python实训:简易车牌识别
实验要求:使用opencv和python工具建立一个车牌识别系统
车牌文字识别系统的主要功能:车牌图片预处理对车牌的颜色进行检测再对车牌进行中值模糊,灰度图和顶帽处理处理掉图像的噪点等功能为轮廓检测做准备;车牌轮廓检测通过对预处理的图片进行边缘检测,通过设定的值找到相应的轮廓,再将轮廓通过cv2.drawContours将轮廓画出来保存在文件夹中;车牌处理变成黑底白字图通过预处理操作去掉多余噪点,然后进行二值化处理变成黑底白字再对图像进行膨胀处理防止中文字符分为两个,其次对图像的边框再进行一次掩膜处理防止出现切割边框;最后就是字符匹配要准备数据集与切割的字符进行一个匹配得分的操作,计算最高得分,返回最高得分然后得出字符名称,返回一个车牌的字符串。
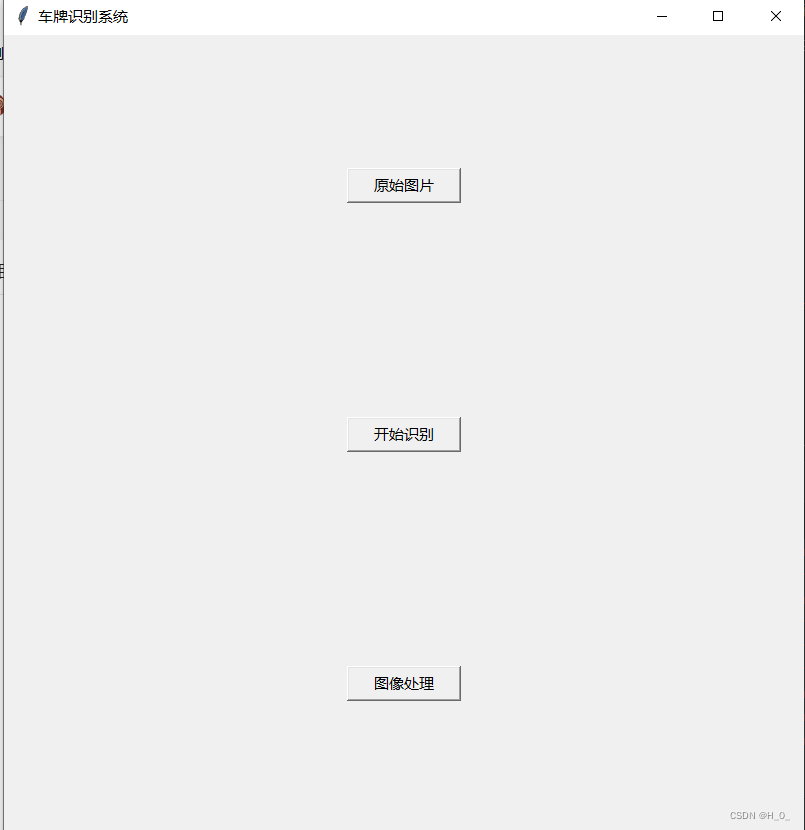
界面设计:设置gui界面的大小和题目,选择图像的按钮,弹窗选择本地的测试图片,图片已放在同一文件夹下,方便选择;图像处理的按钮,点击可以对选择的图像的处理变成黑底白字的团片显示在gui界面上,开始识别按钮,点击开始识别之后会对图像进行字符切割和模板匹配操作,然后会有一个字符显示,识别结果显示区域显示识别出的完整的车牌号码。
车牌定位算法:使用了Canny边缘检测+形态学处理,形态学中运用了高斯滤波处理还有灰度处理,中值滤波,礼貌操作还有开闭运算,膨胀处理等对图像进行处理,Canny边缘检测用于检测图像中的强边缘,如何通过画轮廓将轮廓保存下来。
字符分割算法:先对图像进行一个上下边缘处理,尽可能的去掉边缘噪点,然后通过画直方图确定波峰,还有统计黑白像素点,对可能是字符的波峰和点进行保存,然后通过循环算法对字符进行一个分割,分割字符不达标或者超过所定的分割字符,将改动一些变量再进行下一次循坏,这样能更加准确的分割所要字符。
模板匹配算法:首先有一个template的一个模板字符,需要拥有一个数据集,我是准备了两个数据集,一个数据集中文匹配度高,另一个匹配英文和数字匹配度高,然后去遍历文件夹中的所有文件夹,然后先对第一个字符匹配中文,然后匹配第二个字的英文,后面再依次匹配,通过匹配得分来返回一个对该字符匹配度最高的得分,选择它为这个字的字符,然后输出字符串。
部分代码:
import cv2
from tkinter import *
import tkinter as tk
from tkinter import messagebox
from tkinter.filedialog import askopenfilename
from PIL import Image, ImageTk
import numpy as np
import matplotlib.pyplot as plt
import os
class LicensePlateRecognitionGUI:
def __init__(self, window):
self.window = window
self.window.title("车牌识别系统")
self.window.geometry("800x800")
# 创建图像显示区域
self.image_label = tk.Label(window)
self.image_label.pack(side='bottom',ipadx=20,expand=0,fill=X)
self.label1 = Label(window)
self.label1.pack(anchor='w',side='top',ipadx=20,expand=0,fill=X)
# 创建按钮
self.load_button_original = tk.Button(
window, text="原始图片", command=self.load_original_image)
self.load_button_original.pack(ipadx=20,expand=1)
self.recognize_button = tk.Button(
window, text="开始识别", command=self.recognize_plate)
self.recognize_button.pack(ipadx=20,expand=1)
self.load_button = tk.Button(
window, text="图像处理", command=self.load_image)
self.load_button.pack(ipadx=20,expand=1)
def load_original_image(self):
file_path = tk.filedialog.askopenfilename()
if file_path:
self.image_path = file_path
self.image = Image.open(file_path)
self.image = self.image.resize((350, 200))
self.photo= ImageTk.PhotoImage(self.image)
self.label1.configure(image=self.photo)
self.label1.image = self.photo
return self.image_path
def display_image(self, image):
# 将图像显示在界面上
img = Image.fromarray(image)
img = img.resize((250, 100))
img_tk = ImageTk.PhotoImage(img)
self.image_label.configure(image=img_tk)
