正则表达式:简化模式匹配的利器
正则表达式:简化模式匹配的利器
在软件开发和文本处理中,经常需要进行模式匹配和文本搜索。这时,正则表达式是一种强大的工具,可以帮助我们高效地进行字符串匹配和处理。本文将介绍正则表达式的基本概念和用法,帮助读者掌握这个强大的工具。
一、正则表达式简介
1.1 正则表达式介绍
正则表达式(Regular Expression),通常缩写为Regex或RegExp,是一种用来匹配字符串模式的文本模式,也可以称为模式字符串,它由一系列字符和特殊字符组成,用于文本处理、搜索、匹配和替换,正则表达式是一个强大的工具。
1.2 正则表达式使用场景
正则表达式常用于搜索文档、日志文件和代码中的特定文本模式。例如,查找包含特定关键词或短语的行。在表单验证和数据输入处理中,可以使用正则表达式来验证用户输入的数据是否符合特定的格式,如电子邮件地址、电话号码、日期、密码等。在日志文件中,正则表达式可用于提取有关系统运行状况、错误或警告的信息,以便分析和报告。
正则表达式广泛应用于各种编程语言和工具中。以下是几个常见的应用场景:
- 字符串匹配:使用正则表达式在文本中查找指定模式的字符串。
- 字符串替换:使用正则表达式将字符串中的特定模式替换为指定内容。
- 表单验证:使用正则表达式验证用户输入的表单数据,如手机号码、邮箱等。
- 数据抽取:使用正则表达式从文本中提取特定模式的数据。
二、正则表达式语法
2.1 正则表达式元字符和特性
📍 字符匹配
- 普通字符:普通字符按照字面意义进行匹配,例如匹配字母 “a” 将匹配到文本中的 “a” 字符。
- 元字符:元字符具有特殊的含义,例如
\d匹配任意数字字符,\w匹配任意字母数字字符,.匹配任意字符(除了换行符)等。
📍 量词
*:匹配前面的模式零次或多次。+:匹配前面的模式一次或多次。?:匹配前面的模式零次或一次。{n}:匹配前面的模式恰好 n 次。{n,}:匹配前面的模式至少 n 次。{n,m}:匹配前面的模式至少 n 次且不超过 m 次。
*和+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
📍 字符类
[ ]:匹配括号内的任意一个字符。例如,[abc]匹配字符 “a”、“b” 或 “c”。[^ ]:匹配除了括号内的字符以外的任意一个字符。例如,[^abc]匹配除了字符 “a”、“b” 或 “c” 以外的任意字符。
📍 边界匹配
^:匹配字符串的开头。$:匹配字符串的结尾。\b:匹配单词边界。\B:匹配非单词边界。
📍 分组和捕获
( ):用于分组和捕获子表达式。(?: ):用于分组但不捕获子表达式。
📍 特殊字符
\:转义字符,用于匹配特殊字符本身。.:匹配任意字符(除了换行符)。|:用于指定多个模式的选择。
📍 非捕获元
-
?::为正向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串 -
?=和?!:为负向预查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串
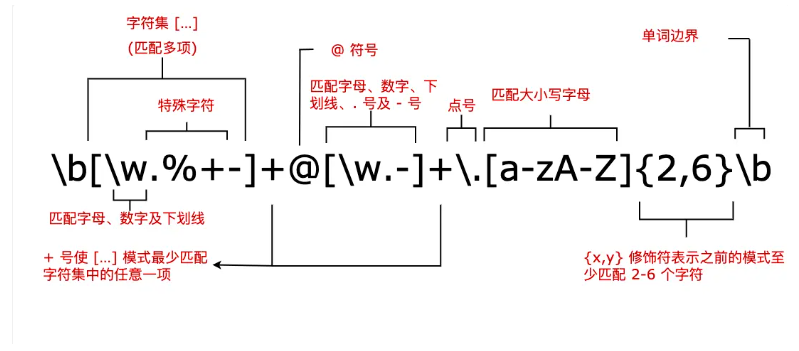
2.2 正则表达式常用匹配
[ABC]:匹配 […] 中的所有字符[^ABC]:匹配除了 […] 中字符的所有字符[A-Z]: [A-Z] 表示一个区间,匹配所有大写字母,[a-z]表示所有小写字母.:匹配除换行符(\n、\r)之外的任何单个字符,相等于[^\n\r][\s\S]:匹配所有。\s是匹配所有空白符,包括换行,\S非空白符,不包括换行\w:匹配字母、数字、下划线。等价于[A-Za-z0-9_]\d:匹配任意一个阿拉伯数字(0 到 9)。等价于[0-9]\n:匹配一个换行符\r:匹配一个回车符\s:匹配任何空白字符,包括空格、制表符、换页符等\S:匹配任何非空白字符\t:匹配一个制表符?=:exp1(?=exp2):查找 exp2 前面的 exp1?<=:(?<=exp2)exp1:查找 exp2 后面的 exp1?!:exp1(?!exp2):查找后面不是 exp2 的 exp1?<!:(?<!exp2)exp1:查找前面不是 exp2 的 exp1
