数仓分层结构
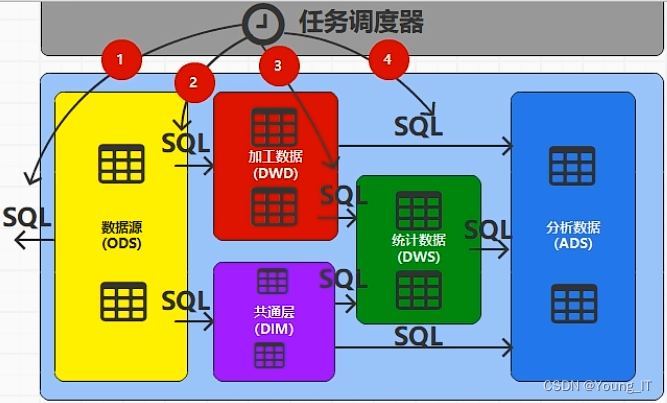
?--图片来源尚硅谷
ODS层:
数据存储格式:JSON/TSV+ gzip压缩(默认)
Operate Data Store
-- 存储从mysql业务数据库和日志服务器的日志文件中采集到的数据
????????-- 日志数据
????????????????-- 格式:JSON
????????--业务数据
????????????????--历史数据
????????-- 格式:
????????????????-- 全量
????????????????????????-- Datax : TSV
? ? ? ? ? ? ? ? -- 增量
????????????????????????-- Maxwell : JSON
-- 汇总数据
????????-- 希望用最少的资源存储最多的数据
????????????????-- 压缩:
????????????????????????-- gzip:Hadoop默认支持的,压缩率极高,压缩效率不高
????????????????????????-- Izo:Hadoop默认不支持的,压缩效率高,压缩率高
????????????????????????--snappy :Hadoop默认不支持的,压缩效率极高,压缩率不高
DIM层:(维度层)
数据存储格式:orc列式存储+snappy压缩
Dimension :维度
--所谓的维度其实就是分析数据的角度
--维度层保存的表其实就是分析数据的角度表
????????-- 性别
????????-- 年龄
????????-- 品牌
? ? ? ? -- 品类
--维度层保存维度表,所以建模理论应该遵循维度建模理论
????????-- 维度层中的维度表,主要用于统计分析
????????????????--数据存储方式应该为列式存储: orc
????????????????--数据压缩效率越高越好(时间短) : snappy
????????--数据源
????????????????-- ODS层的数据为整个数据仓库做准备
????????????????-- DIM层数据源就是ODS层
--命名规范
????????-- 分层标记 (dim_)_维度名称_全量/拉链(标记)
????????????????-- 全量: 维度表的全部数据
????????????????????????-- 状态数据为了避免数据出现问题,最好的方式,就是每一天都保存数据
--建模理论
????????--ER模型
????????????????-- ODS
? ? ? ? --维度模型
????????????????-- 维度(状态)表
????????????????--事实(行为) 表
DWD层:(明细层)
数据存储格式:orc列式存储+snappy压缩
Data Warehouse Detail
-- detail : 详细,明细
- 对ODS层的数据进行加工,为后续的统计分析做准备
- DIM层主要功能其实是分析数据:面向状态
- DWD层主要功能其实是统计数据: 面向行为
- DWD层的表中主要保存的就是业务行为数据,表的设计需要遵循建模理论 - 维度建模 - 事实(行为)
- 数据存储格式:列式存储
- 数据压缩格式: snappy
命名规范
--分层标记 (dwd_)+ 数据域(分类) + 行为 + 全量/增量
? ? ? ? --原则上来讲,所有的行为都应该是增量数据
? ? ? ? ? ? ? ? --特殊情况下,会采用全量方式实现行为统计。
DWS层:(汇总层)
数据存储格式:orc列式存储+snappy压缩
Data Warehouse Summary
-- Data Warehouse : 数仓库
-- Summary : 汇总 (预聚合)
--用于将DIM,DWD的数据进行提前统计,将统计结果保存到当前的表中。
-- 所以当前的表不是最终的统计结果表
????????--数据量就可能有点多。表的设计中应该添加分区
????????--当前表需要进一步的聚合处理,所以表的设计中应该是列式存储,且采用snappy压缩
--表的分类:根据数据范围进行分类
????????--1d:1天的数据的统计
????????????????数据来源为DIM,DWD
????????-- nd :N天的数据的统计
????????????????数据来源必须为1d表
????????--td : 所有数据的统计
????????????????数据来源可以为1d表
????????????????数据来源也可以为DIM,DWD
--表名
?????????--分层标记 (dws_)+ 数域 + 统计度 + 业务过程 + 统计周期 (1d/nd/td)
????????????????-- 指标: 客户想要的一个统计结果 (数值)
????????????????????????--业务过程相同:数据来源相同
????????????????????????--统计周期相同:数据范围相同
????????????????????????--统计粒度相同:数据含义相同
ADS层:
-- Application Data Service
????????-- Application : (数据仓库)应用
????????-- Data : 用户需求的统计结果数据
????????-- Service :对外服务
1. ADS层保存的数据是最终的统计结果,无需做进一步的计算
????????-- 不需要列式存储,也不需要snappy压缩
2. 统计结果的目的是对外提供服务,所以表不会最终数据的存储位置
????????-- 需要将表中的数据同步到第三方存储(MYSQL)
????????????????-- ADS层的表最好是行式存储: tsv (DataX)
????????????????--压缩格式采用gzip
3.?统计结果的数据量不会很多
????????-- ADS层的表无需分区设计
4. 表的设计
????????-- ODS层:表的结构依托于数据源的数据结构(ER模型)
????????-- DIM层:遵循维度模型的维度表的设计理念(维度越丰富越好)
????????-- DWD层:遵循维度模型的事实表的设计理念(粒度越细越好)
????????-- ADS层:客户要啥你加啥,不要额外添加
基础概念
????????维度: 分析数据的角度
????????粒度: 描述数据的详细程度
????????统计周期 : 统计的时候,数据统计时间范围
????????统计粒度 : 分析数据的具体角度,称之为统计粒度(站在哪一个角度统计数据)
????????指标: 客户想要的一个结果数值
指标体系:
-- 原子指标(拆分指标)
????????-- 行为,统计字段,统计逻辑
--派生指标(增加条件)
????????-- 统计周期(范围) + 业务限定(筛选条件) + 统计粒度(分组维度)
--衍生指标(比率,比例)
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《自己手动实现java虚拟机》第一章
- 003-10-02【Spark官网思维笔记】香积寺旁老松树边马大爷家女儿大红用GPT学习Spark入门知识
- 使用jquery.form.js插件通过ajax异步提交表单数据并上传文件
- 书生·浦语大模型实战1
- git如何导出提交记录及修改的文件清单?
- VMware虚拟机的安装配置
- STM32F407-14.3.10-03PWM模式_捕获比较互补通道输出波形-1x100
- 组合算法简单实现
- Android Studi安卓读写NDEF智能海报源码
- 拉普拉斯变换