十一种无监督聚类算法说明
目录
三、Gaussian Mixture Model -- Distribution models?
无监督聚类是一种机器学习技术,用于将数据分组成不同的类别,而无需提前标记或指导。在无监督聚类中,算法通过分析数据之间的相似性和差异性,自动将数据划分为具有相似特征的组。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.cluster as cluster
import time
%matplotlib inline
data = np.load('clusterable_data.npy')#这是一个类似细胞的数据集
plt.scatter(data.T[0], data.T[1], c='b')
frame = plt.gca()
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False)
?
一、前八种聚类方法八种无监督聚类算法说明-CSDN博客
二、OPTICS -- Density Models
OPTICS (Ordering Points To Identify the Clustering Structure)是一种基于密度的聚类算法。它可以帮助发现数据集中的聚类结构,包括确定聚类的核心点和边界点,并按照密度的降序对数据点进行排列,从而揭示出聚类结构的层次关系。
与其他聚类算法不同,OPTICS不需要事先设定聚类的数量。它通过计算每个数据点与其邻域内的其他数据点之间的可达距离来衡量数据点的密度。可达距离是指从一个数据点到达另一个数据点的最短距离,考虑了密度变化的情况。通过计算可达距离,OPTICS可以建立一个可达距离图,反映出数据点之间的密度变化情况。
在可达距离图中,数据点可以分为核心点、边界点和噪声点。核心点是密度较高的数据点,边界点是介于核心点和噪声点之间的数据点,噪声点是密度较低的数据点。通过对可达距离图进行分析,可以将数据点按照密度的降序排列,从而揭示出聚类结构的层次关系。
总之,OPTICS算法是一种无需预先设定聚类数量的聚类算法,利用密度信息帮助发现聚类结构,并提供了一种可视化的方式来显示聚类结构的层次关系。
#OPTICS -- Density Models 低密度到高密度记录
from numpy import unique
from sklearn.cluster import OPTICS
from matplotlib import pyplot
# define the model
model = OPTICS(min_samples=15)
# fit model and predict clusters
yhat = model.fit_predict(data)
# retrieve unique clusters
clusters = unique(yhat)
palette = sns.color_palette('deep', np.unique(yhat).max() + 1)
colors = [palette[x] if x >= 0 else (0.0, 0.0, 0.0) for x in yhat]
plt.scatter(data.T[0], data.T[1], c=colors)
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False)
plt.title('Clusters found by OPTICS')
clusters
#结果:array([-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])

三、Gaussian Mixture Model -- Distribution models?
Gaussian Mixture Model (GMM)是一种概率模型,用于对数据进行聚类和分布建模。它假设数据是由多个高斯分布组成的混合体。
GMM的基本思想是将数据看作是由若干个高斯分布组合而成的,每个高斯分布都代表了一个聚类。每个高斯分布都有自己的均值和协方差矩阵,用于描述该聚类的位置和形状。
GMM的参数包括每个高斯分布的均值、协方差矩阵和权重。权重表示了每个高斯分布在整个混合模型中的占比。模型的目标是通过调整参数来最大化观察数据的似然性。
在使用GMM进行聚类时,可以使用模型的概率密度函数来计算每个数据点属于每个聚类的概率,然后根据概率值将数据点分配到最可能的聚类中。这使得GMM可以处理具有模糊边界的聚类问题,即数据点可能属于多个聚类的情况。
GMM在很多领域都有应用,例如图像分割、语音识别、异常检测等。它可以灵活地适应不同形状和大小的聚类,并具有较强的建模能力和灵活性。
from numpy import unique
from sklearn.mixture import GaussianMixture
from matplotlib import pyplot
