【MySQL性能优化】- 存储引擎及索引与优化
索引与优化
😄生命不息,写作不止
🔥 继续踏上学习之路,学之分享笔记
👊 总有一天我也能像各位大佬一样
🏆 博客首页 ??@怒放吧德德??To记录领地
🌝分享学习心得,欢迎指正,大家一起学习成长!

文章目录
前言
工作一段时间后,相信每个开发者也大多都是接触MySQL数据,然而也应该都遇到过查询慢等的问题而烦恼,如何对MySQL进行优化,那这就源于我们对MySQL的底层原理了解了多少,因此还是需要不断地学习来提升自己。
存储引擎
MySQL支持多种存储引擎(Storage Engine),每种引擎有不同的特性、优势和用途。存储引擎是MySQL用于处理数据的底层引擎,它负责数据的存储、检索和处理。也就是存储数据、建立索引、更新查询的实现方式。存储引擎是表的类型,之前也叫表的处理器,接受上层传来的指令,对数据进行操作。
我们可以通过
SHOW ENGINES来显示当前 MySQL 实例支持的存储引擎及其状态。
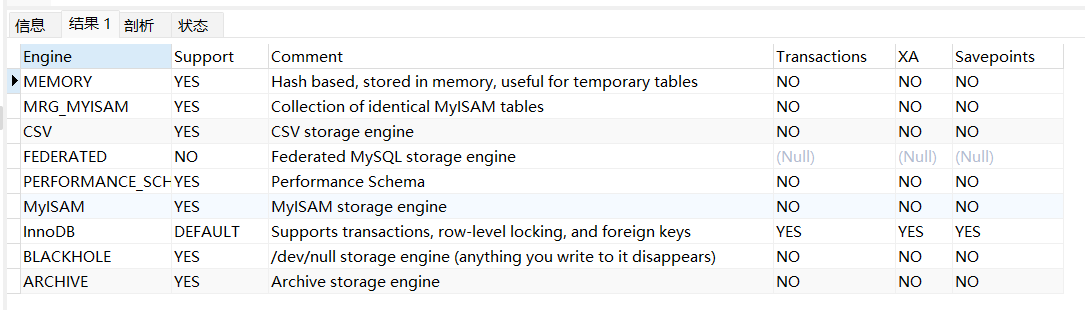
可看到上图所支持的存储引擎类型,在 MySQL 5.5 之后(笔者的MySQL是8.0版本),InnoDB是默认的MySQL 存储引擎。
- Engine: 存储引擎的名称。
- Support: 表示该存储引擎是否被 MySQL 支持。值为 “YES” 表示支持,“NO” 表示不支持。
- Comment: 提供了关于存储引擎的一些额外信息或注释。
- Transactions: 表示存储引擎是否支持事务。如果支持,值为 “YES”,否则为 “NO”。
- XA: 表示存储引擎是否支持分布式事务。如果支持,值为 “YES”,否则为 “NO”。
- Savepoints: 表示存储引擎是否支持保存点(Savepoints)。如果支持,值为 “YES”,否则为 “NO”。
*这里主要介绍的是MyISAM存储引擎与InnoDB存储引擎,这里做简单的描述,后文会在索引的底层实现进行阐述。
MyISAM存储引擎
MyISAM是另一种常见的存储引擎,它不支持事务,但对于读密集型操作有很好的性能,也不支持行级锁与外键。MyISAM适用于一些只读或很少更新的应用,例如数据仓库和报表生成。MyISAM支持全文索引和压缩表格,但不支持事务和外键。
在MySQL5.5之前,MyISAM是MySQL默认的引擎,因为不支持行级锁和外键,故在增加/更新的操作会锁定全表,对新增/更新的效率比较差,但是对查询的效率会高点。
InnoDB存储引擎
在MySQL5.5之后,InnoDB是MySQL的默认存储引擎,它支持ACID事务和行级锁定。InnoDB还提供了外键约束、回滚日志和崩溃恢复等高级特性,使其适用于大多数应用场景。对于需要事务支持和高并发读写操作的应用,InnoDB通常是首选的存储引擎。
以上存储引擎是我们最长见的存储引擎,其结构在后文将会继续介绍,这里就只是简单阐述。
其他存储引擎
除了以上存储引擎,还有其他的一些存储引擎,这里简单的描述。
- MEMORY: MEMORY存储引擎将表格存储在内存中,适用于需要快速访问的临时表格或缓存表格。由于数据存储在内存中,MEMORY存储引擎在某些情况下可以提供很高的性能,但注意数据在服务器重启时会丢失。
- Archive: Archive存储引擎用于存储大量归档数据,通常在只读环境中使用,不支持索引。它具有高度的压缩特性,适合于大量历史数据的存储。
- CSV: CSV存储引擎将数据存储为逗号分隔值文件,适用于导入和导出数据。
- Blackhole: Blackhole存储引擎是一个“无操作”引擎,它接受写操作但不保存数据,对于数据复制和日志记录很有用。
- TokuDB: TokuDB是一个专注于性能和压缩的存储引擎,适用于需要处理大量数据并具有高写入速度的场景。
InnoDB与MyISAM的区别
用以下表格简单明了查看两种存储引擎的区别:
| InnoDB | MyISAM | |
|---|---|---|
| 支持事务 | 支持 | 不支持 |
| 锁定机制 | 行级/表级锁定 | 表级锁定 |
| 索引类型 | 聚簇 | 非聚簇 |
| 支持外键 | 支持 | 不支持 |
| 支持全文索引 | 支持(5.6以后) | 支持 |
| 崩溃恢复 | 数据库重新启动后自动恢复到崩溃前的状态 | 不具备崩溃恢复的能力 |
| Auto Increment | 事务提交时分配 | 语句执行时分配 |
| 适用场景 | 大量insert、delete和update下使用 | 大量select下使用 |
索引底层原理
什么是索引?
