序列生成模型(一):序列概率模型
前言
??深度学习在处理序列数据方面取得了巨大的成功,尤其是在自然语言处理领域。序列数据可以是文本、声音、视频、DNA序列等,在深度学习中,我们可以将它们看作是符合一定规则的序列。
1. 序列数据
??序列数据在深度学习应用中非常常见,它们是按照时间顺序或者其他顺序排列的数据集合。序列数据的处理通常涉及到捕捉数据中的时间关系、趋势和模式,因此需要使用专门的模型来处理这些信息。以下是一些常见的序列数据类型以及相应的深度学习应用:
-
文本数据: 序列数据可以是自然语言文本,如文章、评论、推文等。循环神经网络(RNN)和变压器(Transformer)等模型常用于处理自然语言处理任务,如机器翻译、情感分析等。
-
音频数据: 音频信号是一个时间序列,常见于语音识别、音乐生成等领域。卷积神经网络(CNN)和循环神经网络(RNN)等被用于处理音频序列。
-
视频数据: 视频是由一系列帧组成的序列数据。时序卷积神经网络(3D CNNs)和变压器(Transformer)等模型用于视频分类、行为识别等任务。
-
时间序列数据: 包括金融数据、气象数据、股票价格等。循环神经网络(RNN)、长短时记忆网络(LSTM)和变压器(Transformer)等用于建模时间序列的动态关系。
-
生物信息学中的DNA序列: 序列数据也出现在生物信息学领域,如基因组学中的DNA序列。深度学习可以用于分析基因序列,预测蛋白质结构等任务。
2. 序列数据的潜在规律
??在自然语言中,句子的理解涉及到语法、语义和上下文等多个层面。如下两个句子:
- 面包上涂黄油。
- 面包上涂袜子。
??在语法和语义上,这两个句子都符合一定的规则,但在语义上,第二个句子明显违背了常识,因为袜子通常不是涂抹在面包上的东西。这个违背常识的地方不容易通过传统的语法规则捕捉到,而需要更深层次的语义理解。
??这种理解不仅仅涉及到词汇的语义,还包括对真实世界的知识和常识的理解。在深度学习中,一些模型,尤其是预训练的语言模型,例如BERT(Bidirectional Encoder Representations from Transformers)等,通过大量的文本数据进行训练,试图学习到更深层次的语义和常识。
??通过将文本序列看作是随机事件,我们可以使用深度学习模型来建模这些事件的概率分布。
3. 序列概率模型的两个基本问题
??序列概率模型与一般的概率模型类似,主要面临两个基本问题:
-
概率密度估计(Probability Density Estimation):
- 问题描述: 给定一组序列数据 x 1 : T = x 1 , x 2 , … , x T \mathbf{x}_{1:T} = x_1, x_2, \ldots, x_T x1:T?=x1?,x2?,…,xT?,概率密度估计的目标是估计这些数据背后的概率分布,即 p ( x 1 : T ) p(\mathbf{x}_{1:T}) p(x1:T?)。
- 应用: 这个问题在统计建模和机器学习中非常常见,特别是在自然语言处理、语音识别、生物信息学等领域,我们希望通过模型来理解和捕捉序列数据中的潜在规律。
-
样本生成(Sample Generation):
- 问题描述: 给定一个学习过的序列分布 p ( x 1 : T ) p(\mathbf{x}_{1:T}) p(x1:T?),样本生成的目标是从这个已知的分布中生成新的序列样本。
- 应用: 样本生成在生成式模型中非常重要,例如,在自然语言生成、图像生成、音乐生成等任务中,我们希望模型能够生成符合特定规律或者语境的新序列。
??解决这两个问题的方法通常依赖于具体的序列概率模型。常见的序列概率模型包括隐马尔可夫模型(HMM)、循环神经网络(RNN)、长短时记忆网络(LSTM)、变压器(Transformer)等。这些模型在深度学习中被广泛应用,能够学习并捕捉序列数据中的复杂关系,从而进行概率密度估计和样本生成。
一、序列概率模型
1. 理论基础
序列的概率分解
??在序列概率模型中,考虑到序列数据的两个特点:变长和样本空间巨大,我们难以直接建模整个序列的概率。针对这个问题,可以使用概率的乘法公式对序列的概率进行分解。
??对于一个长度为 T T T 的序列 x 1 : T = x 1 , x 2 , … , x T \mathbf{x}_{1:T} = x_1, x_2, \ldots, x_T x1:T?=x1?,x2?,…,xT?,其样本空间为 ∣ V ∣ T |\mathcal{V}|^T ∣V∣T,其中 V \mathcal{V} V 表示词表。根据概率的乘法公式,序列的概率可以表示为:
p ( x 1 : T ) = p ( x 1 ) ? p ( x 2 ∣ x 1 ) ? p ( x 3 ∣ x 1 : 2 ) ? … ? p ( x t ∣ x 1 : ( t ? 1 ) ) p(\mathbf{x}_{1:T}) = p(x_1) \cdot p(x_2 | x_1) \cdot p(x_3 | \mathbf{x}_{1:2}) \cdot \ldots \cdot p(x_t | \mathbf{x}_{1:(t-1)}) p(x1:T?)=p(x1?)?p(x2?∣x1?)?p(x3?∣x1:2?)?…?p(xt?∣x1:(t?1)?)
