redis-cluster集群
redis-cluster集群:
redis3.0引入的分布式存储方案
集群由多个node节点组成,redis数据分布在这些节点之中
在集群之中分为主节点和从节点
集群模式当中,主从一一对应,数据写入和读取与主从模式一样,主负责写,从只能读
集群模式自带哨兵模式,可以自动实现故障切换,但是在故障切换完成之前,整个集群都将不可用,切换完毕之后,集群会立即恢复
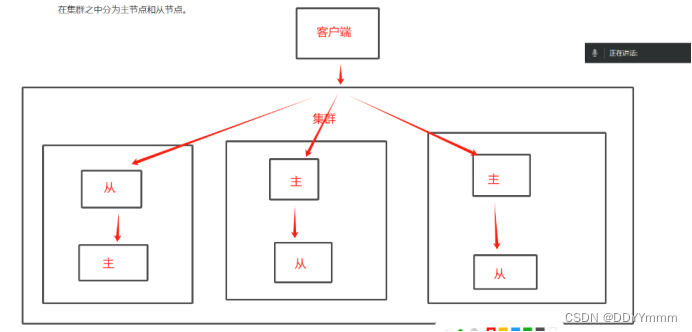
集群模式按照数据分片:
- 数据分区 是集群的核心功能,每个主都可以对外提供读、写功能,但是数据是一一对应写入主的对应从节点,在集群模式中可以容忍的数据的不完整
- 高可用:集群的主要目的。
数据分片的实现:
redis的集群引入了哈希槽的概念
redis集群当中16384个哈希槽位。(0-16383)
根据集群当中主从节点数,分配给哈希槽位,每个主从节点只负责一部分的哈希槽位
每次读写都涉及到哈希槽为,key通过CRC16校验之后,对16384取余数,余数值决定数据放入哪个哈希槽位。通过这个值去找到对应槽位所在的节点,然后直接跳转到这个节点进行存取操作。
哈希槽位的值是连续的,如果出现不连续的哈希槽位,或者有哈希槽位没有被分配,集群会即将报错

主从复制:主宕机之后,主节点原来负责的哈希槽位将会不可用,需要从节点代替主节点继续负责原有的哈希操作,保证集群正常工作,故障切换的过程中,会提示集群不可用。切换完成,集群恢复继续工作。
实验
所有redis服务器
修改配置文件
vim /etc/redis/6379.conf
70行默认监听所有网卡
bind 0.0.0.0
89行修改,关闭保护模式
protected-mode no
137行,开启守护进程,以独立进程启动
daemonize yes
700行,开启AOF持久化
appendonly yes
833行,取消注释,开启群集功能
cluster-enabled yes
841行,取消注释,群集名称文件设置
cluster-config-file nodes-6003.conf
847行,取消注释群集超时时间设置
cluster-node-timeout 15000
重启
/etc/init.d/redis_6379 restart

replicas 1:规定一个主只有一个从
主从的配合是随机分配的
在集群模式当中,只能选择0库,集群不能切换库
Adding replica 192.168.120.110:6379 to 192.168.120.11:6379
Adding replica 192.168.120.10:6379 to 192.168.120.12:6379
Adding replica 192.168.120.70:6379 to 192.168.120.13:6379
127.0.0.1:6379> set test2 1
(error) MOVED 8899 192.168.233.14:6379
表名客户端尝试读取键值对test1,但是实际槽位在4768,集群要求客户端移动到4768槽位所在的主机节点,获取数据
集群流程:
- 集群自带主从和哨兵
- 每个主从节点之间互相隔离的,可以容忍数据的不完整。目的:高可用
- 哈希槽位决定每个节点的读写操作,在创建key时,系统已经分配好了指定槽位
- MOVED不是报错,只是提醒客户端去分配的槽位节点,获取数据
在nginx节点配置,实现负载均衡!
stream {
????upstream redis_cluster {
????????server 192.168.233.7:6379;
????????server 192.168.233.8:6379;
????????server 192.168.233.9:6379;?????
????}
????server {
????????listen 6379;
????????proxy_pass redis_cluster;
????????proxy_connect_timeout 1s;
????????proxy_timeout 1s;
????????proxy_responses 1;
????}
}
proxy_responses 1;在集群之中只要有一个节点响应,然后代理服务器就会把响应传递给客户端,可以增加整个系统的稳定性。
只要有一个节点返回了正确的响应,就可以继续服务请求,而不至于因为某个节点无响应而导致整个请求失败
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java常见面试题:请解释一下Java中的常用分布式框架,如Spring Boot、Dubbo等。
- mysql主从同步简单理解
- 爬虫快速入门
- 数据结构期末复习笔记
- vue+element项目中页面多个接口异常,只提示一次异常信息
- (vue)键值对结构数据展示
- 嵌入式-Stm32-江科大基于标准库通过GPIO点LED灯
- 解决Chrome浏览器安装Proxy-SwitchyOmega插件时“清单文件缺失或不可读取”错误
- 加速Spring Boot单元测试的执行速度
- Spring MVC的原理