大模型日报-20240112
重磅!OpenAI正式发布,自定义ChatGPT商店!
https://mp.weixin.qq.com/s/Ic9XVFbwcR35Tcr25w28oA
OpenAI发布自定义GPT商店,开启商业模式,推出32K上下文的ChatGPT Team版本,助力学术研究、编程分析等,用户超300万。企业可享加强版服务,新产品已广泛使用。
利用可解释AI,发现可扩展钙钛矿太阳能电池制造的工艺动力学

https://mp.weixin.qq.com/s/AUN4KciLKqR8zXuLWgi2rw
钙钛矿半导体薄膜的大面积加工非常复杂,并且会引起无法解释的质量差异,成为钙钛矿光伏发电商业化的主要障碍。可扩展制造工艺的进步目前仅限于渐进和任意的试错过程。虽然光致发光视频的原位采集有可能揭示薄膜形成过程中的重要变化,但数据的高维性很快就超出了人类分析的极限。德国癌症研究中心(German Cancer Research Center)交互式机器学习小组(Interactive Machine Learning Group)、亥姆霍兹成像小组(Helmholtz Imaging)以及德国卡尔斯鲁厄理工学院照明技术研究所(Light Technology Institute, Karlsruhe Institute of Technology)的研究人员组成跨学科研究团队,利用深度学习和可解释的人工智能(XAI)来发现钙钛矿薄膜形成过程中获取的传感器信息与由此产生的太阳能电池性能指标之间的关系,同时使这些关系变得易于理解。研究人员进一步展示了如何将获得的见解提炼成钙钛矿薄膜加工的可行建议,从而推进工业规模的太阳能电池制造。
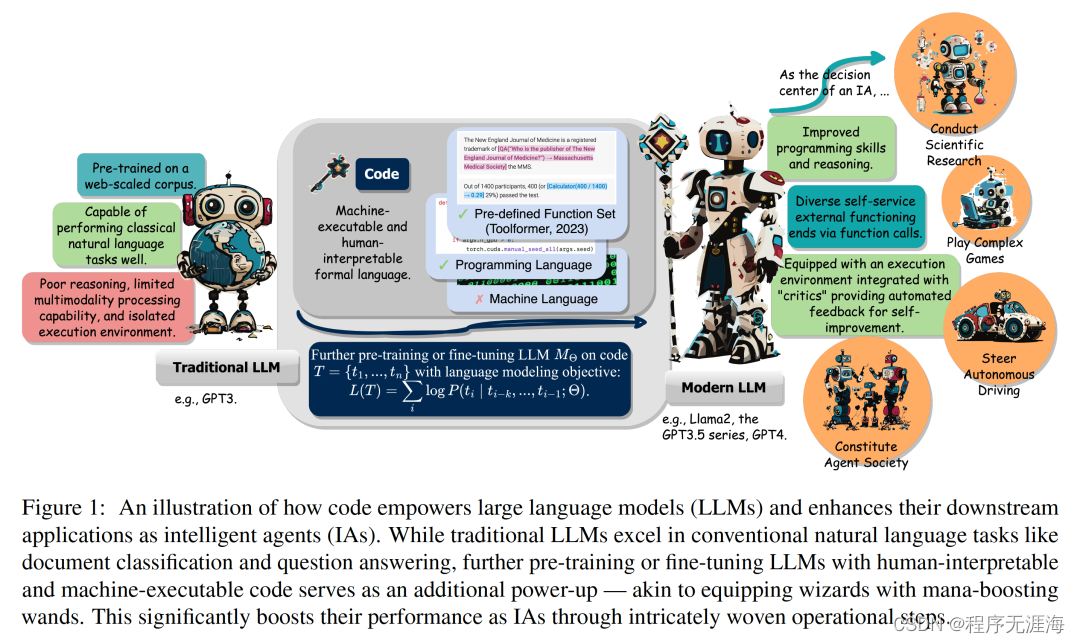
挥舞起代码语料的魔杖,大模型和智能体将召唤出更强大的能量
https://mp.weixin.qq.com/s/iJzkQ0GNtei5oYLIx2HN1w
正如瑞斯福兹魔杖缔造了诸如邓布利多在内的历代非凡魔法师的传奇,具有巨大潜能的传统大型语言模型,在经过代码语料的预训练 / 精调后,掌握了更超出本源的执行力。具体来说,进阶版的大模型在编写代码、更强推理、自主援引执行接口、自主完善等方面都获得了提升,这将为它作为 AI 智能体、执行下游任务时方方面面带来增益。近日,伊利诺伊大学厄巴纳 - 香槟分校(UIUC)的研究团队发布了一项重要综述。这篇综述探讨了代码(Code)如何赋予大型语言模型(LLMs)及其基于此的智能体(Intelligent Agents)强大的能力。
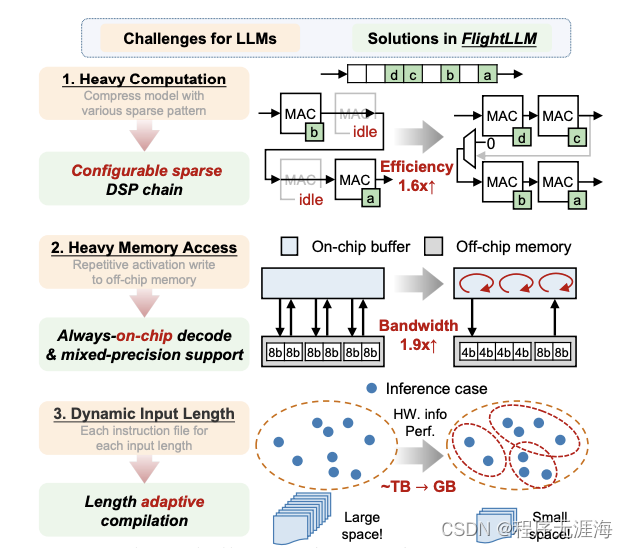
比A100性价比更高!FlightLLM让大模型推理不再为性能和成本同时发愁