上述概率可以进一步写为:
p ( x 1 : T ) = ∏ t = 1 T p ( x t ∣ x 1 : ( t ? 1 ) ) p(\mathbf{x}_{1:T}) = \prod_{t=1}^{T} p(x_t | \mathbf{x}_{1:(t-1)}) p(x1:T?)=t=1∏T?p(xt?∣x1:(t?1)?)
其中, x t ∈ V x_t \in \mathcal{V} xt?∈V 表示序列在位置 t t t 上的取值, t ∈ { 1 , … , T } t \in \{1, \ldots, T\} t∈{1,…,T},并且假设 p ( x 1 ∣ x 0 ) = p ( x 1 ) p(x_1 | x_0) = p(x_1) p(x1?∣x0?)=p(x1?)。
??序列数据的概率密度估计问题转化为单变量的条件概率估计问题。这种转化的好处在于我们将整个序列的联合概率分布分解成了各个时刻上变量的条件概率的乘积,使得我们可以更容易地处理每个时刻的条件概率估计,而不需要直接对整个序列的联合概率进行建模。
??这种分解的思想为使用自回归生成模型(如循环神经网络、变压器等)建模序列提供了理论基础。这些模型在每个时刻上生成一个新的变量,依赖于前面时刻的变量,从而能够捕捉到序列中的复杂依赖关系。
自回归生成模型
??在给定一个包含 N N N 个序列数据的数据集 D = { x 1 : T n ( n ) } n = 1 N \mathcal{D} = \{\mathbf{x}^{(n)}_{1:T_n}\}_{n=1}^{N} D={x1:Tn?(n)?}n=1N? 的情况下,序列概率模型的学习目标是通过最大化整个数据集的对数似然函数来学习模型参数 θ \theta θ。即我们希望学习一个模型 p θ ( x t ∣ x 1 : ( t ? 1 ) ) p_\theta(\mathbf{x}_t | \mathbf{x}_{1:(t-1)}) pθ?(xt?∣x1:(t?1)?),其中 t t t 表示序列中的时间步。
- 对数似然函数的表达式为: max ? θ ∑ n = 1 N ∑ t = 1 T n log ? p θ ( x t ( n ) ∣ x 1 : ( t ? 1 ) ( n ) ) \max_{\theta} \sum_{n=1}^{N} \sum_{t=1}^{T_n} \log p_\theta(x^{(n)}_t | \mathbf{x}^{(n)}_{1:(t-1)}) θmax?n=1∑N?t=1∑Tn??logpθ?(xt(n)?∣x1:(t?1)(n)?)这里的 p θ ( x t ( n ) ∣ x 1 : ( t ? 1 ) ( n ) ) p_\theta(x^{(n)}_t | \mathbf{x}^{(n)}_{1:(t-1)}) pθ?(xt(n)?∣x1:(t?1)(n)?) 表示在给定前面时刻的变量的条件下,预测当前时刻变量的概率。
??在这种序列模型中,每一步都需要将前面的输出作为当前步的输入,这符合自回归(AutoRegressive)的方式。因此,这一类模型也被称为自回归生成模型(AutoRegressive Generative Model)。
??由于
X
t
∈
V
X_t \in \mathcal{V}
Xt?∈V 为离散变量,可以假设条件概率
p
θ
(
x
t
∣
x
1
:
(
t
?
