阿里云大模型「让照片跳舞」刷屏朋友圈,有哪些信息值得关注?
介绍
大家好,我分享聊聊阿里通义千问APP中全民舞王功能。
网络热舞结合AI视频,这是以后不用学习跳舞?
可以尝试下效果,一张图片生成视频。
APP快速使用
搜索下载通义千问APP
打开APP,选中一张照片来跳舞。

这里上传照片原则:身体保持全身站立,挺胸抬头,图像中不要有其他人,背景简单些。

AI视频一张图片跳科目三
图解原理
虽然一些技术没有开源,我们可以根据阿里通义实验室自研视频生成模型 Animate Anyone,推演原理。
我们通过图讲解下演化,Animate Anyone用于人物动画的图像到视频合成方法,基于扩散模型重构创新所得。
图解扩散模型生成过程
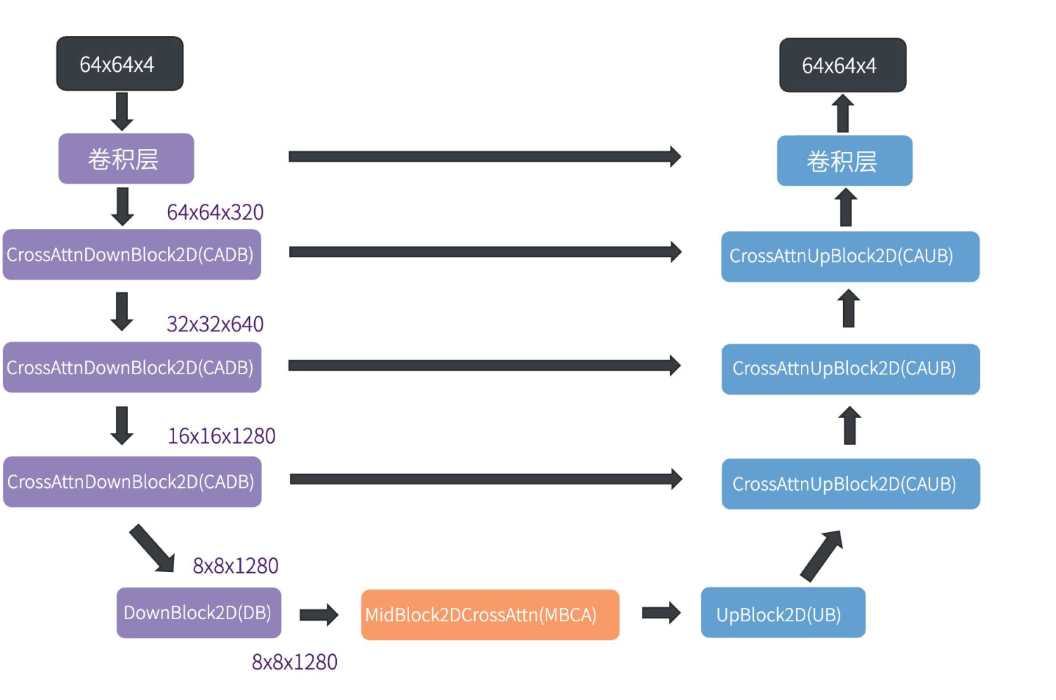
VAE编码器(输出矩阵)-> UNet (完成当前时间步 t 的噪声预测) -> SD1.x 系列(64x64x4 的向量) -> 采样器 (重复 N 次) 去除噪声 -> VAE解码器 -> 生成图像。
具体可以看我原先的讲解扩散模型
图解Animate Anyone生成过程
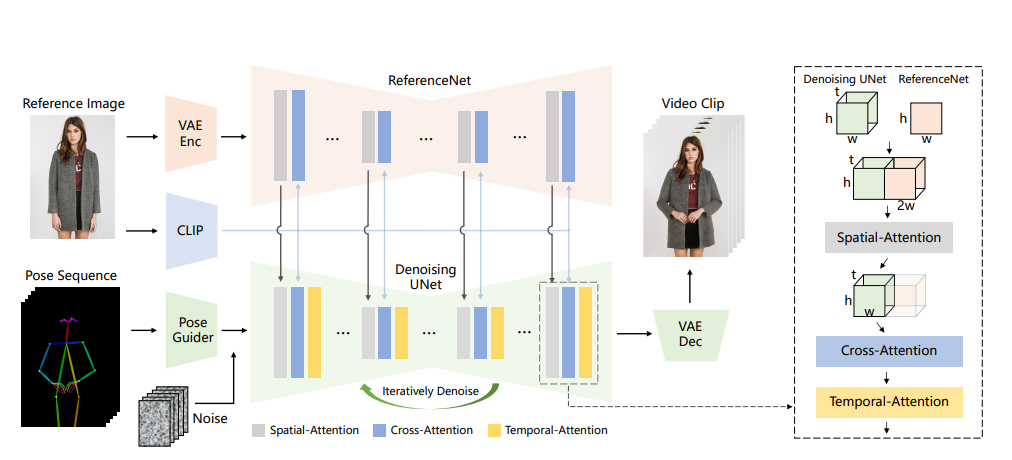
参考图像和姿态序列输入,经过VAE编码器,创建一个矩阵(潜在的表示),用到CLIP (文本-图像映射)引导角色原始外观,姿态引导与U-Net结合,类似上述过程,在空间和时间中去噪,输出一个合成视频。
该架构强调保持角色的详细特征、运动的连续性和对动画的控制。
该模型解决了图像到视频合成的挑战,如保持详细信息和确保生成动画的时间稳定性。
论文在从静态图像生成角色视频方面呈现了最先进的结果。
总结
阿里云大模型 Animate Anyone就像一个超级导演。
与过去那些导演只会让演员在视频里面变来变去、动作不连贯不同,这个模型导演出来的视频,无论演员的样子还是动作都非常逼真流畅,就像真人一样。
朋友们可以一块讨论下还适合在什么领域?
我是李孟,独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 打造高效会员卡营销策划方案,提升门店业绩
- iview Table实现跨页勾选记忆功能以及利用ES6的Map数据结构实现根据id进行对象数组的去重
- 强化学习第1天:马尔可夫过程
- 基于Flume+Kafka+Hbase+Flink+FineBI的实时综合案例(一)案例需求
- 软件设计模式
- [AIGC] Apache Spark 简介
- Visual Studio2022安装assimp库教程
- 【CVPR2023】可持续检测的Transformer用于增量对象检测
- 医院信息系统集成平台—Ensemble集成平台中间件
- 是时候将javax替换为Jakarta了