在MySQL中,索引是一种用于提高数据库查询效率的数据结构。就好比如是书上的目录,方便我们快速的定位到哪一页面,即让MySQL快速的找到数据的所在位置,而不必扫描整个表。
合理使用索引是能够帮助我们快速定位到查询的数据。先用一个简单的例子来认识一下索引。
首先创建了一张表,表中有字段id、name、age,三个字段。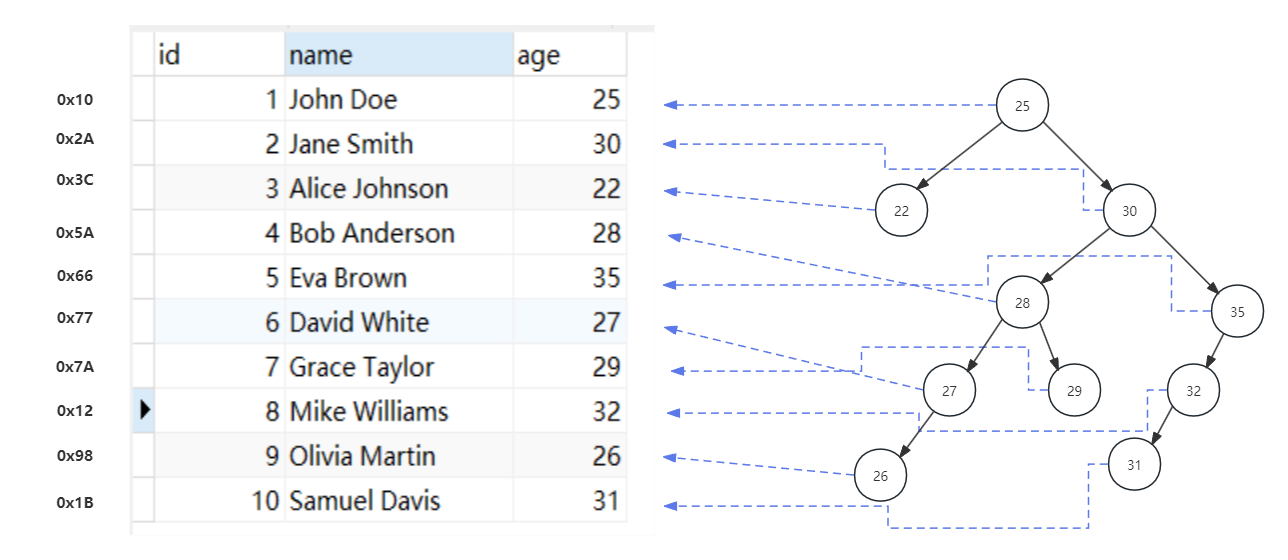
如图,我们假设以age建立索引,假设索引的底层结构是二叉搜索树,mysql就会将age的值构建成一颗如图右边的二叉树。当我们有一条根据age查询的语句,当不加索引的时候,将会再磁盘中按顺序一条条查询比对,而每次的查询都会伴随着一次的IO交互。当我们查找age=25的数据时候,不使用索引,就会进行全表扫描,好在这条在第一条数据,再加上索引后,也是第一条,这样的效果就不是很明显。当我们要查询age=22的数据,不加索引需要查询3次,而加了索引就只需要查询2次,在一定程度是提高了速率。当然,mysql的底层并不是二叉树,而是使用B+树,这里只是简单模拟索引的作用。
索引的数据结构
要了解索引的数据结构,我们先要了解以下几种数据结构。
- 二叉树
- 红黑树
- Hash表
- B-Tree
我们知道,mysql是使用B+树(B-树的一种变形),为什么mysql不考虑使用二叉树呢?这肯定是二叉树在某种程度上效率不高,要理解这些,我们就需要渐进学习。学习数据结构,我们可以通过一个可视化的数据结构网站配合学习。
Data Structure Visualization
二叉树
首先我们先来介绍二叉树,二叉树是其中每个节点最多有两个子节点,分别称为左子节点和右子节点。我们主要来讨论二叉搜索树。
二叉搜索树
二叉搜索树(二叉查找树),这种二叉树的特点就是会根据加进来节点的大小进行排序(默认是左小右大)。如以上的例子,通过id来建立索引,如果使用的是二叉查找树作为数据结构建立的索引。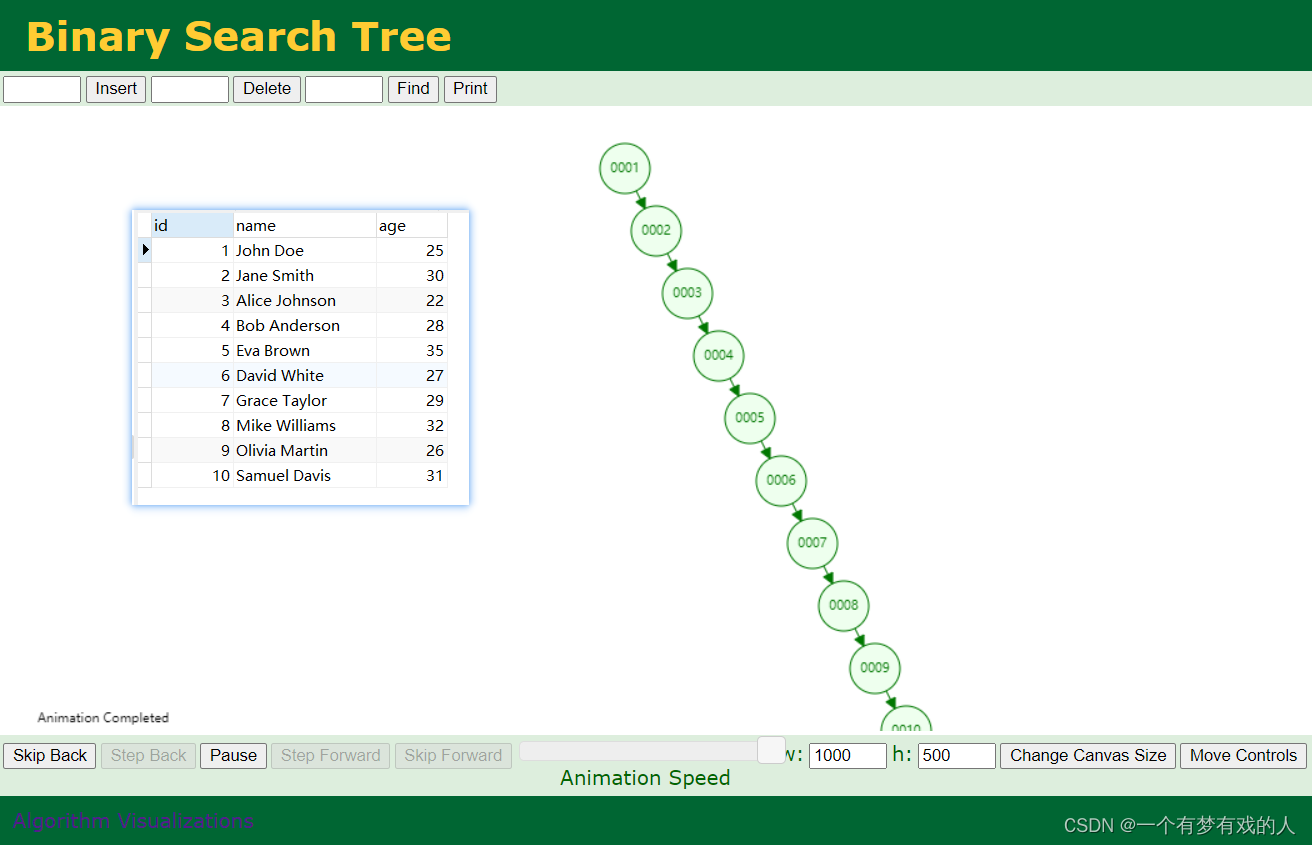
