第十七周周报
文章目录
摘要
本周看了三维人体重建的领域,看了一篇SMPL的文章:A Skinned Multi-Person Linear Model,提出的一种人体建模方法,该方法可以进行任意的人体建模和动画驱动。模型的参数从数据中学习,包括静止姿势模板、混合权重、姿势相关的混合变形、身份相关的混合变形以及从顶点到关节位置的回归。与以前的模型不同,姿势相关的混合变形是姿势旋转矩阵元素的线性函数。
This week, I explored the field of three-dimensional human body reconstruction and read an article on SMPL (Skinned Multi-Person Linear Model) titled “A Skinned Multi-Person Linear Model.” The article proposes a method for human body modeling that allows for arbitrary body modeling and animation driving. The model parameters are learned from data, including static pose templates, blend weights, pose-dependent blend shapes, identity-dependent blend shapes, and regression from vertices to joint positions. Unlike previous models, the pose-dependent blend shapes are linear functions of pose rotation matrix elements.
目标检测
边缘框与坐标轴有点区别:y轴有点区别
左上右下的点来定义
物体识别和目标识别的数据集通常比分类数据集小很多,因为标注的成本很高。
听李沐的课,有一节讲到,自动驾驶的,除了特斯拉是用的纯摄像头完成的
锚框
一类目标检测算法
提出多个被称为锚框的区域
预测每个锚框是否含有关注的物体
如果是,预测从这个锚框到真实边缘框的偏移
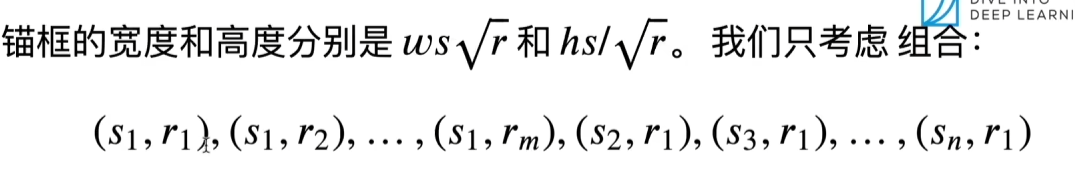 以同一像素为中心的锚框的数量是
n
+
m
?
1
n+m-1
n+m?1。
以同一像素为中心的锚框的数量是
n
+
m
?
1
n+m-1
n+m?1。
对于整个输入图像,将共生成
w
h
(
n
+
m
?
1
)
wh(n+m-1)
wh(n+m?1)个锚框。
交并比
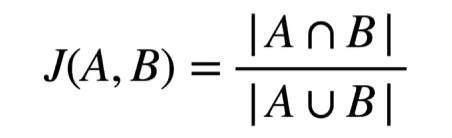

比较两个框之间的相似度
NMS 非极大值抑制输出
step1:先将所有的边界框按照类别进行区分;