self.image_label.image = img_tk这是导入相关库和设置gui界面的部分代码展示
界面设计如下:
算法设计部分代码
filename = self.image_path
if filename:
img = cv2.imread(filename)
def color_position(img,output_path):
colors = [([26,43,46], [34,255,255]), # 黄色
([100,43,46], [124,255,255]), # 蓝色
([35, 43, 46], [77, 255, 255]) # 绿色
]
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
for (lower, upper) in colors:
lower = np.array(lower, dtype="uint8") # 颜色下限
upper = np.array(upper, dtype="uint8") # 颜色上限
# 根据阈值找到对应的颜色
mask = cv2.inRange(hsv, lowerb=lower, upperb=upper)
output = cv2.bitwise_and(img, img, mask=mask)
k = mark_zone_color(output,output_path)
if k==1:
return 1
# 展示图片
#cv2.imshow("image", img)
#cv2.imshow("image-color", output)
#cv2.waitKey(0)
return 0
def mark_zone_color(src_img,output_img):
#根据颜色在原始图像上标记
# 高斯模糊
blured = cv2.GaussianBlur(src_img, (3, 3), 0, 0, cv2.BORDER_DEFAULT)
#转灰度
gray = cv2.cvtColor(blured,cv2.COLOR_BGR2GRAY)
# 双边滤波模糊
gray= cv2.bilateralFilter(gray,3,45,45)
#礼帽操作,突出更明亮的区域
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (17,17))
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, kernel)
#图像二值化
ret,binary = cv2.threshold(tophat,0,255,cv2.THRESH_BINARY)
#轮廓检测
contours,hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)
#drawing = img
#cv2.drawContours(drawing, contours, -1, (0, 0, 255), 3) # 填充轮廓颜色
#cv2.imshow('drawing', drawing)
#cv2.waitKey(0)
#print(contours)首先是加载图片,tk.filedialog.askopenfilename()通过此函数得到图片的路径,读取图像数据。通过设定的colors的阈值然后通过for循环的颜色上下限对图像没有用的地方进行一个mask掩膜操作,然后是通过def mark_zone_color(src_img,output_img)此函数对图像进行处理,比如高斯模糊操作 cv2.GaussianBlur(src_img, (3, 3), 0, 0, cv2.BORDER_DEFAULT),然后转灰度cv2.cvtColor(blured,cv2.COLOR_BGR2GRAY)等操作。然后通过二值化处理进行cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)的一个边框检测找到所要的车牌轮廓,并由cv2.imwrite(output_img + '/' + 'card_img' + '.jpg',card_img)保存;
找到轮廓后通过def char_segmentation (thresh)此函数对图像进行字符分割并保存字符图片。首先我们要对所保存的车牌轮廓一个预处理转换成灰度图,然后二值化处理,最后通过cv2.threshold(tophat,127,255,cv2.THRESH_OTSU | cv2.THRESH_BINARY_INV)对图像进行一个黑底白字的处理,通过这两个循环for i in range(height)for j in range(width)遍历每一个像素,确保能得到黑底白字。
最后效果图如下:

运行软件为anaconda中的Jupyter Notebook。
图片和数据集网上收集资料
最终的结果还有很多不足,有些车牌无法正确识别,对绿牌和黄牌的实现效果也不行,绿牌无法实现最后一位数字,需要数据集和代码的请关注并私信我。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java并发 - Java中所有的锁
- 美易官方:Oppenheimer将美国电话电报公司评级上调至跑赢大盘,目标价21美元
- 揭秘家用缝纫机电机霍尔板的多功能特性
- 为什么重写equals时一定要重写hashCode?
- x-cmd pkg | doggo - 现代化的 DNS 客户端
- Docker-Compose 部署微服务集群
- linux下各种工具通过代理上网的配置方式
- Vue中的v-model
- Linux目录和文件管理
- 有关quick bi中lod_include函数有多个过滤条件报错问题分析