如图,我们可以清晰看到,因为id是有序的,如果使用二叉搜索树就会使得树的度非常高,这样的结构也就变成了链表了,假如需要查询id=5的数据,查询全表也是5次,查询二叉树也是5次,显然这样的效率并没有得到提升。
红黑树
红黑树是一种自平衡的二叉搜索树,它在二叉搜索树的基础上引入了额外的颜色属性,并通过一系列规则来确保树的平衡,从而保持各种操作的高效性。受过408摧残的小伙伴们应该都看过王道视频,听过这么一句话:左根右、根叶黑、不红红、黑路同,这句”名言“就是攘括了红黑树的特点。
左根右:左子树节点值<根节点值<右子树节点值
根叶黑:根节点和叶子节点(NIL节点)都是黑色
不红红:不能出现红色节点的子节点是红色
黑路同:任意节点到其叶子节点的每条路径上,黑色节点的数量相同
简单了解红黑树之后,假设我们根据id建立了一棵红黑树作为索引。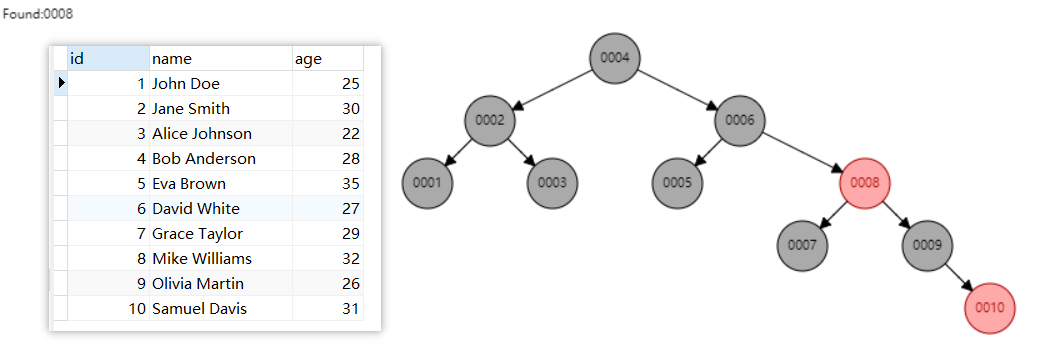
当我们查询id=5的数据,通过红黑树去查询就只要3次,查询效率明显有所提高。但是为什么MySQL底层也不是以红黑树作为底层结构呢? 红黑树对于高度的敏感度较低,有时可能导致树高相对较高,从而增加了查询的复杂性。如果树越高,查询效率也就会越低。在现实中,当数据库存储了几百万条数据,这时候树的高度会非常高,假设查询的数据在高度为10的位置,那么mysql也要进行10次的查询,也就需要进行了10次磁盘I/O,这样的效率是不高的。
B-树
B树(B-tree)是一种自平衡的树状数据结构,用于组织和存储有序数据。
B树是一种平衡的多分树,通常我们说m阶的B树,它必须满足如下条件:
- 每个节点最多只有m个子节点。
- 每个非叶子节点(除了根)具有至少? m/2?子节点。
- 如果根不是叶节点,则根至少有两个子节点。
- 具有k个子节点的非叶节点包含k -1个键。
- 叶节点具有相同的深度,叶节点的指针为空。
B树的高度是可控的,每个节点可以存放许多索引。所以当同样存放几百万数据的时候,树的高度也就不至于特别高,查询的效率会比红黑树高。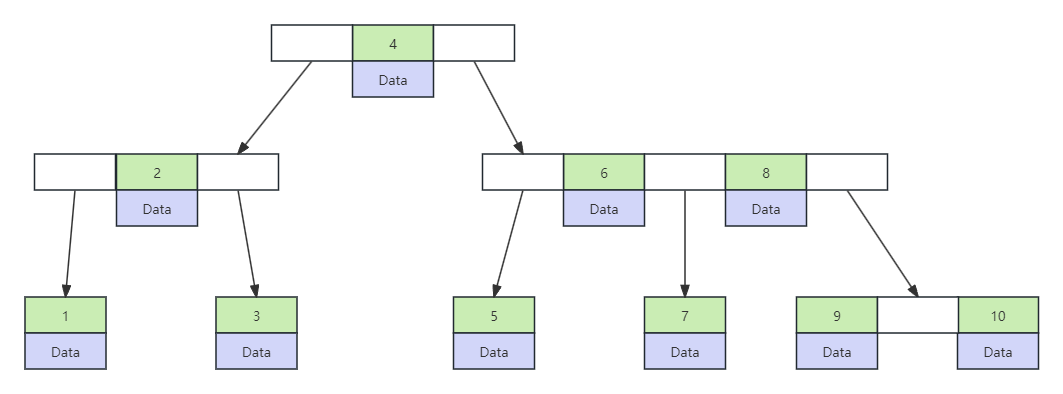
