机器学习---adaboost二分类、回归
1. adaboost二分类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
# 几个关键参数有n_samples(生成样本数), n_features(正态分布的维数),mean(特征均值),
# cov(样本协方差的系数), n_classes(数据在正态分布中按分位数分配的组数)
X1, y1 = make_gaussian_quantiles(cov=2.,
n_samples=200, n_features=2,
n_classes=2, random_state=1)
# plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=y1)
# print(X1)
# print("----------------------------------------------------")
# print(y1)
X2, y2 = make_gaussian_quantiles(mean=(3, 3), cov=1.5,
n_samples=300, n_features=2,
n_classes=2, random_state=1)
# 数组拼接
X = np.concatenate((X1, X2)) # 500*2
# print(np.shape(X1), np.shape(X2), np.shape(X))
y = np.concatenate((y1, - y2 + 1))
# Create and fit an AdaBoosted decision tree
# SAMME和SAMME.R。两者的主要区别是弱学习器权重的度量,SAMME使用二元分类Adaboost算法的扩展,
# 即用对样本集分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。
# 由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此AdaBoostClassifier的默认算法algorithm的值也是SAMME.R。
# 我们一般使用默认的SAMME.R就够了,但是要注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器。
# SAMME算法则没有这个限制。
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1),
algorithm="SAMME",
n_estimators=200)
bdt.fit(X, y)
plot_colors = "br"
plot_step = 0.02
class_names = "AB"
plt.figure(figsize=(10, 5))
# Plot the decision boundaries
plt.subplot(121)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 # X shape 500 * 2
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
# # ravel() 和 flatten()函数,将多维数组降为一维,ravel返回视图,flatten返回拷贝
# np.r_是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等,类似于pandas中的concat()。
# np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等,类似于pandas中的merge()。
Z = bdt.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.axis("tight")
# Plot the training points
for i, n, c in zip(range(2), class_names, plot_colors):
idx = np.where(y == i)
plt.scatter(X[idx, 0], X[idx, 1],
c=c, cmap=plt.cm.Paired,
s=20, edgecolor='k',
label="Class %s" % n) # s size of point
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.legend(loc='upper right')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Decision Boundary')
# Plot the two-class decision scores
twoclass_output = bdt.decision_function(X)
plot_range = (twoclass_output.min(), twoclass_output.max())
plt.subplot(122)
for i, n, c in zip(range(2), class_names, plot_colors):
plt.hist(twoclass_output[y == i],
bins=10,
range=plot_range,
facecolor=c,
label='Class %s' % n,
