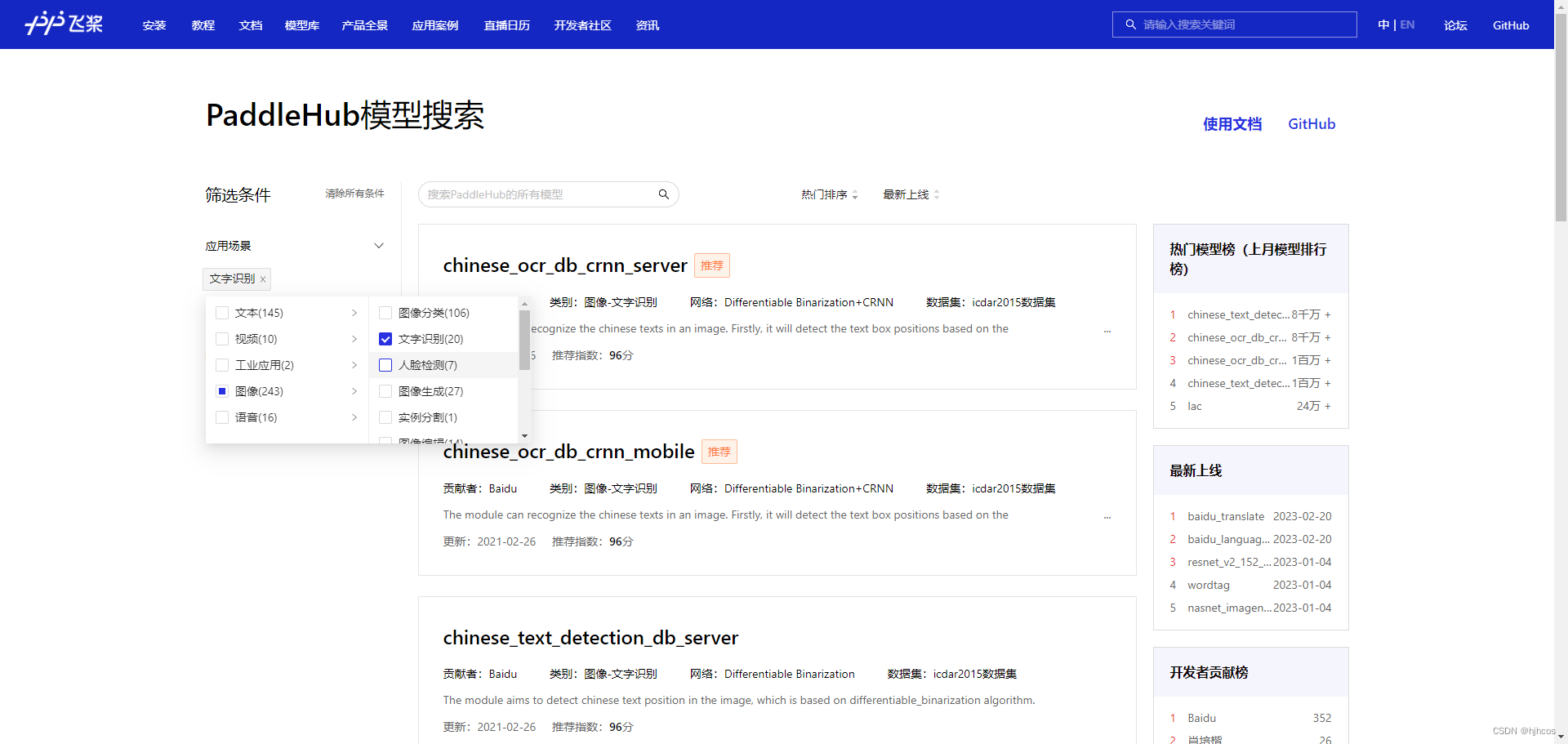
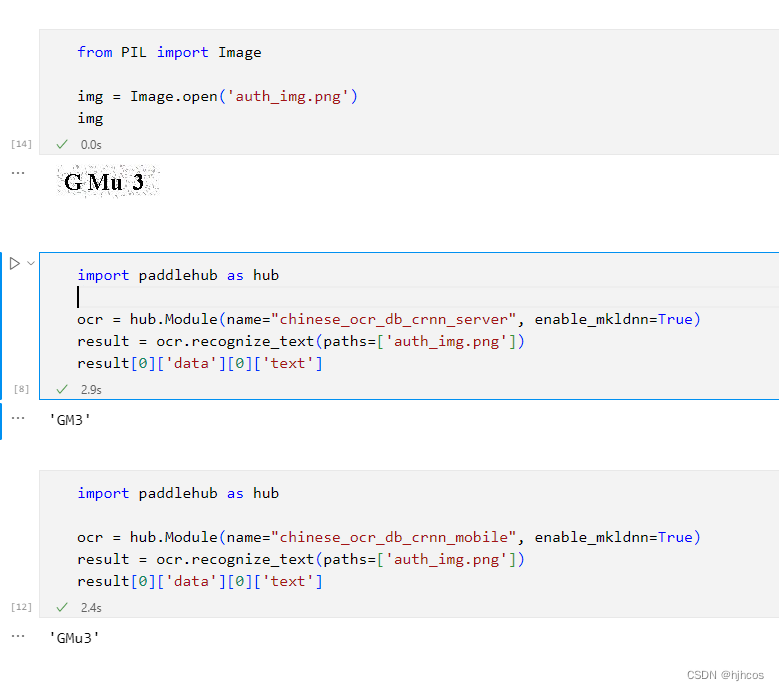
我选择的是最靠前的 chinese_ocr_db_crnn_server 预训练模型,结果我在使用过程中发现,小写字母识别率太低了,个人感觉应该是模型的问题,于是选择了第二个预训练模型 chinese_ocr_db_crnn_mobile,相对来说比第一个的识别率高多了,针对于验证码图片来说。
完整代码
chinese_ocr_db_crnn_mobile 模型地址:https://www.paddlepaddle.org.cn/hubdetail?name=chinese_ocr_db_crnn_mobile
只需要等待模型自动下载安装好,就会自动设别图片:
import paddlehub as hub
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile", enable_mkldnn=True)
result = ocr.recognize_text(paths=['auth_img.png'])
result[0]['data'][0]['text']
# Jupyter 输出信息
'GMu3'
效果图
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Lazada商品评论列表API:电商行业的实时反馈宝库
- 结合ChatGPT和MINDSHOW自动生成PPT
- Unity 编辑器篇|(一)MenuItem菜单栏
- MTK平台 BT从SW 如何分析 Pairing Fail 和 Abnormal Disconnection Issue
- 数组中的内存(java)
- 英语连读技巧3
- 【AI】国内好用的AI工具推荐
- 智能客服系统要素分析:提升客户满意度与工作效率的关键要素
- 分割、合并、转换、重组:强大的自部署 PDF 处理工具 | 开源日报 No.143
- vscode关闭红色波浪线以及代码错误提示