实验用python实现决策树和随机森林分类
1.实验目的
1.会用Python提供的sklearn库中的决策树算法对数据进行分类
2.会用Python提供的sklearn库中的随机森林算法对数据进行分类
3.会用Python提供的方法对数据进行预处理
2.设备与环境
使用Spyder并借助Python语言进行实现
3.实验原理
决策树( Decision Tree) 又称为判定树,是数据挖掘技术中的一种重要的分类与回归方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
决策树的构建
1.特征选择:选取有较强分类能力的特征。
2.决策树生成:典型的算法有 ID3 和 C4.5, 它们生成决策树过程相似, ID3 是采用信息增益作为特征选择度量, 而 C4.5 采用信息增益比率。
3.决策树剪枝:剪枝原因是决策树生成算法生成的树对训练数据的预测很准确, 但是对于未知数据分类很差, 这就产生了过拟合的现象。涉及算法有CART算法。


4.实验内容
使用决策树算法和随机森林算法对income_classification.csv的收入水平进行分类。训练集和测试集的比例是7:3,选取适当的特征列,使得针对测试样本的分类准确率在80%以上,比较2种分类方法的准确率。
数据说明:
特征列:
age:年龄,整数
workclass:工作性质,字符串
education:教育程度,字符串
education_num:受教育年限,整数
maritial_status:婚姻状况,字符串
occupation:职业,字符串
relationship:亲戚关系,字符串
race:种族,字符串
sex:性别,字符串
capital_gain:资本收益,浮点数
capital_loss:资本损失,浮点数
hours_per_week:每周工作小时数,浮点数
native_country:原籍,字符串
分类标签列:income
imcome > 50K
Imcome ≤ 50K
1.读入数据并显示数据的维度和前5行数据
import pandas as pd
import numpy as np
2. 对连续变量年龄进行离散化,并显示前5行数据离散化后的结果
age_bins = [20, 30,40, 50, 60, 70]
3.对属性是字符串的任意特征进行数字编号处理,显示前5行编码后的结果,每个特定的字符串用一个整数来表示,整数序列从0开始增长。
from sklearn.preprocessing import LabelEncoder
enc = LabelEncoder()
4.对预处理后的数据用决策树算法和随机森林算法分类
实验步骤
- 选择合适的若干特征字段
- 按7:3划分训练集和样本集
- 使用训练集训练一个决策树分类器
- 使用测试集计算决策树分类器的分类准确率
- 使用训练集训练一个随机森林分类器
- 使用测试集计算随机森林分类器的分类准确率
fromsklearn.ensemble import RandomForestClassifier
from sklearn importtree
fromsklearn.preprocessing import LabelEncoder
fromsklearn.feature_extraction import DictVectorizer
accuracy_random =clf_random.score(xTest, yTest)
5.实验结果分析
利用决策树和随机森林求解得到的结果如下:

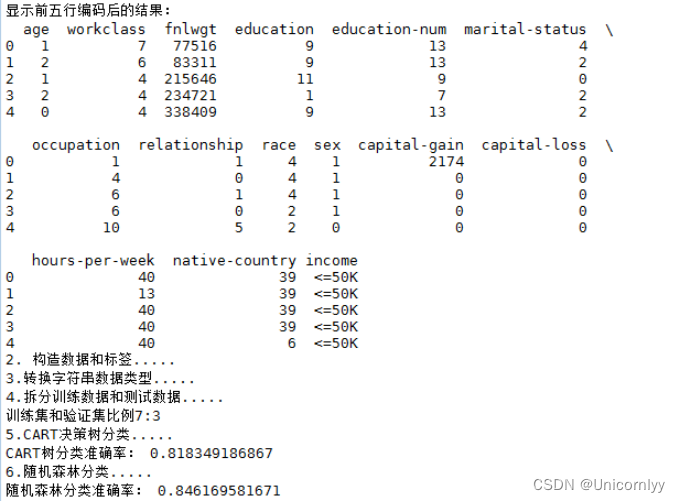
6.附录(代码)
#决策树和随机森林:
import numpy as np
import pandas as pd
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import LabelEncoder
print('1.载入数据.....')
data = pd.read_excel(r"C:\Users\user\Desktop\income_classification.xlsx", header=0)
print('数据的维度和前五行数据:', data.shape)
print(data.head())
print('对连续变量age进行离散化处理,等宽分成五类,显示前五行:')
AGE_CUT = pd.cut(x=data['age'], bins=5, labels=range(0, 5))
data['age'] = AGE_CUT
print(data.head(5))
class_le = LabelEncoder()
data['workclass'] = pd.DataFrame(class_le.fit_transform(data['workclass']))
data['marital-status'] = pd.DataFrame(class_le.fit_transform(data['marital-status']))
data['occupation'] = pd.DataFrame(class_le.fit_transform(data['occupation']))
data['education'] = pd.DataFrame(class_le.fit_transform(data['education']))
data['native-country'] = pd.DataFrame(class_le.fit_transform(data['native-country']))
data['relationship'] = pd.DataFrame(class_le.fit_transform(data['relationship']))
data['race'] = pd.DataFrame(class_le.fit_transform(data['race']))
data['sex'] = pd.DataFrame(class_le.fit_transform(data['sex']))
print('显示前五行编码后的结果:')
print(data.head(5))
data1 = []
labels = []
for index, row in data.iterrows():
# data需要是字典形式,因为之后需要使用DictVectorizer()修改字符串数据类型,以便符合DecisionTreeClassifier()
rowDict = {}
row = list(row)
rowDict['age'] = row[0]
rowDict['workclass'] = row[1]
rowDict['education'] = row[2]
rowDict['education_num'] = row[3]
rowDict['maritial_status'] = row[4]
rowDict['occupation'] = row[5]
rowDict['relationship'] = row[6]
rowDict['race'] = row[7]
rowDict['sex'] = row[8]
rowDict['capital_gain'] = row[9]
rowDict['capital_loss'] = row[10]
rowDict['hours_per_week'] = row[11]
rowDict['native_country'] = row[12]
data1.append(rowDict)
labels.append(row[-1])
print('2. 构造数据和标签.....')
x = np.array(data1)
labels = np.array(labels)
y = np.zeros(labels.shape) # 初始label全为0
y[labels == '<=50K'] = 0 # 当label等于这三种属性的话,设置为1。
y[labels == '>50K'] = 1
# 转换字符串数据类型
print('3.转换字符串数据类型.....')
vec = DictVectorizer()
dx = vec.fit_transform(x).toarray()
# 拆分成训练数据和测试数据
print('4.拆分训练数据和测试数据.....')
print('训练集和验证集比例7:3')
ratio = 0.7
xTrain = []
yTrain = []
xTest = []
yTest = []
features = xTrain, xTest
labels = yTrain, yTest
for i in range(len(dx)):
dataSetIndex = 0 if np.random.random() < ratio else 1
features[dataSetIndex].append(dx[i])
labels[dataSetIndex].append(y[i])
# CART决策树分类
print('5.CART决策树分类.....')
clf_cart = tree.DecisionTreeClassifier(criterion='entropy') # CART算法,使用entropy作为标准;默认是是用gini作为标准
clf_cart.fit(xTrain, yTrain)
# 检查准确率
accuracy_cart = clf_cart.score(xTest, yTest)
print('CART树分类准确率:', accuracy_cart)
print('6.随机森林分类.....')
clf_random = RandomForestClassifier()
clf_random.fit(xTrain, yTrain)
# 检查准确率
accuracy_random = clf_random.score(xTest, yTest)
print('随机森林分类准确率:', accuracy_random)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!