CEEMDAN +组合预测模型(Transformer - BiLSTM+ ARIMA)
目录
3 基于CEEMADN的 Transformer - BiLSTM 模型预测
3.1 定义CEEMDAN-Transformer - BiLSTM预测模型

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型-CSDN博客
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型-CSDN博客
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)-CSDN博客
前言
本文基于前期介绍的风速数据(文末附数据集),介绍一种综合应用完备集合经验模态分解CEEMDAN与混合预测模型(Transformer - BiLSTM +?ARIMA)的方法,以提高时间序列数据的预测性能。该方法的核心是使用CEEMDAN算法对时间序列进行分解,接着利用Transformer - BiLSTM模型和ARIMA模型对分解后的数据进行建模,最终通过集成方法结合两者的预测结果。
风速数据集的详细介绍可以参考下文:
1 风速数据CEEMDAN分解与可视化
1.1 导入数据
 ?
?
1.2 CEEMDAN分解
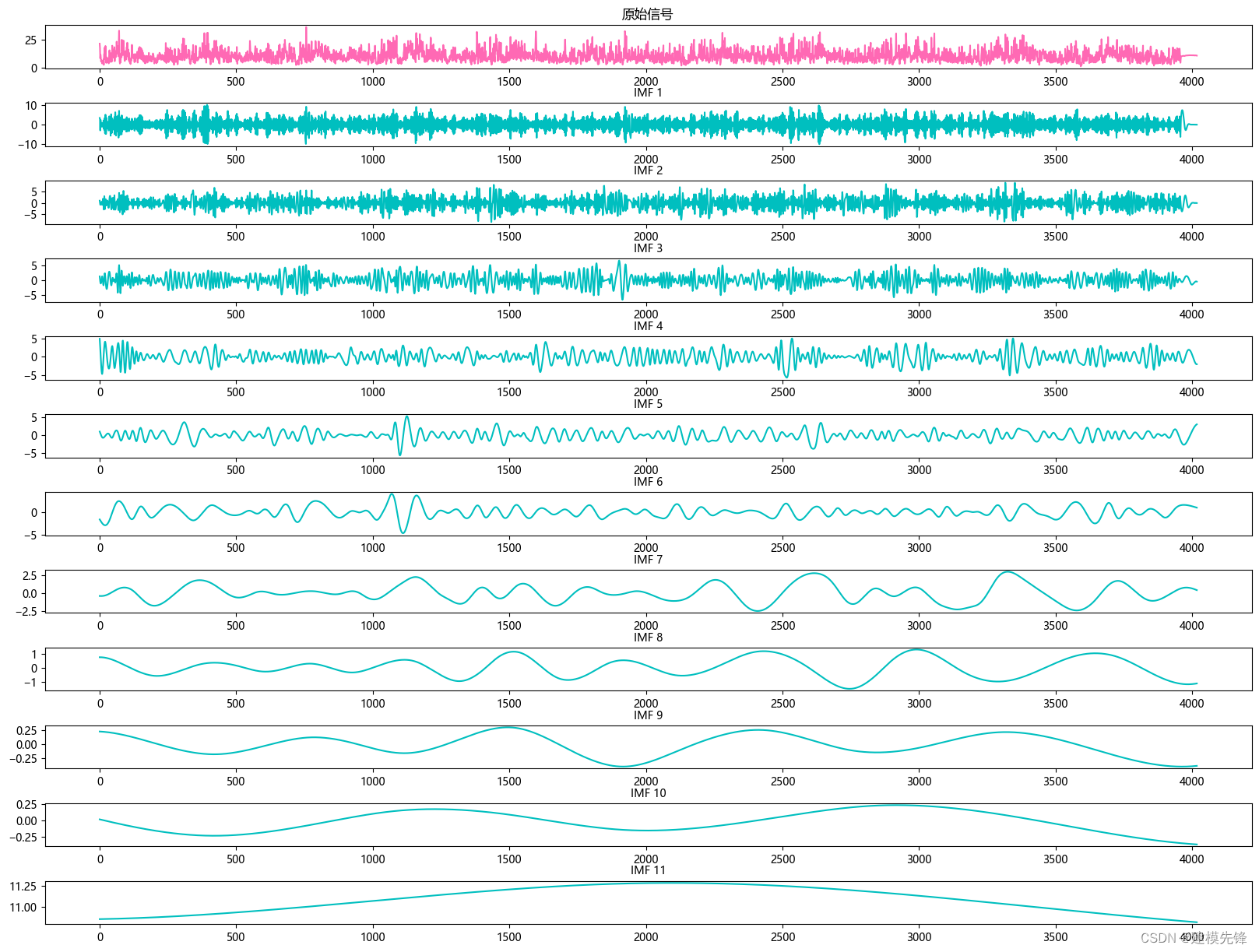 ?