step2:把每个类别中的边界框,按照置信度从高到低进行降序排列;
step3:选择某类别所有边界框中置信度最高的边界框bbox1,然后从该类别的所有边界框列表中将该置信度最高的边界框bbox1移除并同时添加到输出列表中;
step4:依次计算该bbox1和该类别边界框列表中剩余的bbox计算IOU;
step5:将IOU与NMS预设阈值Thre进行比较,若某bbox与bbox1的IOU大于Thre,即视为bbox1的“邻域”,则在该类别边界框列表中移除该bbox,即去除冗余边界框;
step6:重复step3~step5,直至该类别的所有边界框列表为空,此时即为完成了一个物体类别的遍历;
step7:重复step2~step6,依次完成所有物体类别的NMS后处理过程;
step8:输出列表即为想要输出的检测框,NMS流程结束。
文献阅读:SMPL: A Skinned Multi-Person Linear Model
SMPL模型是一种参数化人体模型,是马普所提出的一种人体建模方法,该方法可以进行任意的人体建模和动画驱动。这种方法与传统的LBS的最大的不同在于其提出的人体姿态影像体表形貌的方法,这种方法可以模拟人的肌肉在肢体运动过程中的凸起和凹陷。因此可以避免人体在运动过程中的表面失真,可以精准的刻画人的肌肉拉伸以及收缩运动的形貌。
作者提出了一种学习人体形状和位置依赖的形状变化模型,模型的参数从数据中学习,包括静止姿势模板、混合权重、姿势相关的混合变形、身份相关的混合变形以及从顶点到关节位置的回归。与以前的模型不同,姿势相关的混合变形是姿势旋转矩阵元素的线性函数。这个简单的公式能够从相对大量的不同姿势的不同人的对齐3D网格中训练整个模型。
Introduction
1)目标是自动学习一个既逼真又与现有图形软件兼容的人体模型。为此,作者描述了一个“皮肤多人线性”(SMPL)人体模型,它可以真实地表示各种人体形状,可以设置姿势相关的自然变形,展示软组织动力学,高效的动画,并与现有的渲染引擎兼容。
2)PCA(主成分分析)法学习男性和女性体型的线性模型。方法分为两步:
对于每一个扫描和姿态注册一个模板mesh
使用PCA,得到的主成分就是身体混合形状(body shape blend shapes)
3)基于顶点的蒙皮模型(如SMPL)实际上比基于变形的模型(如BlendSCAPE)在相同数据上训练的精度更高。
Related Work

Blend Skinning(混合蒙皮)
骨架子空间变形方法,也称为混合蒙皮,将网格的曲面附加到底层骨架结构。网格曲面中的每个顶点都使用其相邻骨骼的加权影响进行变换。该影响可以像在线性混合蒙皮(LBS)中那样线性定义。LBS的问题已经被广泛发表,文献中有很多试图解决这些问题的通用方法,例如四元数或双四元数蒙皮、球形蒙皮等。
Blend shapes (混合变形)