https://mp.weixin.qq.com/s/JHGKeHvSWXU9_AaBF7zilg
大语言模型在端侧的规模化应用对计算性能、能效比需求的“提拽式”牵引,在算法与芯片之间,撕开了一道充分的推理竞争场。面对想象中的终端场景,基于 GPU 和 FPGA 的推理方案的应用潜力需要被重新审视。近日,无问芯穹、清华大学和上海交通大学联合提出了一种面向 FPGA 的大模型轻量化部署流程,首次在单块 Xilinx U280 FPGA 上实现了 LLaMA2-7B 的高效推理。第一作者为清华大学电子系博士及无问芯穹硬件负责人曾书霖,通讯作者为上海交通大学副教授、无问芯穹联合创始人兼首席科学家戴国浩,清华大学电子工程系教授、系主任及无问芯穹发起人汪玉。相关工作现已被可重构计算领域顶级会议 FPGA’24 接收。
荣耀发布自研 70 亿参数端侧平台级 AI 大模型“魔法大模型”

https://www.ithome.com/0/744/405.htm
在今天的发布会上,赵明揭晓了荣耀自研端侧 70 亿参数平台级 AI 大模型“魔法大模型”,将由明天发布的荣耀 Magic 6 手机首发。
贾扬清创业新动作:推出AIGC提示工具,几个字提示玩转SDXL,细节拉满
https://mp.weixin.qq.com/s/zywLGeUKiECWavWQmPQgUw
贾扬清团队LeptonAI最新推出的AIGC提示工具——PromptLLM。只需短短几个字提示,就能收获一张细节感满满的绘图。值得一提的是,此次工具的发布是贾扬清LeptonAI同HippoML合作。
英特尔推出车载AI芯片,挑战英伟达和高通

https://www.zhitongcaijing.com/content/detail/1052882.html
英特尔周二表示,将推出其最新的人工智能芯片的汽车版本,在为未来的半导体市场上与高通和英伟达展开竞争。英特尔还表示,将收购法国初创公司Silicon Mobility,该公司设计用于控制电动汽车电机和车载充电系统的片上系统技术和软件。Silicon Mobility由风险基金Cipio Partners和Capital-E控制,英特尔没有透露具体的收购价格。
Cognosys2.0: 能够自主创建工作流程、利用工具并从单一提示执行任务的助手
https://x.com/SullyOmarr/status/1744769308465741984?s=20
激动地分享Cognosys 2.0!这是一个能够自主创建工作流程、利用工具并从单一提示执行任务的助手。
Meta发布Audiobox:新的基础音频生成研究模型,可以使用声音输入和自然语言文本提示的组合来生成音频
https://x.com/AIatMeta/status/1744796547072786447?s=20
