【论文+视频控制】23.08DragNUWA1.5:通过集成文本、图像和轨迹来进行视频生成中的细粒度控制 (24.01.08开源最新模型)
论文链接:DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
代码:https://github.com/ProjectNUWA/DragNUWA

一、简介
中国科学技术大学+微软亚洲研究院 在 NUWA多模态模型、 Stable Video Diffusion 、UniMatch基础上提出的可控视频合成方法

提出了同时(simultaneously )引入文本、图像和轨迹信息,从语义(semantic)、空间(spatial)和时间角度(temporal perspectives) 对视频内容进行·细粒度控制(fine-grained control)。。
为了解决当前研究中开放域轨迹控制(open-domain trajectory control )限制的问题,我们提出了三个方面的轨迹建模
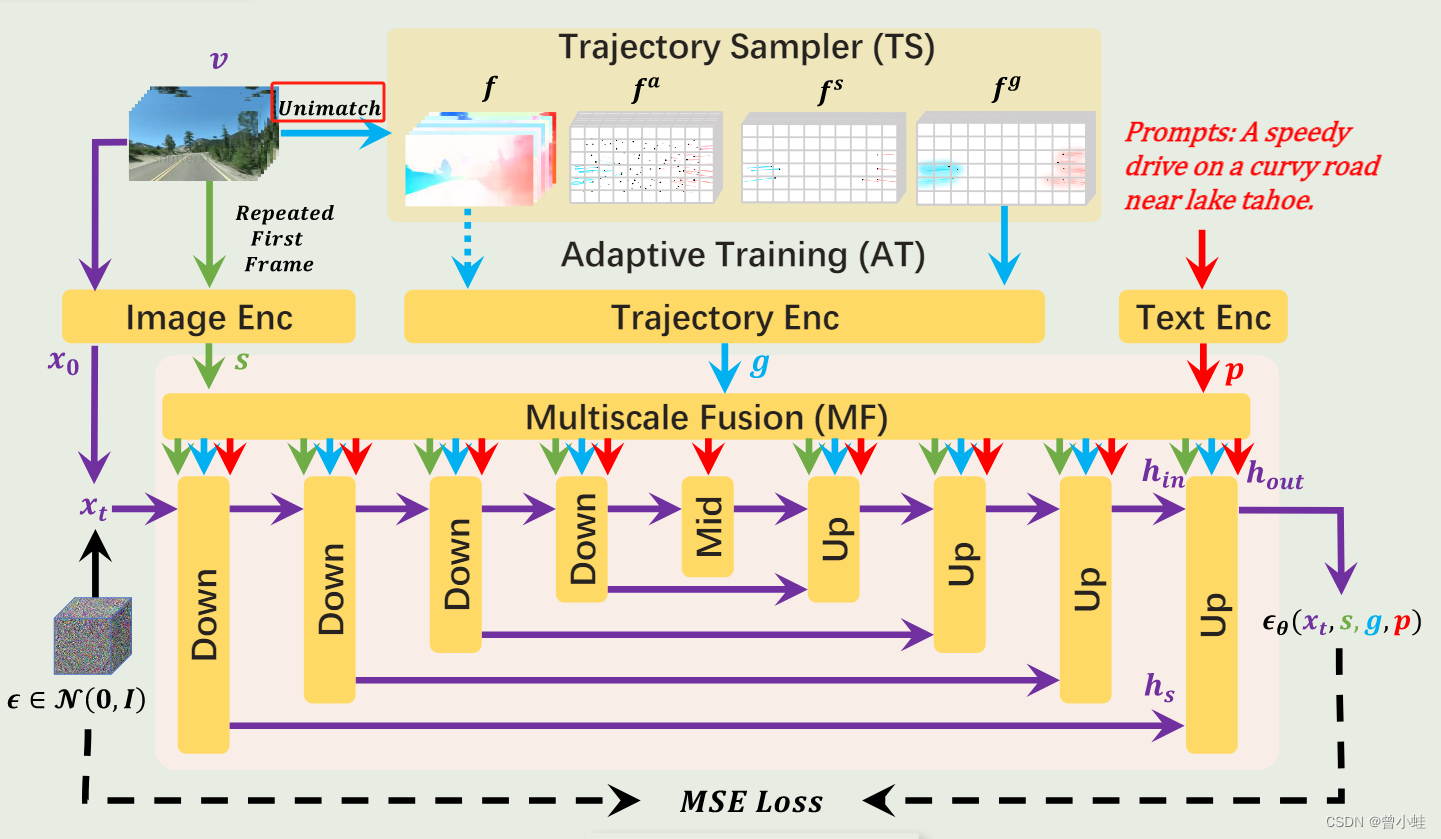
一个轨迹采样器(TS,a Trajectory Sampler):保证任意轨迹(arbitrary trajectories,)的开放域控制
一个多尺度融合(MF,a Multiscale Fusion):不同细粒度(granularities)的控制轨迹
自适应训练策略(AT, Adaptive Training): 生成一致的(consistent)的视频。

