【目标检测从零开始】torch实现yolov3数据加载
发布时间:2023年12月18日
数据简介
-
林业病虫害防治项目用到的AI识虫数据集,该数据集提供了2183张图片,其中训练集1693张,验证集245,测试集245张。下载地址
-
图片和标签示例如下:

# 根据坐标把框画到图上
import xml.etree.ElementTree as ET
import cv2
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
import os
def read_xml(xml_path):
tree = ET.parse(xml_path)
root = tree.getroot()
boxes = []
for obj in root.findall('object'):
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
# Read class label
class_label = obj.find('name').text
boxes.append((xmin, ymin, xmax, ymax, class_label))
return boxes
def visualize_boxes(image_path, boxes):
# Read the image using OpenCV
image = cv2.imread(image_path)
# Convert BGR image to RGB
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Create figure and axes
fig, ax = plt.subplots(1)
# Display the image
ax.imshow(image_rgb)
# Add bounding boxes to the image
for box in boxes:
xmin, ymin, xmax, ymax, class_label = box
rect = patches.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin, linewidth=1, edgecolor='g', facecolor='none')
ax.add_patch(rect)
# Display class label
plt.text(xmin, ymin, class_label, color='r', fontsize=8, bbox=dict(facecolor='white', alpha=0.7))
# Set the title as the file name
plt.title(os.path.splitext(os.path.basename(image_path))[0])
# Show the plot
plt.show()
if __name__ == "__main__":
xml_folder = r"D:\work\data\insects\train\annotations\xmls"
image_folder = r"D:\work\data\insects\train\images"
# Specify the file name of the image you want to visualize
image_file_name = "1.jpeg"
xml_file = os.path.join(xml_folder, os.path.splitext(image_file_name)[0] + ".xml")
image_path = os.path.join(image_folder, image_file_name)
boxes = read_xml(xml_file)
visualize_boxes(image_path, boxes)
Dataset读取
继承torch.utils.Dataset类来读取数据集,在getitem函数中返回图片、框坐标、框类别,主要分为以下步骤:
Step1:类别定义
-
定义数据集的路径、类别
DATA_ROOT = r'D:\work\data\insects' CATEGORY_NAMES = ['Boerner', 'Leconte', 'Linnaeus', 'acuminatus', 'armandi', 'coleoptera', 'linnaeus'] # 根据类名返回对应的id def get_insect_names(): insect_category2id = {} for i, item in enumerate(CATEGORY_NAMES): insect_category2id[item] = i return insect_category2id CATEGORY_NAME_ID = get_insect_names() NUM_CLASSES = len(CATEGORY_NAMES)
Step2:解析xml
-
解析xml文件,获取框的位置、类别
-
框坐标从xyxy改成了xywh