您现在可以尝试Audiobox,我们新的基础音频生成研究模型,它可以使用声音输入和自然语言文本提示的组合来生成音频。
尝试演示 ?? https://bit.ly/3RVh6im
MagicVideo-V2: 多阶段高美感视频生成

链接:http://arxiv.org/abs/2401.04468v1
随着对由文本描述生成高度逼真视频的需求不断增长,这个领域的研究得到了重要的推动。在这项工作中,我们引入了MagicVideo-V2,它将文本到图像模型、视频动作生成器、参考图像嵌入模块和帧插值模块集成到一个端到端的视频生成流水线中。受益于这些架构设计,MagicVideo-V2能够生成外观美观、高分辨率、具有显著真实感和流畅性的视频。通过大规模用户评估,它展示了优于领先的文本到视频系统,如Runway、Pika 1.0、Morph、Moon Valley和Stable Video Diffusion模型的性能。
LightningAttention-2: 在大型语言模型中处理无限序列长度

链接:http://arxiv.org/abs/2401.04658v1
本文提出了Lightning Attention-2,这是第一个能够使线性注意力实现其理论计算优势的线性注意力实现方法。为了实现这一目标,我们利用了平铺思想,分别处理线性注意力计算中的块内部和块间组成部分。具体而言,我们利用常规的注意力计算机制来处理块内部,并对块间应用线性注意力内核技巧。通过前向和后向过程都采用平铺技术,充分利用GPU硬件的优势。我们在Triton中实现了这个算法,使其适应IO并友好地针对硬件优化。我们在不同的模型大小和序列长度上进行了各种实验。无论输入序列长度如何,Lightning Attention-2都保持了一致的训练和推断速度,并且比其他注意机制快得多。源代码可在https://github.com/OpenNLPLab/lightning-attention获得。
DebugBench:评估大语言模型的调试能力

链接:http://arxiv.org/abs/2401.04621v1
大语言模型(LLMs)展示了出色的编码能力。然而,作为编程能力的另一个关键组成部分,LLMs的调试能力仍然相对未被探索。之前评估LLMs调试能力的研究受到了数据泄漏风险、数据集规模和测试错误类型的限制。为了克服这些问题,我们引入了一个名为DebugBench的LLM调试基准,其中包含4,253个实例。它涵盖了C ++、Java和Python中的四个主要错误类别和18个较小类型。为了构建DebugBench,我们从LeetCode社区收集代码片段,使用GPT-4在源数据中注入错误,并确保严格的质量检查。在零-shot场景下,我们评估了两个商业模型和三个开源模型。我们发现,(1)尽管像GPT-4这样的闭源模型的调试性能较人类差,但像Code Llama这样的开源模型无法达到任何通过率,(2)调试的复杂性明显取决于错误的类别,(3)引入运行时反馈对调试性能有明显影响,但并不总是有帮助。作为扩展,我们还比较了LLM的调试和代码生成,揭示了闭源模型之间它们之间的强相关性。这些发现将有助于LLMs在调试方面的发展。