# define the model
model = GaussianMixture(n_components=6)
# fit model and predict clusters
yhat = model.fit_predict(data)
# retrieve unique clusters
clusters = unique(yhat)
palette = sns.color_palette('deep', np.unique(yhat).max() + 1)
colors = [palette[x] if x >= 0 else (0.0, 0.0, 0.0) for x in yhat]
plt.scatter(data.T[0], data.T[1], c=colors)
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False)
plt.title('Clusters found by GaussianMixture')
clusters
#array([0, 1, 2, 3, 4, 5], dtype=int64)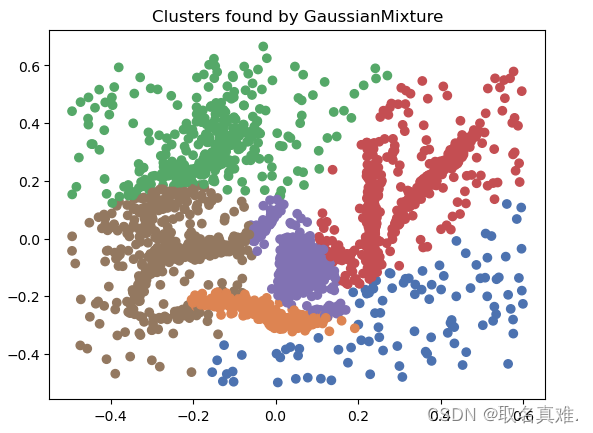
四、HDBSCAN -- Density Models
HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的层次聚类算法,用于发现具有不同形状和大小的密度连续区域(clusters)。
HDBSCAN是一种基于DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法的改进版本。DBSCAN通过将数据点划分为核心点、边界点和噪声点,以及以核心点为中心的局部密度来进行聚类。但是,DBSCAN对于具有不同密度级别的聚类效果可能不佳,并且对于密度变化较大的数据集,它的聚类结果可能不稳定。
HDBSCAN通过创建一棵基于密度的层次聚类树来解决这些问题。聚类树将数据点组织成一个层次结构,其中每个叶子节点表示一个聚类,而内部节点表示不同分辨率下的聚类变化。通过分析聚类树上的不同分支,可以确定最佳的聚类结果,同时还可以识别和标记噪声点。
HDBSCAN的核心概念是定义一种称为“稳定点”的度量方式,用于确定聚类的核心点。稳定点是指在不同密度阈值下仍然保持在同一聚类中的数据点。通过确定稳定点和聚类的关系,HDBSCAN可以识别出具有不同形状和大小的聚类,并且对于密度变化较大的数据集也具有较好的稳定性。
HDBSCAN可以应用于各种领域,包括图像分析、文本挖掘、生物信息学等,以发现和分析数据中的聚类结构。
import hdbscan
from numpy import unique
from matplotlib import pyplot
# define the model
model = hdbscan.HDBSCAN(min_cluster_size=15)
# fit model and predict clusters
yhat = model.fit_predict(data)
# retrieve unique clusters
clusters = unique(yhat)
palette = sns.color_palette('deep', np.unique(yhat).max() + 1)
colors = [palette[x] if x >= 0 else (0.0, 0.0, 0.0) for x in yhat]
plt.scatter(data.T[0], data.T[1], c=colors)
frame = plt.gca()
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False)
plt.title('Clusters found by HDBSCAN')
clusters
#结果:array([-1, 0, 1, 2, 3, 4, 5], dtype=int64)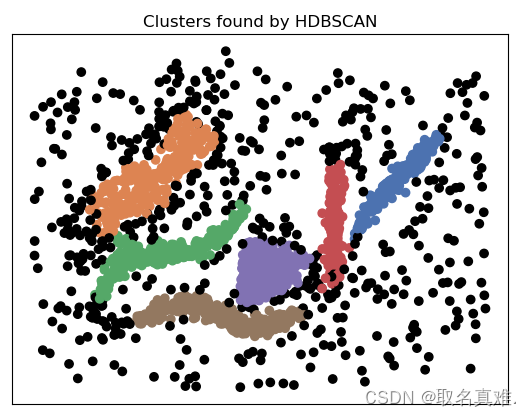
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [论文精读]Few-shot domain-adaptive anomaly detection for cross-site brain images
- 练习题 将x减到0的最小操作数
- 海外静态IP和动态IP有什么区别?推荐哪种?
- 企业电子招投标系统源码之电子招投标系统建设的重点和未来趋势
- MATLAB --- 如何对 hold on 和 hold off 绘制的图像进行保存
- DES算法
- Spring cloud聚合父工程project
- Redis入门-在Java中操作Redis
- uniapp todo list
- web三层架构