?
根据分解结果看,CEEMDAN一共分解出11个分量,我们大致把前7个高频分量作为Transformer - BiLSTM模型的输入进行预测,后4个低频分量作为ARIMA模型的输入进行预测
2 数据集制作与预处理
划分数据集,按照8:2划分训练集和测试集, 然后再按照前7后4划分分量数据
在处理LSTF问题时,选择合适的窗口大小(window size)是非常关键的。选择合适的窗口大小可以帮助模型更好地捕捉时间序列中的模式和特征,为了提取序列中更长的依赖建模,本文把窗口大小提升到24,运用CCEMDAN-Transformer - BiLSTM模型来充分提取前7个分量序列中的特征信息。
 ?
?
分批保存数据,用于不同模型的预测
3 基于CEEMADN的 Transformer - BiLSTM 模型预测
3.1 定义CEEMDAN-Transformer - BiLSTM预测模型
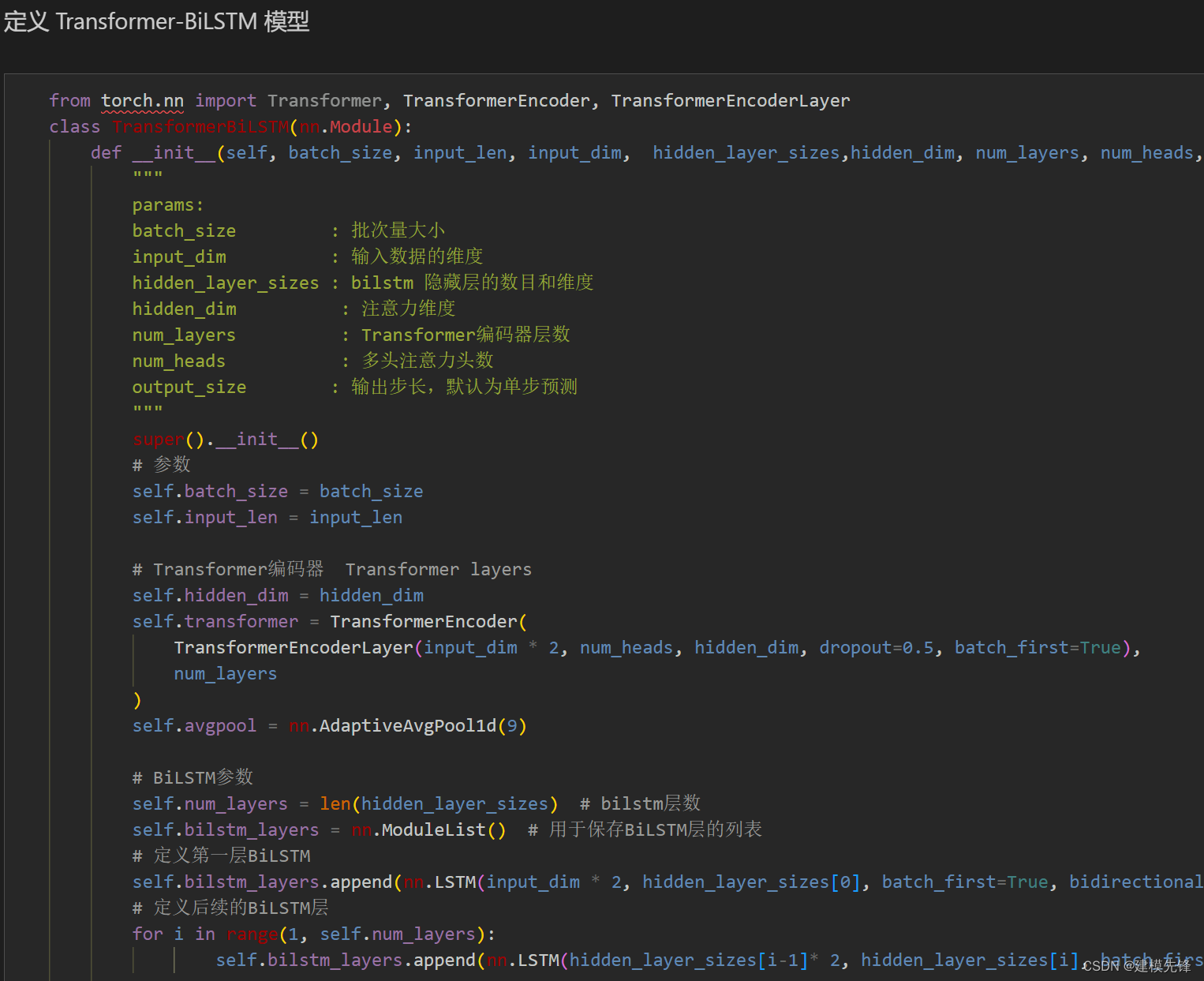 ?
?
注意:
-
输入维度为7,维度7维代表前7个分量
-
输入形状为 torch.Size([64, 7, 48])
-
在PyTorch中,transformer模型的性能与batch_first参数的设置相关,当batch_first为True时,输入的形状应为(batch, sequence, feature),这种设置在某些情况下可以提高推理性能。