作者采取了一种更类似于加权姿势空间变形(WPSD)的方法,它定义静止姿势中的校正,然后应用标准蒙皮方程(例如LBS)。其思想是为特定关键姿势定义校正形状(雕刻),以便在添加到基础形状并通过混合蒙皮变换时,生成正确的形状。
Learning pose and shape models(学习姿势和形状模型。)
作者想要的是一个基于顶点的模型,它具有三角形变形模型的表现力,这样它就可以捕捉到一系列自然的形状和姿势。
形状参数(β \betaβ)
一组形状参数有着10个维度的数值去描述一个人的形状,每一个维度的值都可以解释为人体形状的某个指标,比如高矮,胖瘦等
姿态参数(θ \thetaθ)
一组姿态参数有着24 × 3 24\times324×3维度的数字,去描述某个时刻人体的动作姿态,其中的24 2424表示的是24 2424个定义好的人体关节点,其中的3 33并不是如同识别问题里面定义的( x , y , z ) (x,y,z)(x,y,z)空间位置坐标(location),而是指的是该节点针对于其父节点的旋转角度的轴角式表达(axis-angle representation)(对于这24 2424个节点,作者定义了一组关节点树)
Model Formulation

(1)模板网格,其混合权重由颜色指示,关节显示为白色。
(2)仅具有身份驱动的混合形状贡献;顶点和关节位置在形状向 β中是线性的。
(3) 在准备分割姿势时添加了姿势混合变形;请注意臀部的扩展。
(4)由分割姿势的双四元数蒙皮放置的变形顶点。
Training
一个3D人体mesh由6890个网格顶点和23个关节点组成:
N = 6890 N=6890N=6890,3D人体mesh的网格顶点总数。
K = 23 K=23K=23,3D人体mesh的关节点总数。
同时,作者指出,SMPL将3D人体mesh的状态分为shape和pose:
shape影响人体mesh的形状(高矮胖瘦)
pose影响人体mesh的姿态(动作姿势)
因为是在三维空间,一个点有三个坐标(x , y , z),一个标准3D人体mesh的6890个mesh顶点可表示为:
T
T
T,一个 6890 × 3 6890\times36890×3 的矩阵。注意,这个矩阵是常数值(对于单独一种性别的mesh来说)
同理,一个标准3D人体mesh的23个关节点可表示为:
J
J
J,一个 24 × 3 24\times324×3 的矩阵,23个关节点+1个root orientation。注意,这个矩阵是常数值(对于单独一种性别的mesh来说)
另外,还有blend weight,也就是每一个关节点的坐标变化对每一个mesh顶点坐标变化的影响:
W
W
W,一个6890 × 24 6890\times246890×24的矩阵。注意,这个矩阵的值需要训练得到
接下来,文章作者定义了影响shape和 pose的两组参数:
shape,影响高矮胖瘦:β,10个参数,值在-1到1之间
