多模态大模型Clip
发布时间:2024年01月11日
一、经典分类模型的问题:
- 类别固定
- 当前的模型只能胜任一个任务,迁移到新任务上非常困难
- 类别互斥
- 当前的CV数据集标注劳动密集,成本较高,
- 当前模型泛化能力较差
负样本的组成(Batchsize有N个文本-图像对)
Batchsize太小,负样本太少,训练效果不佳
Batchsize太大,负样本不准
正负样本是在Batchsize内部构造出来
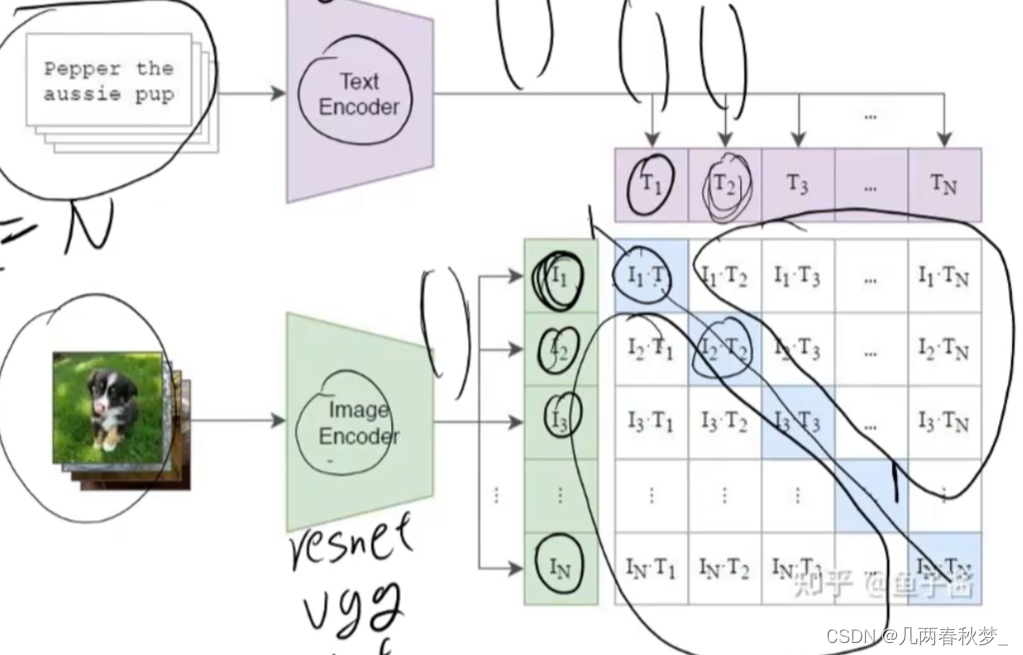
只有对角线为1,其余为0
二、Clip模型的缺点
- ·CLIP的zero-shot性能虽然总体上比supervised baseline ResNet-50要好但其实在很多任务上比不过SOTA methods,因此CLIP的transfer learning有待挖掘
- ·CLIP在这几种task上zero-shot性能不好: fine-grained分类 (花的分类、车的分类之类的)、抽象的任务 (如计算图中object的个数) 以及预训练时没见过的task (如分出相邻车辆的距离)。Zero-shot CLIP在真正意义上的out-of-distribution data上性能不好,比如在OCR中
- 生成新的概念(如:词),这是CLIP功能上的缺陷,CLIP终究不是生成模型
- ·CLIP的训练数据是从网上采集的,这些image-text pairs没有做data clear和de-bias这可能会使模型有一些social biases;
- ·很多视觉任务很难用text来表达,如何用更高效的few-shot learning方法优化CLIP也很重要。
文章来源:https://blog.csdn.net/weixin_64443786/article/details/135536443
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Javascript中数组的使用方式、Array的属性和方法的使用以及解释理解
- GaussDB SQL基础语法示例-数组表达式
- 念念不忘智能编程,必有回响CodeArts Snap
- C语言实现队列
- C++随机数生成:std标准库和Qt自带方法(未完待续)
- 堆的简单实现,堆排序,TopK问题
- 正则表达式IP地址
- 找不到满意的机器视觉工程师工作,想找到满意的工作很难,人太多了,只能先就业后择业
- Android/iOS APP备案流程指南
- ETSformer: Exponential Smoothing Transformers for Time-series Forecasting