1
)
)
p_\theta(x_t | \mathbf{x}_{1:(t-1)})
pθ?(xt?∣x1:(t?1)?) 服从多项分布,它的概率函数可以写成:
p
(
x
t
∣
x
1
:
(
t
?
1
)
)
=
Multinomial
(
x
t
∣
θ
t
)
p(x_t | \mathbf{x}_{1:(t-1)}) = \text{Multinomial}(\mathbf{x}_t | \boldsymbol{\theta}_t)
p(xt?∣x1:(t?1)?)=Multinomial(xt?∣θt?)
其中, Multinomial ( x t ∣ θ t ) \text{Multinomial}(\mathbf{x}_t | \boldsymbol{\theta}_t) Multinomial(xt?∣θt?) 表示在给定参数 θ t \boldsymbol{\theta}_t θt? 的情况下,随机变量 x t x_t xt? 取值为 x t \mathbf{x}_t xt? 的概率。
??在深度学习中,通常采用神经网络来建模这个多项分布的参数 θ t \boldsymbol{\theta}_t θt?,两种主要的自回归生成模型是 N 元统计模型和深度序列模型。
-
N元统计模型: 这是一种传统的方法,其中 N N N 表示模型考虑的上下文的大小。N元统计模型基于马尔可夫假设,即当前时刻的变量仅依赖于前 N ? 1 N-1 N?1 个时刻的变量。N元统计模型使用 N 元语法模型来建模条件概率。
-
深度序列模型: 基于深度学习的方法,使用神经网络来建模条件概率。循环神经网络(RNN)、长短时记忆网络(LSTM)、变压器(Transformer)等神经网络结构可以用于建模序列数据中的长期依赖关系。
??这两种方法都有各自的优势和局限性,选择取决于任务的性质、数据的特点以及计算资源的可用性。深度序列模型通常能够更灵活地捕捉序列中的复杂关系,但在某些情况下,N元统计模型可能仍然是一个有效的选择。
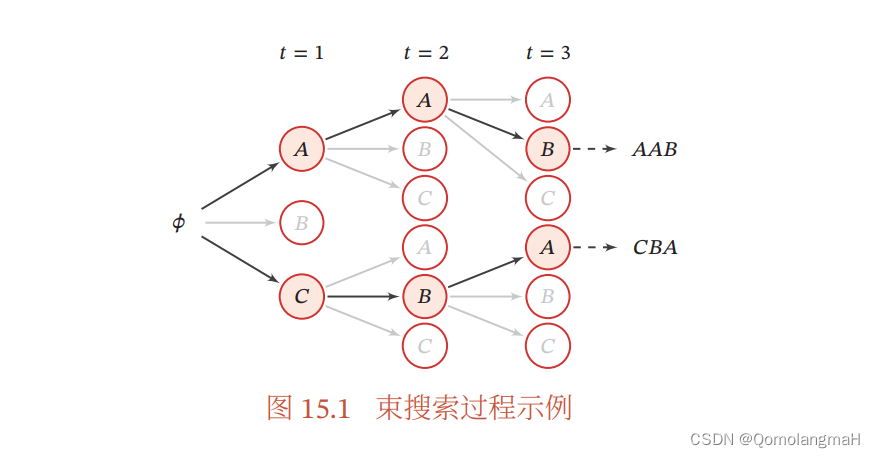
2. 序列生成
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一条SQL执行的过程
- 电脑资料在回收站删除还能找回来吗?如何恢复
- ChatGPT人工智能对话系统源码 一款非常强大的AI智能系统 附带完整的搭建教程
- JavaScript对象操作方法详解(获取、添加、删除、循环、获取所有属性、检查字段)
- 新一代工厂融合广播系统,助力工业行业可持续发展
- 电影泰坦尼克号带特效带音乐(4页) HTML+CSS+JavaScript
- 《深入理解JAVA虚拟机笔记》Class文件格式、字节码指令
- linux命令速查表
- FTP简介&搭建FTP与配置FPT&计算机端口介绍[Windows2012]
- 力扣hot100 二叉树中的最大路径和 递归