pose,影响动作姿势:θ,72个参数,后69个值在-1到1之间,3*23 + 3,影响23个关节点+1个root orientation的旋转。前三个控制root orientation,后面每连续三个控制一个关节点
这10+72个参数,便是以一个标准3D人体mesh为基础,生成不同shape、不同pose的3D人体mesh所需要的参数。

如上图,(a)是一个标准3D人体mesh,也就是由 T、J 生成,而颜色代表 W
(b),是改变了shape后的3D人体mesh,也就是由T、J ,外加β \betaβ的影响生成
?,是改变了shape和pose后的3D人体mesh,也就是由T、J,外加 β 、θ 的影响生成
(d),是在C的基础上,加入了 W 的影响后的结果。
评估
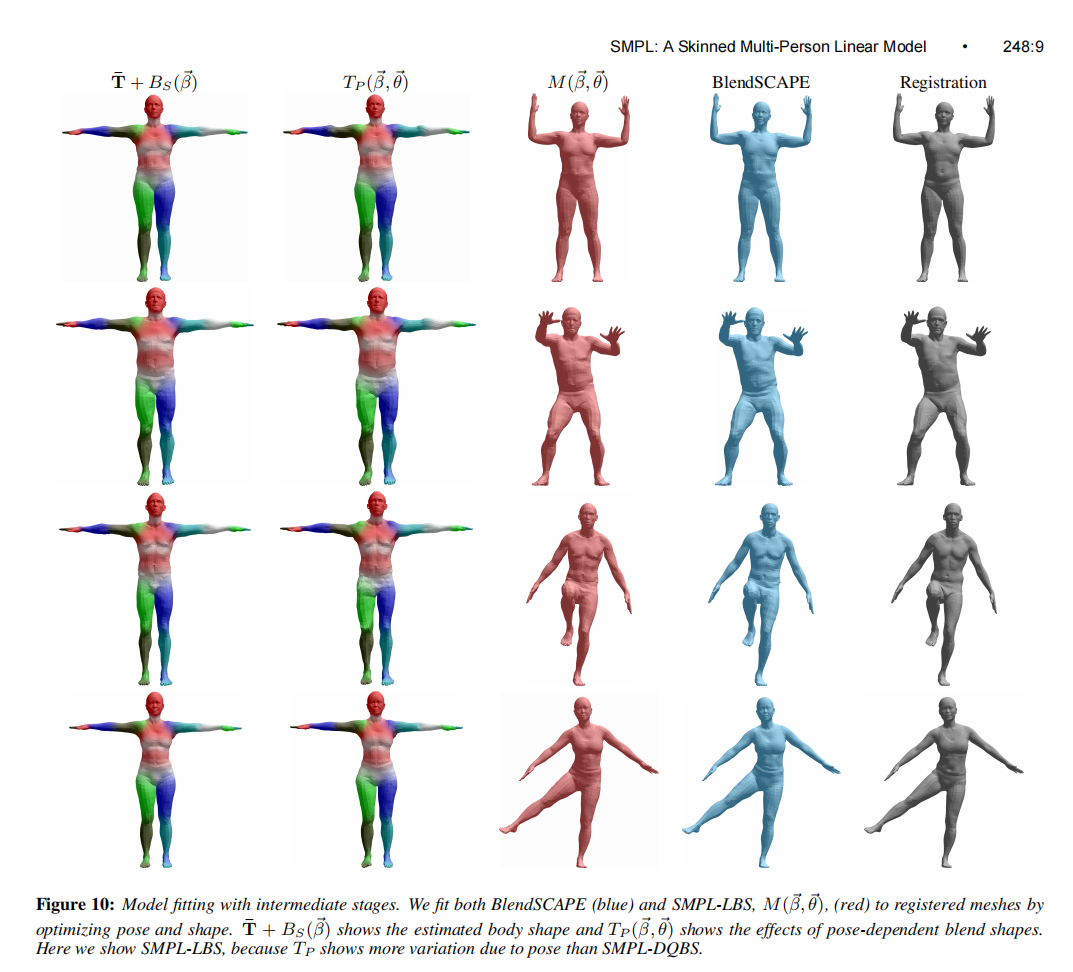
我们评估了SMPL-LBS和SMPL-DQBS。我们还将其与根据与SMPL模型实际相同的数据训练的BlendSCAPE模型进行了比较。我们评估两种类型的错误。模型泛化是模型适应新人物和新姿势的网格的能力;这将测试形状和姿势混合形状。姿势泛化是将一个人的形状泛化为同一个人的新姿势的能力;这主要测试姿势混合形状校正蒙皮伪影和姿势相关变形的效果。两者都是通过模型和测试注册之间的平均绝对顶点到顶点距离来测量的。在这项评估中,我们使用了来自公共Dyna数据集[Dyn 2015]的四名女性和两名男性的120个注册网格。这些网格包含各种身体形状和姿势。
所有网格都与我们的模板对齐,没有一个用于训练我们的模型。图10(灰色)显示了这些注册网格的四个示例。
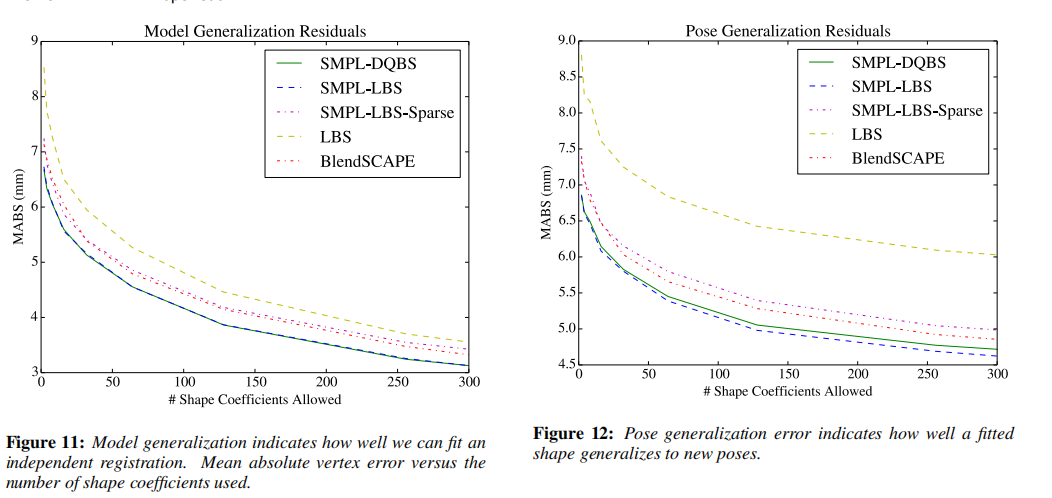
曲线图还显示了标准LBS与测试数据的拟合程度。
这对应于没有姿势混合形状的SMPL-LBS模型。毫不奇怪,LBS产生的误差比BlendSCAPE或SMPL高得多。LBS在图中并没有那么糟糕。11是因为这里的模型可以改变体型参数,有效地利用身份的变化来解释由于姿势引起的变形。图12使用了一个固定的身体形状,从而说明了LBS如何不真实地建模与姿势相关的变形。请注意,这里我们没有专门针对LBS重新训练模型,并期望这样的模型会稍微更准确。
与渲染引擎相比较
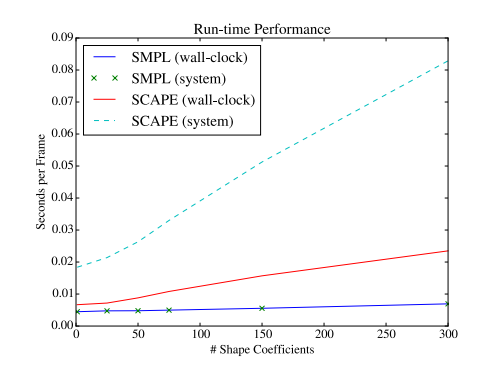
SMPL和BlendSCAPE的性能随着所使用的体型系数的数量而变化。此处显示的性能来自2014款Macbook Pro。
我们已经在Maya、Unity和Blender中测试了动画FBX文件。在给定姿势的情况下,姿势混合权重也可以在飞行中计算~?t、 为了实现这一点,我们提供了获取关节角度并计算姿势混合权重的脚本。我们已经在Maya 2013、2014和2015中测试了SMPL的加载和动画设置。动画师可以设置t的动画。
动态SMPL