如上草图可以清晰看到以id创建索引使用B树作为数据结构的样子,数据都是存储到每个节点中。然而,mysql底层也不是以B树作为数据结构,而是使用B+树,我们直到,B+树就是B树的一种,它是B树的一种改进。B+树的效率会比B树的效率来得高。
B+树
B+树与B树大差不差,B+树的非叶子节点只包含键值信息,而不包含实际的数据。这减少了非叶子节点的大小,我们知道,存储数据是会占用磁盘,然而B+树将非叶子节点的数据都移动到叶子节点,使得一个磁盘页可以容纳更多的节点,提高了存储效率。叶子节点是包含了所有的索引字段,并且是有序的,有序性使得范围查询效率更高。叶子节点用指针连接,提高了区间访问的性能。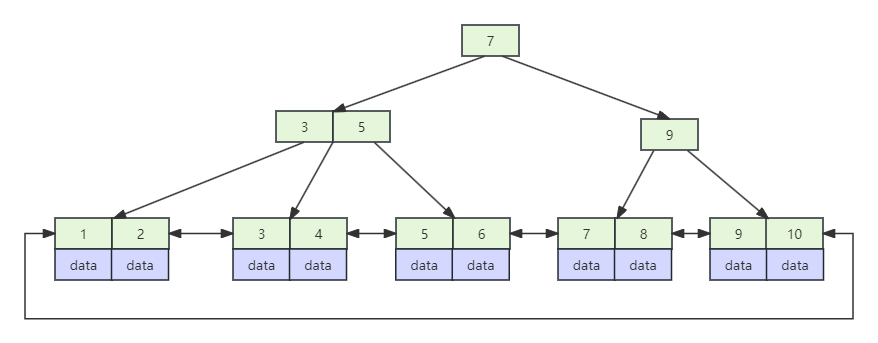
上图就是mysql索引的底层结构,叶子节点是存储了所有的索引字段,并且不在将数据存储在非叶子节点,而是采取只存在叶子节点中。
那么,这种数据结构在MySQL数据量太大的时候会导致高度太高嘛?我们先来查看mysql文件页大小:SHOW GLOBAL STATUS LIKE 'Innodb_page_size';就会看到输出16384字节,即16KB,也就是每个节点分配的磁盘空间是16KB。这里,我来详细阐述一下,如以下图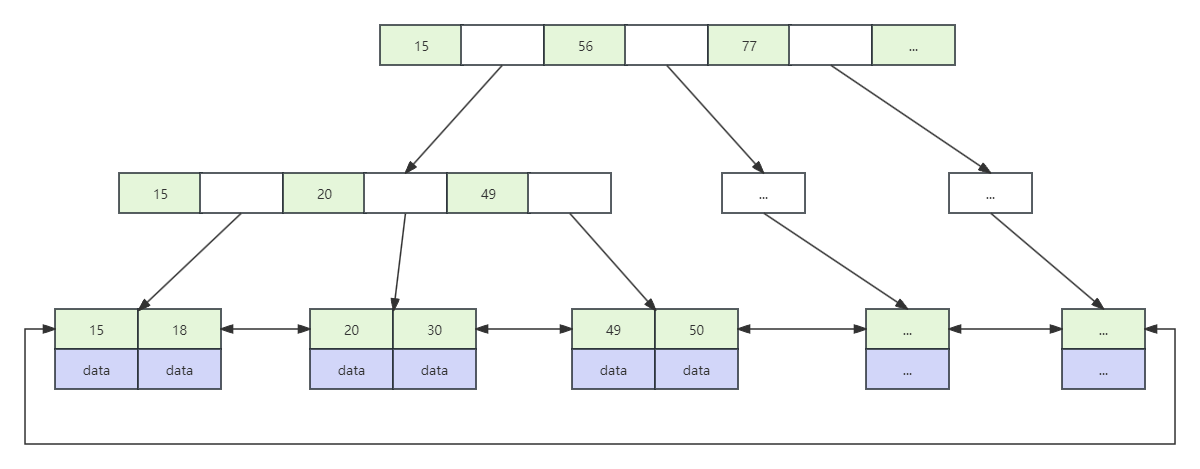
加入说索引类型是bigint(8字节),存储下一层磁盘地址大小是6字节(MySQL默认分配大小),也就是一个节点最多能存放16KB/(8+6)B=1170个索引键值。假设高度是3,并且元素把节点撑满,这里需要注意下,叶子节点可能是存放着数据以及索引键值,我们就假设一共是1KB大小,也就是一个节点可以存放16个,那么总共就是1170117016等于两千多万。那也就意味着,当有两千多万行数据,只要合理的走了索引,那么效率是非常高的,如果需要查找索引值是30的数据,那么走索引也就只需要进行3次的磁盘I/O。
MySQL的B+树结构索引,其叶子节点是有序依次递增,并且是双向指针(子节点也有存储指针的位置),这也就使得B+树结构是能给满足IN(范围查找)。假设需要查找20<col<49的数据,只需要定位到20,依次递增查找,直到找到49为止,遍历的数据都是需要的数据,这样就不用查找全表。
Hash