alpha=.5,
edgecolor='k')
x1, x2, y1, y2 = plt.axis()
plt.axis((x1, x2, y1, y2 * 1.2))
plt.legend(loc='upper right')
plt.ylabel('Samples')
plt.xlabel('Score')
plt.title('Decision Scores')
plt.tight_layout()
plt.subplots_adjust(wspace=0.35) # 调整图像边框,使得各个图之间的间距为0.35
plt.show()使用 make_gaussian_quantiles 生成了两组高斯分位数数据。X1、y1 是其中一组数据,X2、y2
是另一组数据。通过合并这两组数据得到 X 和 y,创建了一个用于二分类的合成数据集。
AdaBoost 分类器初始化:用 AdaBoostClassifier 实例化了一个 AdaBoost 分类器 (bdt)。
它以 DecisionTreeClassifier 作为基本估计器,最大深度为 1。选择的算法是 "SAMME"(多类别指
数损失函数的逐步增强建模)。使用生成的合成数据 (X 和 y) 对分类器 (bdt) 进行训练。
通过对整个数据范围进行网格预测,绘制了决策边界。使用 contourf 绘制了网格预测结果。
基于其类别,用不同颜色('b' 表示一类,'r' 表示另一类)绘制了训练数据点。
绘制了两个类别的决策分数(decision_function 的输出),呈现为直方图。每个直方图代表每个类
别的决策分数分布情况。使用 Matplotlib 显示了绘制的图形(决策边界和直方图)。
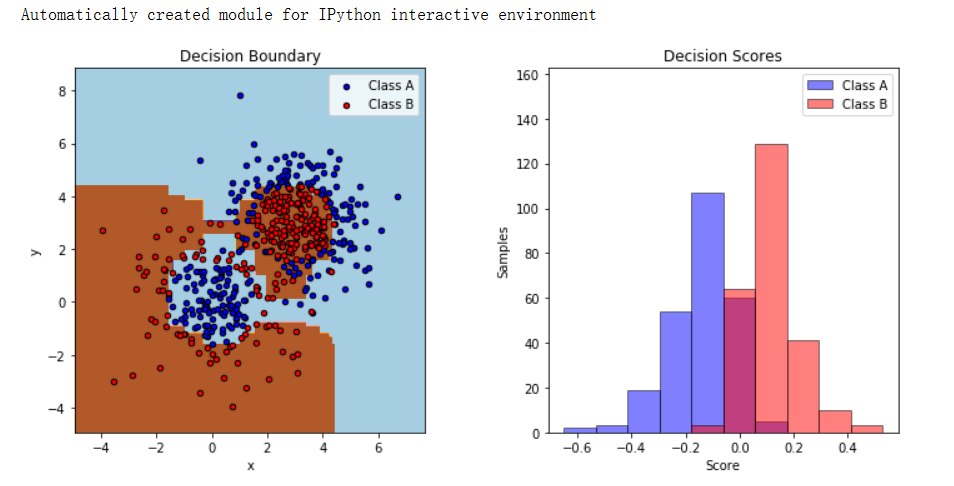
这段代码通过可视化的方式展示了 AdaBoost 如何为合成数据创建决策边界,并为数据赋予决策分
数。这是一个很好的方法,可以理解 AdaBoost 的工作原理,以及它如何基于多个弱学习器(在这
里是决策树)做出决策。?
2. adaboost回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
# Create the dataset
# 这里看以看到,1这个数字是伪随机数产生器的种子,也就是“the starting point for a sequence of pseudorandom number”
rng = np.random.RandomState(1)
X = np.linspace(0, 6, 100)[:, np.newaxis] # array, (500,) (500,1)
#
y = np.sin(X).ravel() + np.sin(6 * X).ravel() + rng.normal(0, 0.1, X.shape[0])
# 该段代码的目的是产生一个X.shape[0]的assarray,其中的每个元素都是均值为0,方差为0.1的高斯分布
# Fit regression model
regr_1 = DecisionTreeRegressor(max_depth=4)
regr_2 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4),
n_estimators=300, random_state=rng)
regr_1.fit(X, y)
regr_2.fit(X, y)
# Predict
y_1 = regr_1.predict(X)
y_2 = regr_2.predict(X)
# Plot the results
plt.figure()
plt.scatter(X, y, c="k", label="training samples")
plt.plot(X, y_1, c="g", label="n_estimators=1", linewidth=2)
plt.plot(X, y_2, c="r", label="n_estimators=300", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Boosted Decision Tree Regression")
plt.legend()
plt.show()生成一个长度为 100 的等间距数列 X,并将其转换成一列。y 由 sin(X) 和 sin(6*X) 的和构成,加
上服从均值为 0、方差为 0.1 的高斯噪声。regr_1 是一个深度为 4 的单独决策树回归模型。
regr_2 是一个基于 AdaBoost 的回归模型,它使用了深度为 4 的决策树作为基础估计器,设定了
300 个弱分类器,并使用了指定的随机状态 random_state=rng。
分别使用 X 和 y 对 regr_1 和 regr_2 进行训练。使用训练好的模型 regr_1 和 regr_2 对 X 进行预
测,得到预测结果 y_1 和 y_2。绘制了原始数据点的散点图。
绘制了 regr_1(使用单一决策树)和 regr_2(使用 AdaBoost 回归器)的预测结果曲线。
添加了图例、横纵坐标标签以及标题,最后展示了回归结果的图像。
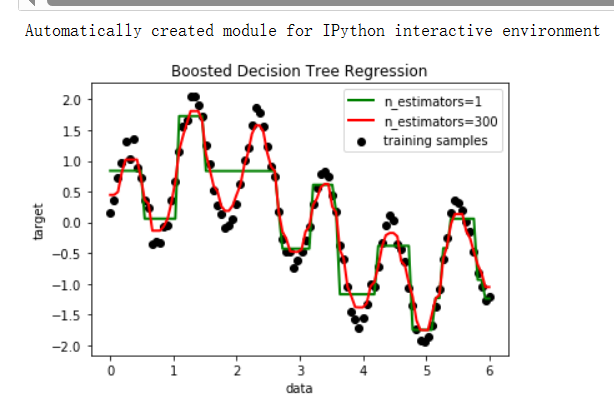
这段代码展示了如何使用单一决策树和基于 AdaBoost 的回归模型对具有噪声的正弦波数据进行拟
合,并对比了两种模型的表现。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!