二、主要方法
DragNUWA训练流程概述。DragNUWA支持三种可选输入:文本p、图像s和轨迹g,并专注于从三个方面设计轨迹。首先,轨迹采样器(TS)从开放域视频流中动态采样轨迹。其次,多尺度融合(MF)将轨迹与UNet架构的每个块中的文本和图像深度集成。最后,自适应训练(AT)将模型从光流条件调整为用户友好的轨迹。最终,DragNUWA能够处理具有多个对象及其复杂轨迹的开放域视频。
三、相关工作(需要的知识储备)
- 21.11.
NUWA: 神经视觉世界创造的视觉合成预训练模型 Visual Synthesis Pre-training for Neural visUal World
creAtion - 22.09
Make-A-Video:Meta AI 提出一种直接将文本到图像 (T2I) 生成的巨大最新进展转换为文本到视频 (T2V) 的方法 :Text-to-Video Generation without Text-Video Data - 22.10
Imagen Video: Imagen video: High ?video generation with diffusion models - 23.02
GEN1: Runway : 基于扩散模型的结构和内容引导视频合成 Structure and Content-Guided Video Synthesis with Diffusion Models
3.1 NUWA的由来 (Neural visUal World creAtion)
Neural visual World creation (神经视觉世界创造)

视觉多模态预训练框架
一种统一的多模态预训练模型N?UWA,该模型可以为各种视觉合成任务生成新的或操作现有的视觉数据(即图像和视频)。为了同时覆盖不同场景的语言、图像和视频,设计了一个 3D 变压器编码器-解码器框架,该框架不仅可以将视频作为 3D 数据处理,还可以将文本和图像分别调整为 1D 和 2D 数据。还提出了一种 3D 近邻注意 (3DNA) 机制来考虑视觉数据的性质并降低计算复杂度。
3.3 Imagen Video
本文提出了一种基于视频扩散模型级联的以文本情境来生成视频的系统,即用图像增强技术来生成视频——Imagen Video。 给定一个文本提示符(a text prompt),Imagen Video 使用基本视频生成模型和一系列时空交织的视频超分模型,来生成高清视频。我们描述了如何将该系统扩展为一个高清晰度的 text2video模型,包括设计决策,如在一定的分辨率下,时空超分模型的全卷积层的选择,和扩散模型(Diffusion Model)的v-parameterization的选择。此外,我们确认并迁移了一些研究成果,从以前基于diffusion的图像生成工作,到我们视频生成设置。 最终,我们将渐进式蒸馏(progressive distillation)运用至我们的视频生成模型中,用免分类(classier-free) 的引导函数来引导生成快速、高品质的样本。我们发现 Imagen Video 不仅能够生成高保真度的视频,并且具有高度的可控性,了解世界常识(world knowledge)。它能够生成不同艺术风格、能够理解3D对象的视频和文本动画。

附录:代码主要借鉴
主要借鉴于 Stable Video Diffusion ?、 Hugging Face、 ? UniMatch
Stable Video Diffusion
Hugging Face
UniMatch:流量、立体和深度估计
一个统一的模型对三种运动和3D感知的任务:(流量、立体和深度估计获得):
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 偷偷称为一名炼丹师、掌握核心参数然后惊艳所有人!
- JAVA商城源码_多用户商城系统源码_B2B2C商基于微服务架构的企业级商城系统、满足高并发、高安全的企业级要求
- 玩转大数据20:大数据应用容器化与部署实践
- 媒体捕捉-拍照
- vue项目中实现预览pdf
- React16源码: React中的renderRoot的源码实现
- 机器学习---决策树和随机森林代码
- 【前端设计模式】之命令模式
- 开关电源如何覆铜
- 英国计划为数据中心制定严格的新安全规则