我们在创建索引的时候,索引方法还有一种,就是哈希索引,使用哈希函数将键映射到索引的存储位置,结构也就是一维数组+二维链表。与传统的B+树索引不同,哈希索引在理想情况下可以提供O(1)的查找复杂度。其采用通过索引键值进行哈希计算,在进行取模运算的到数据存储位置。
如上图,我们假设计算出来的存放位置如图。哈希索引在一定程度的速度会比B+树来的快,但是仅能满足"=“,不能满足"IN”。如图可以看出来,还有一个问题,就是会发生hash冲突,当冲突比较多的时候,需要进行冲突解决,就会用链表追加到后面,查询的时候也是需要再去遍历,而哈希索引存储的除了哈希key,还有对应的磁盘地址,还需要根据地址再去查询一编,整体的效率是没有B+树来得好,所以在日常开发基本不会使用hash索引。
MySQL索引的底层存储
MySQL索引的底层存储实现取决于所使用的存储引擎,不同的存储引擎,其索引结构也是有所区别。MySQL支持多种存储引擎,其中两个常用的引擎是InnoDB和MyISAM。这里也是介绍这两种存储引擎的索引结构。
首先,我们先要知道MySQL的索引文件存储在我们MySQL文件下的data文件夹下面。在data下面会根据表名创建了对应的文件夹名。
D:\ProgramFiles\mysql-8.0.30\data\test
聚簇索引与非聚簇索引
这里简单了解一下聚簇索引与非聚簇索引。
- 聚簇索引(Clustered Index)
- 聚簇索引就是叶子节点存放了索引键值以及对应行的全部数据
- 非聚簇索引(Non-clustered Index)
- 非聚簇索引的索引键值与实际数据是分开存储的,叶子节点只是存储了指向存放数据块的指针。
MyISAM存储引擎索引
MyISAM中的索引是非聚簇索引,即索引和实际数据行是分开存储的。叶子节点存储索引键值和指向实际数据行的指针。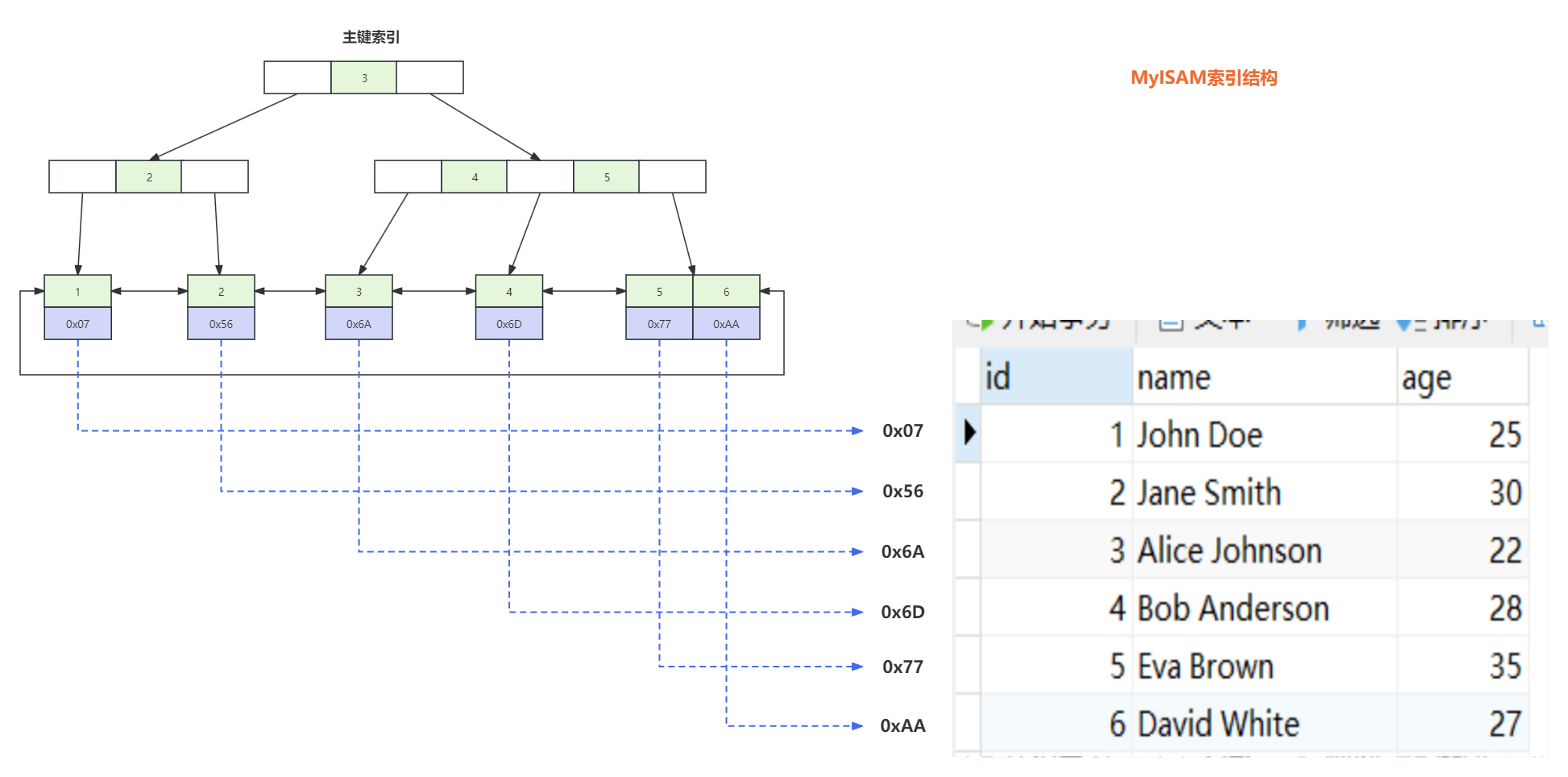
在索引文件存储的目录下,我们可以看到MyISAM存储引擎创建的两个文件:xxx.MYD和xxx.MYI文件,我们知道MyISAM存储引擎是非聚簇索引,也就是索引文件和数据文件是相互分开的。
- xxx.