三、正则表达式实战
3.1 常见的正则表达式用法
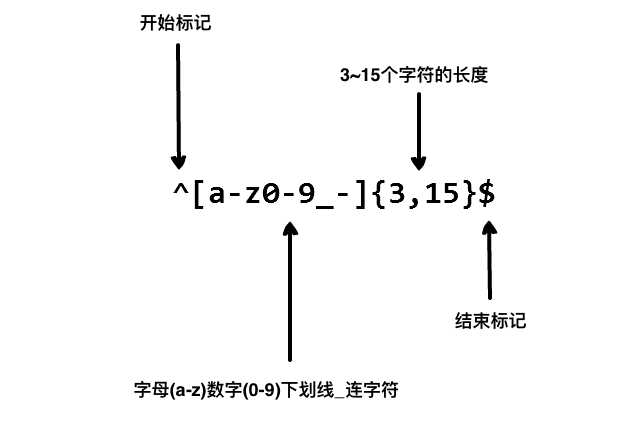
- 邮箱验证:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ - 手机号码验证:
^1[3456789]\d{9}$ - URL 提取:
^(https?|ftp)://[^\s/$.?#].[^\s]*$ - 数字提取:
\d+ - IP 地址验证:
^((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)$
3.2 正则表达式的过滤用法
🚀 过滤用法之或
在使用grep命令进行正则表达式匹配时,可以使用-E选项来启用扩展正则表达式。然后,你可以使用以下正则表达式来匹配包含"string1"或"string2"的文本:
grep -E "string1|string2" <file>
在上面的命令中,你需要将<file>替换为你要搜索的文件名或路径。string1和string2是你要匹配的两个字符串。
-E选项告诉grep使用扩展正则表达式,其中的|表示逻辑或操作符。
请确保使用实际的文件名和字符串来替换命令中的占位符。另外,grep命令默认区分大小写。如果你想进行大小写不敏感的匹配,可以添加-i选项,如grep -Ei "string1|string2" <file>。这将在忽略大小写的情况下匹配字符串。
🚀 过滤用法之与
要使用grep命令匹配同时包含"string1"和"string2"的文本行,你可以使用正则表达式的正向肯定前瞻(positive lookahead)来实现。
以下是一个示例正则表达式,用于匹配同时包含"string1"和"string2"的文本行:
grep -E "^(?=.*string1)(?=.*string2)" <file>
在上面的命令中,你需要将<file>替换为你要搜索的文件名或路径。string1和string2是你要匹配的两个字符串。
正则表达式使用正向肯定前瞻,分别包含两个部分:
(?=.*string1):表示在当前位置向前查找,必须包含"string1"。(?=.*string2):表示在当前位置向前查找,必须包含"string2"。
使用^匹配行的开头,确保这两个条件都适用于整行。
请确保使用实际的文件名和字符串来替换命令中的占位符。另外,grep命令默认区分大小写。如果你想进行大小写不敏感的匹配,可以添加-i选项,如grep -Ei "^(?=.*string1)(?=.*string2)" <file>。这将在忽略大小写的情况下匹配字符串。
3.3 正则表达式的代码用法
- Java 正则代码
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
public static void main(String args[]) {
String str = "";
String pattern = "";
Pattern r = Pattern.compile(pattern);
Matcher m = r.matcher(str);
System.out.println(m.matches());
}
}
- Python 正则代码
import re
pattern = re.compile(ur'')
str = u''
print(pattern.search(str))
四、结论
正则表达式是一种强大而灵活的工具,可以帮助我们在文本处理和模式匹配中提高效率。本文介绍了正则表达式的基本概念和常见用法,希望读者能够掌握这个重要的工具,并在实际开发中灵活应用。通过深入学习和实践,你将能够更加熟练地使用正则表达式解决各种文本处理的挑战。
相关参考
[1] OSChina 正则表达式手册
[2] 菜鸟教程 - 正则表达式 - 语法
[3] 正则表达式在线测试
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!