在使用Transformer模型中的多头注意力时,输入维度必须能够被num_heads(注意力头的数量)整除。因为在多头注意力机制中,输入的嵌入向量会被分成多个头,每个头的维度是embed_dim / num_heads,因此embed_dim必须能够被num_heads整除,以确保能够均匀地分配给每个注意力头。
因为此时分解分量为7个,可以事先适当改变分量个数,或者对信号进行堆叠,使调整多头注意力头数能够与之对应整除的关系。本文采用对序列进行对半切分堆叠,使输入形状为[64, 14, 12]。
3.2 设置参数,训练模型
 ?
?
100个epoch,MSE 为0.00638,Transformer - BiLSTM预测效果良好,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
-
可以适当增加Transformer层数和隐藏层的维度,微调学习率;
-
调整BiLSTM层数和维度数,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
保存训练结果和预测数据,以便和后面ARIMA模型的结果相组合。
4 基于ARIMA的模型预测
传统时序模型(ARIMA等模型)教程如下:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较_arima、es、holt、holt-winters-CSDN博客
数据加载,训练数据、测试数据分组,四个分量,划分四个数据集
4.1 介绍一个分量预测过程(其他分量类似)
第一步,单位根检验和差分处理
第二步,模型识别,采用AIC指标进行参数选择
第三步,模型预测
 ?
?
第四步,模型评估
 ?
?