MYD: 存储叶子节点对应的地址中数据 - xxx.
MYI: 存储的索引的结点数据
假设我们要查询表中id=5的数据,其SQL语句:
SELECT * FROM `test_innodb` WHERE id = 5
我们需要了解其底层查找原理。在MySQL中,首先会先看查询条件,判断查询条件是不是索引列,这里创建了id的主键索引,所以它是索引列,这样就会走索引。在MyISAM存储引擎中,会先到.MYI根据索引值查找对应的磁盘地址,再到.MYD文件查找数据,这样的操作就是回表(“Bookmark Lookup”)。
回表:简单描述回表就是非聚簇索引根据索引值获取到磁盘地址,再根据地址去获取数据。
:::success
当一个表上存在非聚簇索引,而查询语句需要检索表中的数据行时,数据库引擎首先使用非聚簇索引找到匹配的行的主键值(或者聚簇索引的键值)。然后,使用这些主键值再次在表的聚簇索引(或堆表)中进行查找,以获取实际的数据行。这个两步的过程,第一步通过非聚簇索引找到主键值的过程称为“索引扫描”或“索引查找”,而第二步通过主键值再次在表中查找的过程称为“回表”。
:::
回表的过程可能会导致额外的磁盘I/O和性能开销,因为它需要在两个不同的地方进行查找。
InnoDB存储引擎索引
InnoDB存储引擎表的数据和索引存储在.idb文件中,所以在数据文件夹下就会看到有这么一个文件。
InnoDB存储引擎是B+树组织的索引结构文件,它的实现是聚簇索引。叶子节点不仅记录了索引键值,还记录着行的各个字段数据。如图,当阶数=3的时候。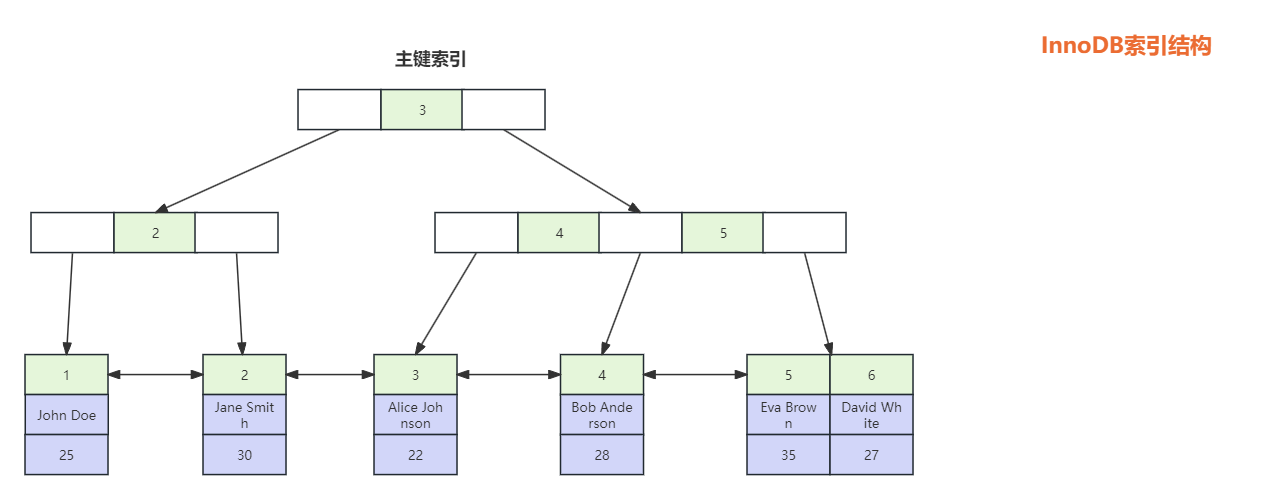
如上SQL:SELECT * FROM test_innodb WHERE id = 5,通过索引定位到的叶子节点,就直接获取了数据。
上面创建的索引是主键索引,那如果我们不用主键来创建索引。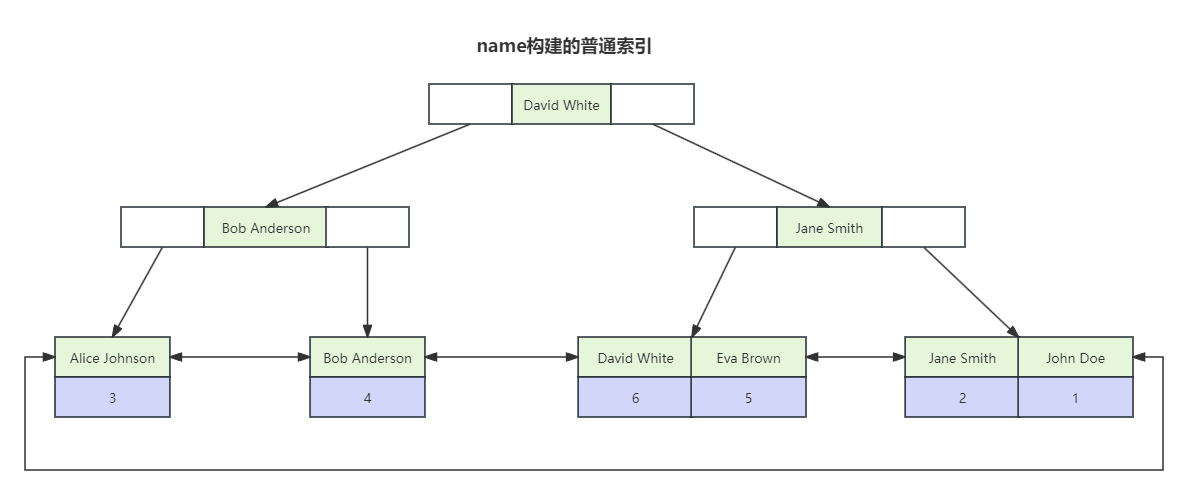
如上图,通过name字段来创建一个普通索引,那么这个索引树的叶子节点存储的是主键值,这种也是非聚簇索引。查询的时候,会根据普通索引去定位到主键值,再通过主键值去主键索引定位到具体数据,这里也就是发生了回表。
当我们通过name查找数据的时候
SELECT * FROM `test_innodb` WHERE `name` = 'Jane Smith'
这条SQL就会走name构建的普通索引,从而获得主键值:2,再去主键索引去查找得到数据。
以上两个例子也就很好的阐述了什么是聚簇索引,什么是非聚簇索引。
疑问散开
然而,知道了MyISAM存储引擎与InnoDB存储引擎,也了解了聚簇/非聚簇索引,以及知道了索引是怎么走的,结构是如何的,那么这就会引发出一些疑问。而这些疑问恰好也是我们得以提升的点,知其然知其所以然。