import xml.etree.ElementTree as ET import os import numpy as np def read_xml(xml_path): """ 解析xml文件,返回坐标和类别信息 :param xml_path: :return: """ tree = ET.parse(xml_path) root = tree.getroot() fname = os.path.basename(xml_path).split()[0] objs = tree.findall('object') # 存框坐标和类别 gt_bbox = np.zeros((len(objs), 4), dtype=np.float32) gt_class = np.zeros((len(objs),), dtype=np.int32) difficult = np.zeros((len(objs),), dtype=np.int32) for i, obj in enumerate(root.findall('object')): bbox = obj.find('bndbox') xmin = int(bbox.find('xmin').text) ymin = int(bbox.find('ymin').text) xmax = int(bbox.find('xmax').text) ymax = int(bbox.find('ymax').text) _difficult = int(obj.find('difficult').text) cname = obj.find('name').text # 直接改成 xywh格式 gt_bbox[i] = [(xmin + xmax) / 2.0, (ymin + ymax) / 2.0, ymax - ymin + 1., ymax - ymin + 1.] gt_class[i] = CATEGORY_NAME_ID[cname] difficult[i] = _difficult record = { 'fname': fname, 'gt_bbox': gt_bbox, 'gt_class': gt_class, 'difficult': difficult } return record
Step3:实现Dataset
-
继承torch.nn.Dataset,定义InsectDataset类,包含 init/getitem/len和get_annotations四个方法
- init():定义数据集路径、数据增强等参数
- **len():**数据集数量
- get_annotations():将Step2中解析出来的xml结果包裹起来,获取所有框
- get_item():读取records,根据idx拿到对应图片的框(同时将框改成相对坐标)
returns: image, gt_boxes, labels
import os
import numpy as np
import torch
from PIL import Image
from torch.utils.data import Dataset, DataLoader
class InsectDataset(Dataset):
"""
:returns img, gt_boxes, labels
img: tensor
gt_boxes: list 框的相对位置
labels: list 框的标签
"""
def __init__(self, datadir, mode='train', transforms=None):
super(InsectDataset, self).__init__()
self.datadir = os.path.join(datadir, mode)
self.records = self.get_annotations()
self.transforms = transforms
def __getitem__(self, idx):
record = self.records[idx]
gt_boxes = record['gt_bbox']
labels = record['gt_class']
image = np.array(Image.open(record['im_file']))
w = image.shape[0]
h = image.shape[1]
# gt_bbox 用相对值
gt_boxes[:, 0] = gt_boxes[:, 0] / float(w)
gt_boxes[:, 1] = gt_boxes[:, 1] / float(h)
gt_boxes[:, 2] = gt_boxes[:, 2] / float(w)
gt_boxes[:, 3] = gt_boxes[:, 3] / float(h)
if self.transforms:
transformed = self.transforms(image=image, bboxes=gt_boxes, class_labels=labels)
image = transformed['image']
gt_boxes = np.array(transformed['bboxes'])
labels = np.array(transformed['class_labels'])
image = image.transpose((2,1,0)) # h,w,c -> c,w,h
return image, gt_boxes, labels
def __len__(self):
return len(self.records)
def get_annotations(self):
"""
从xml目录下面读取所有文件的标注信息
:param cname2cid:
:param datadir:
:return: record:[{im_file: array
gt_boxes: array
gt_classes: array
difficult: array}]
"""
datadir = self.datadir
filenames = os.listdir(os.path.join(datadir, 'annotations', 'xmls'))
records = []
for fname in filenames:
# 拿到文件名
fid = fname.split('.')[0]
fpath = os.path.join(datadir, 'annotations', 'xmls', fname)
img_file = os.path.join(datadir, 'images', fid + '.jpeg')
# 解析xml文件
record = read_xml(fpath)
record['im_file'] = img_file # 把图片路径加上
records.append(record)
return records
Step4:数据增强
-
这里采用albumentations进行数据增强,参考官网的目标检测数据增强教程即可,这里加入normalize、resize以及一些常见的数据增强策略,后续完善
import albumentations as A transforms = A.Compose([ # A.RandomCrop(width=450, height=450), A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0), A.Resize(width=640, height=640), A.HorizontalFlip(p=0.5), A.RandomBrightnessContrast(p=0.2), ], bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels'])) -
在调用的时候注意框坐标的format,这里统一用yolo格式(xywh相对坐标)
if self.transforms: transformed = self.transforms(image=image, bboxes=gt_boxes, class_labels=labels) image = transformed['image'] gt_boxes = np.array(transformed['bboxes']) labels = np.array(transformed['class_labels'])

Step5:添加dataset_collate
由于不同图片的框数量不同,在用dataloader加载数据的时候,getitem的返回值shape不同会报错,因此用一个list包裹起来
def dataset_collate(batch):
"""
用list包一下 img, bboxes, labels
:param batch:
:return:
"""
images = []
bboxes = []
labels = []
for img, box, label in batch:
images.append(img)
bboxes.append(box)
labels.append(label)
images = torch.tensor(np.array(images))
return images, bboxes, labels
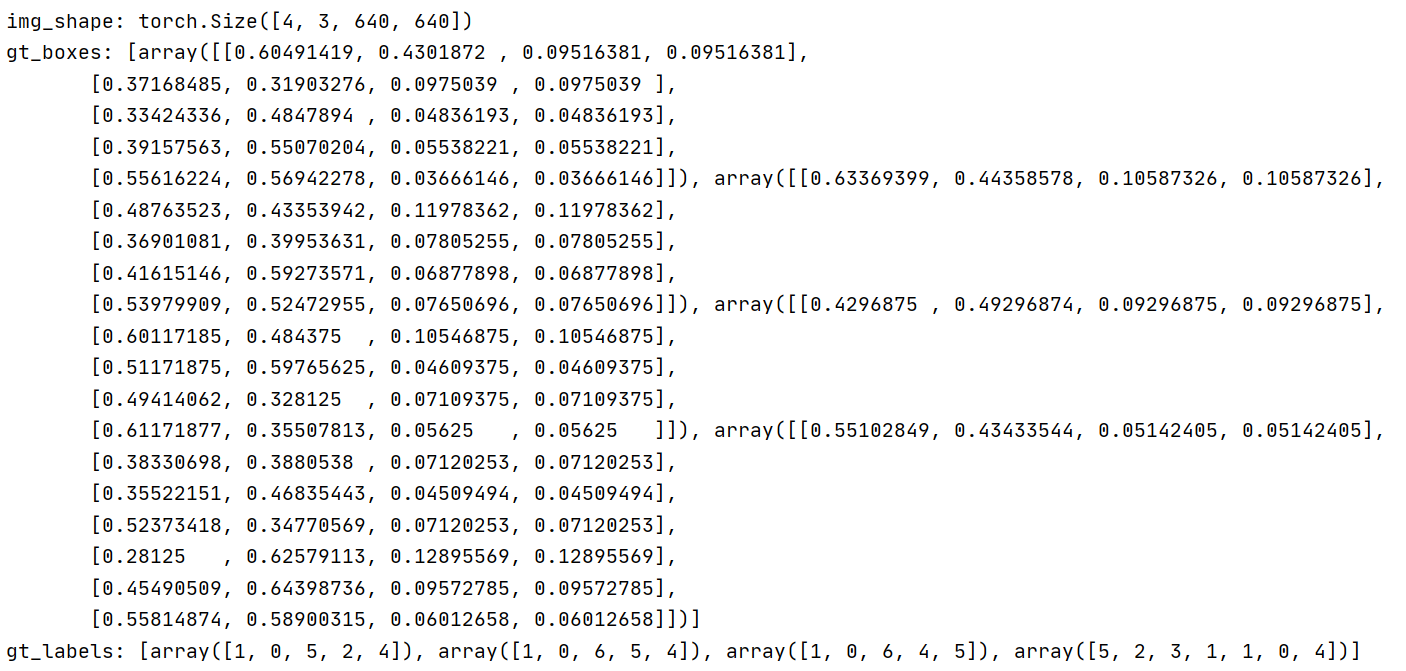
Step6:测试
- 测试Dataset的getitem函数以及用Dataloader加载后能否正常读取
if __name__ == '__main__':
dataset = InsectDataset(DATA_ROOT, transforms=transforms)
print(dataset.__len__())
print('image_shape: ', dataset.__getitem__(1)[0].shape)
batch_size = 4
print()
train_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=0,collate_fn=dataset_collate)
for inputs in train_loader:
print('img_shape:', inputs[0].shape)
print('gt_boxes:', inputs[1])
print('gt_labels:', inputs[2])
小结
-
读取voc格式的数据集主要以下三个点需要注意一下
- 解析xml文件,获取关键的框坐标和类别信息,并非所有信息都有作用
- 弄清楚数据集格式是xyxy还是xywh,是相对坐标还是绝对坐标(既然要做数据增强变换图像大小,那相对坐标更方便)
- 用Dataloader读取的时候每个图片的框数量不一样,加上dataset_collate用list包裹一下。
-
把画框的代码单独放在一个文件里,但其中read_xml的方法跟dataset中类似,框架搭好之后进一步优化一下
-
如果是anchor base的模型后续还需要根据锚框来处理得到每个锚框的objectness和坐标
文章来源:https://blog.csdn.net/qq_43542339/article/details/134906816
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机网络 第四章(网络层)【下】
- 通信入门系列——连续系统、离散系统、线性系统、时/移不变系统
- 企业培训系统源码:构建智能、可扩展的学习平台
- Mybatis事务如何跟Spring结合到一起?
- 计算机网络实验二:Packet Tracer的简单使用
- golang常见算法题
- 腾讯首席技术架构教你从C语言过渡到C++,真的很实用!
- 单位转换工具类
- 从酱香拿铁的落寞中,创业者不得不汲取的教训!2024普通人失业怎么创业,普通人逆袭的机会
- ???恒峰|配网行波型故障预警定位装置:电力系统的守护神