爬虫之牛刀小试(一):爬取电影天堂最新的电影数据
发布时间:2024年01月11日
考完放假之后,感觉闲来无事,忽然想起以前的学的爬虫已经忘得有些差不多了,又觉得有些数据难以寻找,于是准备复习几个案例来给大家分享一下,顺便提升一下自己。
本次爬取的网页是电影天堂,网址为
http://www.dytt8.net/html/gndy/dyzz/list_23_1.html
import requests
from lxml import etree
import time
from bs4 import BeautifulSoup
BASE_DOMAIN = 'http://www.dytt8.net'
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
def get_detail_urls(url):
response = requests.get(url, headers=HEADERS)
text=response.content.decode('gbk')
html_element = etree.HTML(text)
detail_urls = html_element.xpath('//table[@class="tbspan"]//a/@href')
detail_urls_new = detail_urls
for index, detail_url in enumerate(detail_urls_new):
if detail_url == '/html/gndy/jddy/index.html':
detail_urls.remove(detail_url)
print(detail_urls)
print(BASE_DOMAIN + detail_url)
detail_urls = map(lambda x: BASE_DOMAIN + x, detail_urls)
return detail_urls
def parse_detail_urls(detail_url):
response = requests.get(detail_url, headers=HEADERS)
text = response.content.decode('gbk')
if not text:
print(f'No content returned from {detail_url}')
return
html_element = etree.HTML(text)
if html_element is None:
print(f'Failed to parse HTML from {detail_url}')
return
title=html_element.xpath('//div[@class="title_all"]//font[@color="#07519a"]/text()')[0]
print(title)
zoom_element = html_element.xpath('//div[@id="Zoom"]')[0]
imgs = zoom_element.xpath('.//img/@src')
print(imgs)
cover = imgs[0]
print(cover)
movie = {
'title': title,
'cover': cover,
}
year, country, type, rating, duration, director, actors, cover, screen_shot = '', '', '', '', '', '', '', '', ''
def parse_info(info, rule):
return info.replace(rule, '').strip()
infos = zoom_element.xpath('.//text()')
for index, info in enumerate(infos):
if info.startswith('◎年 代'):
info = parse_info(info, '◎年 代')
movie['year'] = info
elif info.startswith('◎产 地'):
info = parse_info(info, '◎产 地')
movie['country'] = info
elif info.startswith('◎类 别'):
info = parse_info(info, '◎类 别')
movie['category'] = info
elif info.startswith('◎豆瓣评分'):
info = parse_info(info, '◎豆瓣评分')
movie['douban_rating'] = info
elif info.startswith('◎片 长'):
info = parse_info(info, '◎片 长')
movie['duration'] = info
elif info.startswith('◎导 演'):
info = parse_info(info, '◎导 演')
movie['director'] = info
elif info.startswith('◎主 演'):
info = parse_info(info, '◎主 演')
actors = [info]
for x in range(index + 1, len(infos)):
actor = infos[x].strip()
if actor.startswith('◎'):
break
actors.append(actor)
movie['actors'] = actors
elif info.startswith('◎简 介'):
info = parse_info(info, '◎简 介')
for x in range(index + 1, len(infos)):
profile = infos[x].strip()
if profile.startswith('【下载地址】'):
break
movie['profile'] = profile
if len(imgs) > 1:
screen_shot = imgs[1]
movie['screen_shot'] = screen_shot
zoom_str = etree.tostring(zoom_element, encoding='utf-8').decode('utf-8')
soup = BeautifulSoup(zoom_str, 'html.parser')
magnet_link = soup.find('a', href=True)['href']
movie['download_link'] = magnet_link
return movie
def spider():
base_url = 'http://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'
movies = []
for x in range(1, 2):
url = base_url.format(x)
detail_urls = get_detail_urls(url)
for detail_url in detail_urls:
movie = parse_detail_urls(detail_url)
movies.append(movie)
time.sleep(1)
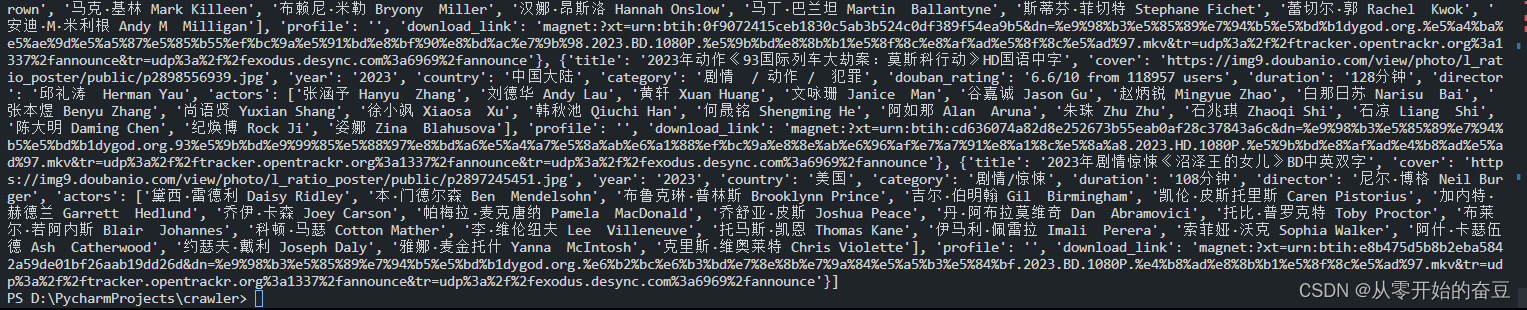
print(movies)
if __name__ == '__main__':
spider()
get_detail_urls(url): 这个函数从给定的 URL 获取电影详情页的 URL。它首先发送一个 GET 请求到 URL,然后解析返回的 HTML 文档,提取出电影详情页的 URL。
parse_detail_urls(detail_url): 这个函数从给定的电影详情页 URL 解析电影信息。它首先发送一个 GET 请求到电影详情页 URL,然后解析返回的 HTML 文档,提取出电影的标题、封面图片 URL、年份、国家、类别、豆瓣评分、片长、导演、主演、简介、截图和下载链接。
spider(): 这是主函数,它遍历电影列表页的 URL,对每个电影列表页调用 get_detail_urls(url) 函数获取电影详情页的 URL,然后对每个电影详情页的 URL 调用 parse_detail_urls(detail_url) 函数解析电影信息,最后将所有电影的信息打印出来。
结果:
注意不要爬太多了,容易被封号。
最近新开了公众号,请大家关注一下。

文章来源:https://blog.csdn.net/m0_68926749/article/details/135528895
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 动态规划python简单例子-斐波那契数列
- Logstash应用-同步ES(elasticsearch)到HDFS
- K8S学习指南(62)-K8S源代码走读之Kube-Scheduler
- IPC之九:使用UNIX Domain Socket进行进程间通信的实例
- 十大VSCODE 插件推荐2023
- React-Native基础语法记录
- 基于java的宠物领养系统设计与实现
- 【漏洞复现】Dedecms信息泄露漏洞(CVE-2018-6910)
- C语言中的指针变量p,特殊表达式p[0] ,(*p)[0],(px+3)[2] ,(*px)[3]化简方法
- 【NVIDIA】Jetson Orin Nano系列:安装 Qt6、firefox、jtop、flameshot