1)、InnoDB表建议要有主键,并且是整型、自增
首先,我们得先明确,为什么InnoDB需要有主键呢?因为InnoDB表在构建的时候就必须要用B+树来存储数据,而这个B+树需要有个索引结构,也就是会用主键来创建。如果没有索引,mysql会将唯一主键来创建主键索引,但如果一个主键都没有,又没有唯一索引,MySQL就会使用隐藏列(RowId,这是MySQL自己维护的隐藏列)来创建B+树存储整张表的数据。这样是会降低性能的。这就是为什么建议创建主键。
其次,为什么需要整型的呢?主要还是在查找数据的时候,会根据索引去比较,如果是整型的就会直接进行比较。但如果是字符串,比较的时候是将字符一位一位进行比较,如果还是使用了uuid,那比较速度显然就没有整型的快。
为什么要有序自增?当不是自增的时候,mysql底层构建的b+树就会自动平衡,这个操作是会消耗性能的,如果是自增的情况,只会往后面插入,就不会说是会有变化的操作。在日常开发中,大多都是会使用雪花算法,虽然雪花算法不是严格递增的,但其趋势是递增的。如果插入的数据不是自增的,在插入的时候,是先查找定位到相应的位置,如果定位到两数之间,而B+树是一种自平衡的结构,能够动态地调整结构以保持平衡,会自动维护成有序的结构,在中间插入数据的时候可能需要进行分裂操作,这个操作是会消耗性能的。如果是自增的,那就会往后一直插入,分裂操作就不会那么频繁。这个对于插入操作的效率是比较高。
2)、为什么不建议使用uuid而推荐id自增作为主键
正如以上**1)**所介绍的那样,uuid不是自增也不是整型,需要尽量用整型数据,因为需要比较大小,整型比较速度在一定程度上会快点。而uuid是字符串,需要逐位比较,会影响效率。
联合索引
联合索引是指在数据库表中针对多个列创建的索引。与单列索引不同,联合索引涵盖了多个列,以提高多列查询的性能。当查询条件涉及到联合索引中的列时,数据库可以更有效地定位数据。
那么联合索引的结构又是什么样子呢?实际上,在B+树中,联合索引的每个节点上的索引元素是设定的联合索引对应的字段。
CREATE INDEX idx_name_address ON test_innodb (`name`, address) USING BTREE;
如以上语句创建了name、address的联合索引,那么索引的结构会先根据name排序再跟address排序。最后叶子节点会存储主键,在通过主键去获取数据。大致结构如图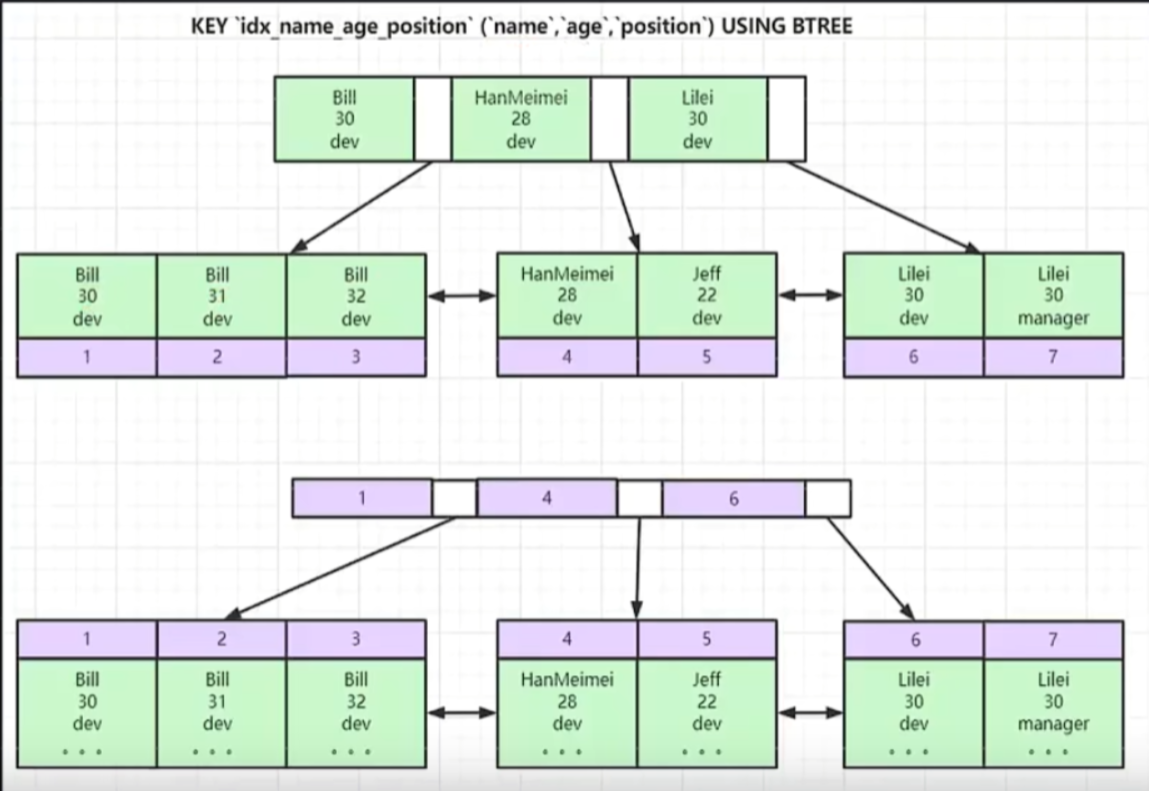
最左前缀优化
先来看几条sql语句,我们可以通过EXPLAIN来查看SQL是否走了索引,对于EXPLAIN的使用,下篇文章会对其的使用进行详细的阐述。