虽然SMPL用姿势来模拟静态软组织变形,但它不模拟由于身体移动和与地面的冲击力而发生的动态变形。给定包含软组织动力学的4D配准,我们通过仅优化具有个性化模板形状的SMPL模型的姿态来拟合它们。SMPL和观察到的网格之间的错位对应于动态软组织运动。为了对这些进行建模,我们引入了一组新的添加混合形状,我们称之为动态混合形状。
讨论
在这里,我们使用了数千个高质量的注册模板网格。
重要的是,姿势训练数据涵盖了一系列体型,使我们能够很好地预测关节位置。其次,训练所有参数(模板形状、混合权重、关节回归器、形状/姿势/动态混合形状)以最大限度地减少顶点重建误差对于获得良好的模型很重要。在这里,模型的简单性是一个优势,因为它可以用大量数据训练每一件事。SMPL是顶点空间中的一个加性模型。相反,虽然SCAPE也将变形分解为形状和姿势变形,但SCAPE会将三角形变形相乘。
SMPL使用207个姿势混合形状。这可能会通过对混合形状执行PCA来减少。这将减少乘法运算的次数,从而提高运算速度。此外,我们的动态模型使用PCA来学习动态混合形状,但我们可以像学习姿势混合形状一样直接学习这些混合形状的元素。最后,在这里,我们将我们的模型拟合到注册的网格,但可以将SMPL拟合到mocap标记数据、深度数据或视频。我们预计,优化SMPL-LBS模型的姿态和形状将比优化类似质量的SCAPE模型快得多
结论
作者的目标是创建一个骨骼驱动的人体模型,该模型可以捕捉体型和姿势的变化,以及或优于以前最好的模型,同时与现有的图形管道和软件兼容。为此,SMPL使用标准蒙皮方程并定义修改基础网格的身体形状和姿势混合形状。作者对不同姿势的不同人群进行数千次对齐扫描,以训练模型。该模型的形式使得可以从大量数据中学习参数,同时直接最小化顶点重建误差。具体来说,作者学习休息模板、关节回归器、体型模型、姿势混合形状和动态混合形状。令人惊讶的结果是,当在完全相同的数据上训练BlendSCAPE和SMPL时,基于顶点的模型比基于变形的模型更准确,渲染效率也高得多。
总结
人体可以理解为是一个基础模型和在该模型基础上进行形变的总和,在形变基础上进行PCA,得到刻画形状的低维参数——形状参数(shape);同时,使用运动树表示人体的姿势,即运动树每个关节点和父节点的旋转关系,该关系可以表示为三维向量,最终每个关节点的局部旋转向量构成了smpl模型的姿势参数(pose)。考虑到与目前的市面上的渲染器,SMPL模型使用得较多。总结:三维参数化人体模型被广泛使用,它是估计人体三维姿态和形状的有力先验。其主要思想是通过低维参数对三维人体(包括脸、手和身体)的变形进行建模 。
数据集:
ICCV 2023 | SynBody:用于三维人体感知和建模的基于分层人体模型的合成数据集
SynBody的核心是一个分层的参数化人体模型
CAESAR dataset
Dyna dataset
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!