保存预测的数据,其他分量预测与上述过程一致,保留最后模型结果即可。
5 结果可视化和模型评估
组合预测,加载各模型的预测结果
5.1 结果可视化
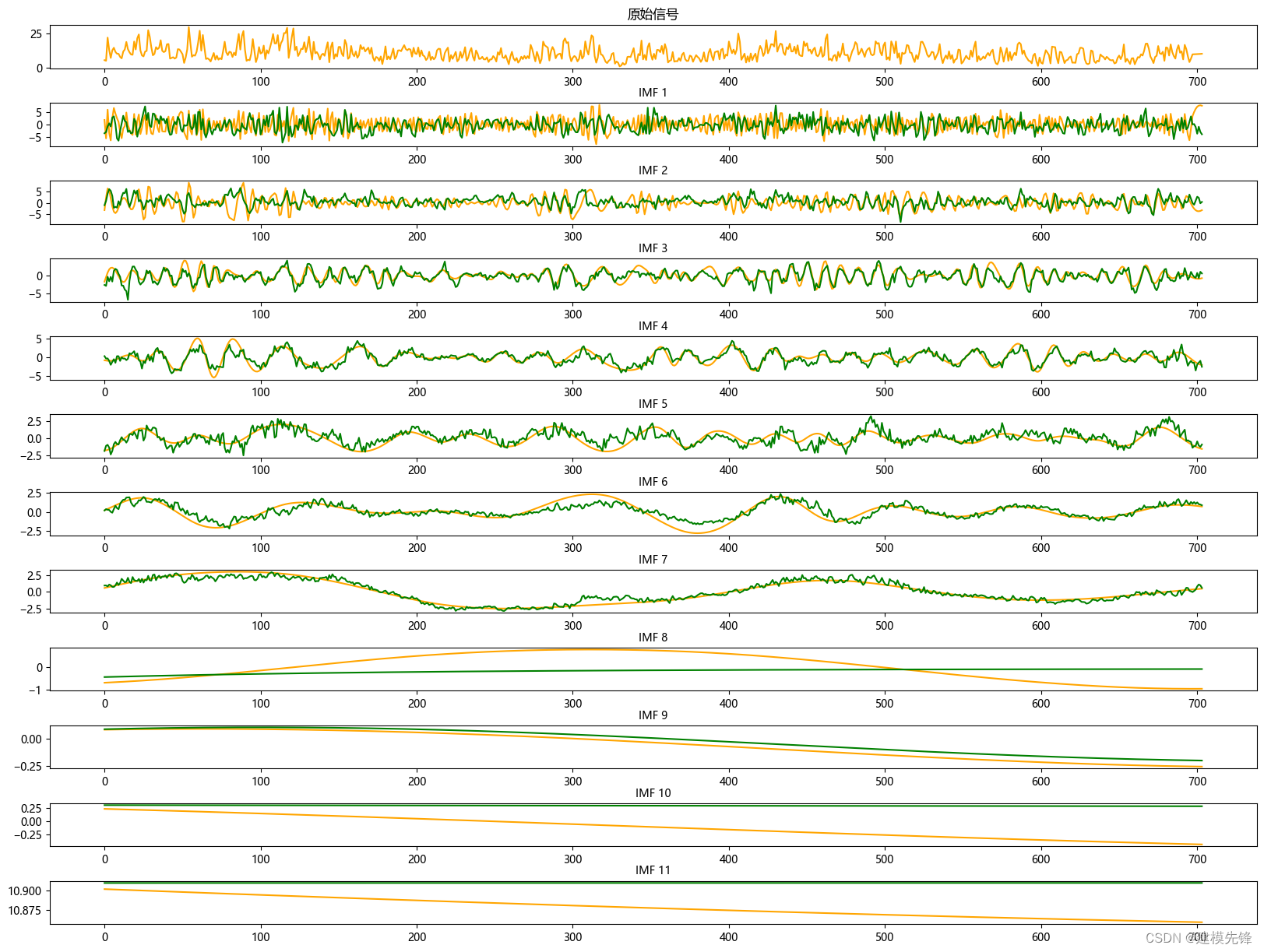 ?
?
 ?
?
5.2 模型评估
由分量预测结果可见,前7个分量在Transformer - BiLSTM预测模型下拟合效果良好,分量9在ARIMA模型的预测下,拟合程度比较好,其他低频分量拟合效果弱一点,调整参数可增强拟合效果。
 ?
?
代码、数据如下:
往期精彩内容:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 三、安全工程—物理安全(CISSP)
- CPU和GPU的工作原理及区别
- 基于美团发布的YOLOv6开发构建自己的个性化目标检测项目超详细教程
- 女儿的年服都准备好啦,好喜欢这件小旗袍
- SQL Server从0到1——提权
- 数据矩阵集成可提高印刷电路板识别的准确性
- JavaScript基础部分(二)
- 行为型设计模式—状态模式
- 【Springboot】日志
- 解决vscode中导入的vue项目tsconfig.json文件首行标红问题