CREATE INDEX idx_name_address ON test_innodb (`name`, address) USING BTREE;
EXPLAIN SELECT * FROM test_innodb WHERE `name` = 'John Doe' AND address = 'fj';
EXPLAIN SELECT * FROM test_innodb WHERE age = 25 AND address = 'fj';
EXPLAIN SELECT * FROM test_innodb WHERE address = 'fj';
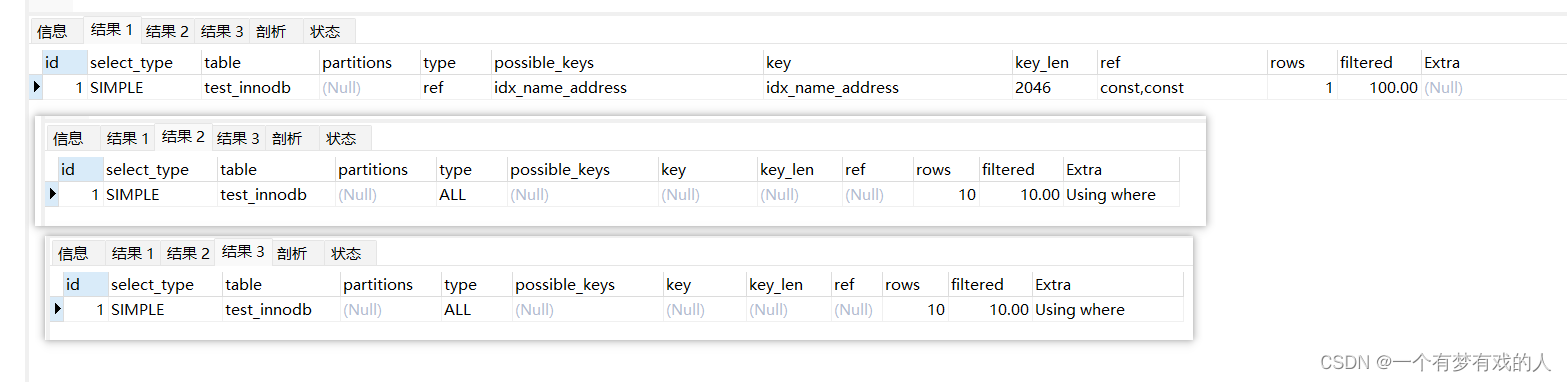
可见只有第一句走了索引,这就是最左前缀规则。当我们创建name、address联合索引,要想用到address索引就必须先用name索引,这是因为在联合索引的底层结构是先根据name排序后才根据address进行排序。在联合索引,需要先走前面的索引。比如有联合索引(col1, col2, col3),比如 WHERE col2 = ‘value’ 或者 WHERE col3 = ‘value’。这些都是不会走索引的,那么如果是 WHERE col1 =‘value’ AND col3 = ‘value’,这条语句只会走col1这个索引。
这个规则的原因在于,B+树索引的结构决定了最左前缀的性质。B+树的分支节点包含了索引的最左边的值,而在树的内部节点和叶子节点上,索引的其余部分按顺序存储。
在设计联合索引时,可以根据实际查询的情况来考虑列的顺序,以使得最常用的查询条件能够利用最左前缀规则。
总结
此次学习了索引的底层原理,对比了各种数据结构充当索引的利弊。对MyISAM存储引擎索引和InnoDB存储引擎索引进行细化学习分析。也对联合索引的构成和最左前缀优化进行阐述,只有EXPLAIN的使用没有在本文章体现,这个将会在下篇文章进行描述。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 4、机器学习的模型验证
- 一文让你快速写出高效的软件测试用例
- 【无标题】
- 【老牌期刊】IF:6+,2天预审,3-5个月录用!
- SAP ABAP BUG解决 founction alv 单程序多个alv页面,设置布局所有alv页面均改变
- 加密的艺术:对称加密的奇妙之处(上)
- Android.bp详解+入门必备
- 虚幻商城 蓝图汇总
- NIST力荐的PQC算法,如今再现致命漏洞!
- 工程机械比例阀电流采集方案——IPEhub2与IPEmotion APP