用于长程视频问答的简单大语言模型框架
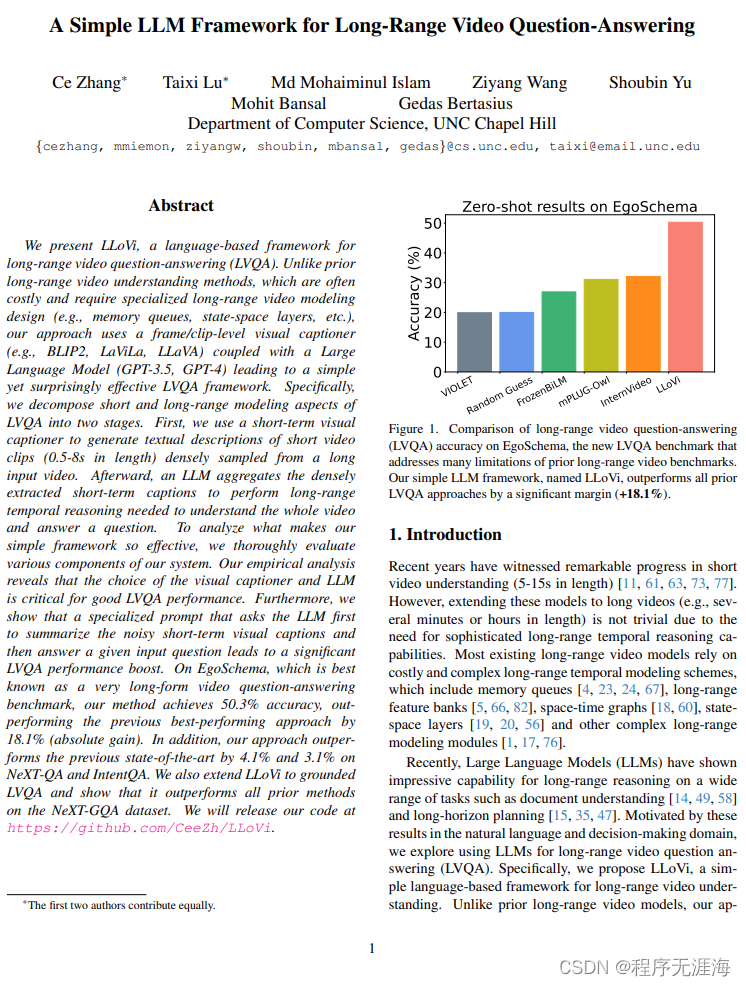
链接:http://arxiv.org/abs/2312.17235v1
我们提出了LLoVi,一种基于语言的长距离视频问答(LVQA)框架。与以往的长距离视频理解方法不同,我们的方法使用基于帧/剪辑级别的视觉字幕生成器(如BLIP2,LaViLa,LLaVA)与大型语言模型(GPT-3.5,GPT-4)相结合,从而形成一个简单但令人惊讶地有效的LVQA框架。具体而言,我们将LVQA的短期和长期建模方面分解为两个阶段。首先,我们使用短期视觉字幕生成器为从长视频中密集采样的短视频片段(长度为0.5-8秒)生成文本描述。之后,一个大型语言模型聚合密集提取的短期字幕,进行长距离时间推理,以理解整个视频并回答问题。我们将在https://github.com/CeeZh/LLoVi发布我们的代码。
Sama AI
https://www.aisama.co/?ref=producthunt
遇见Sama AI:你的应用程序优先的AI可穿戴设备,用于增强内存,随时可以与你的手机一起使用。Sama倾听,提供反馈,并帮助回忆对话。以隐私为中心的安全、基于同意的交互
Feather AI
https://en.feather-ai.io/?ref=producthunt
让你的AI自动化的交流
如何通俗理解扩散模型
https://zhuanlan.zhihu.com/p/563543020?utm_psn=1728447014252314625
这篇文章旨在通俗地解释扩散模型(Diffusion Model)的概念。文章首先介绍了变分自编码器(VAE)的基本原理,即通过隐变量生成目标数据,并将隐变量假设为正态分布。VAE的核心在于通过学习均值和方差来逼近目标分布。然后,文章转向扩散模型,指出它是一种VAE的升级版,通过定义一个从数据样本到高斯分布的映射(前向过程),并学习一个生成器来模仿这个映射(反向过程)。扩散模型利用马尔可夫链的平稳性,通过逐步加入噪声来逼近高斯分布,从而实现对数据分布的学习。文章强调,扩散模型不依赖于可微梯度,而是数学层面上的创新,它借鉴了神经网络的前向传播/反向传播概念。最后,文章指出扩散模型在计算速度上的优势,因为它基于简单的高斯分布。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!