LLM之RAG实战(十)| 如何构建一个RAG支持的聊天机器人,包括聊天、嵌入和重排序
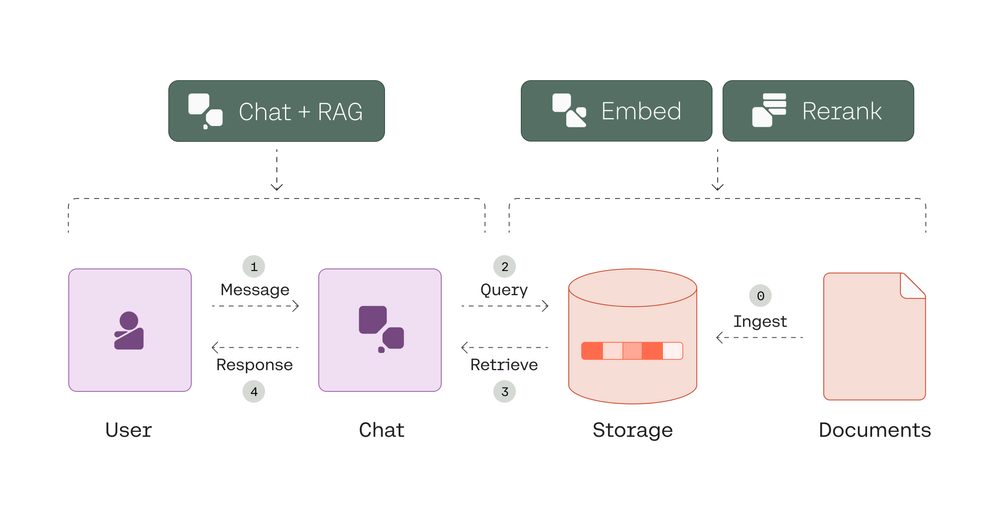
? ? ? ?在人工智能和机器学习不断发展的环境中,聊天机器人变得越来越复杂,从简单的基于规则的回复转变为基于上下文的对话。在这篇博客文章中,我们将深入研究创建一个RAG支持的聊天机器人,该聊天机器人利用先进的NLP模型进行聊天、嵌入和重新排序,并使用hnswlib进行高效的文档检索。
设置环境
? ? ? 在深入研究代码之前,请确保安装了必要的库。这包括cohere、hnswlib和非结构化。可以使用pip安装它们:
pip install cohere hnswlib unstructured? ? ? ?此外,请确保正确设置了环境变量,尤其是COHERE_API_KEY,因为它对于访问Cohere的API至关重要。
步骤1:准备文档集合
? ? ?我们的聊天机器人需要一个知识库来提取信息。为此,需要创建一个Documents类:
- 从URLs收集源文档;
- 使用HTML分区和基于标题的分块将这些文档划分为块;
- 使用Cohere的嵌入模型嵌入这些块,以便后续进行检索。
class Documents:def __init__(self, sources):# Initialization and methods to load, embed, and index documents# ...?def load(self):# Load and partition documents# ...?def embed(self):# Embed documents using Cohere# ...?def index(self):# Create hnswlib index# ...
步骤2:使用hnswlib对文档建立索引
? ? ? 一旦文档准备好并表示为嵌入,就可以使用hnswlib创建一个高效的索引,聊天机器人根据查询嵌入快速检索最相关的文档。
# Indexing snippet from the Documents classdef index(self):print("Indexing documents...")self.idx = hnswlib.Index(space="ip", dim=1024)self.idx.init_index(max_elements=self.docs_len, ef_construction=512, M=64)self.idx.add_items(self.docs_embs, list(range(self.docs_len)))print(f"Indexing complete with {self.idx.get_current_count()} documents.")
步骤3:建立聊天机器人
? ? ??Chatbot类可以利用Cohere的聊天和重排序API生成响应并细化搜索结果。
- generate_response方法处理用户消息、生成搜索查询并检索相关文档;
- 然后,使用这些文档生成上下文相关的响应。
class Chatbot:def __init__(self, docs):self.docs = docsself.conversation_id = str(uuid.uuid4())?def generate_response(self, message):# Generate and process responses# ...?def retrieve_docs(self, response):# Retrieve documents based on queries# ...
步骤4:与Streamlight集成
? ? ? ?要使聊天机器人具有互动性,可以使用Streamlit创建用户友好的web界面。Streamlit支持输入文本,并可以展示聊天机器人的响应。
import streamlit as st?def main():st.title("AI Chatbot")user_message = st.text_input("Enter your message:")if st.button("Send"):with st.spinner('Generating response...'):response = chatbot.generate_response(user_message)for event in response:st.write(event.text)?if __name__ == "__main__":main()
? ? ? ???运行聊天机器人
streamlit run app.py结论
? ? ? ?构建RAG支持的聊天机器人是创建能够以有意义的方式理解和响应人类查询的人工智能应用程序的重要一步。通过将Cohere的NLP模型和高效的文档检索相结合,您可以创建一个聊天机器人,它不仅能理解上下文,还能提供知情和准确的回复。
? ? ? ?该项目不仅展示了Generative AI的实际应用,而且对于那些希望深入研究AI和ML领域的人来说,它也是一个极好的学习工具。
? ? ? ?这是一个基本流程,可以更好地理解此应用程序的基本原理。
完整的代码,如下所示:
import streamlit as stimport cohereimport osimport hnswlibfrom your_existing_code import Documents, Chatbot?# Initialize the Cohere clientco = cohere.Client(os.environ["COHERE_API_KEY"])?# Define your sources here (or load them from an external source)sources = [{"title": "Similarity Between Words and Sentences","url": "https://docs.cohere.com/docs/similarity-between-words-and-sentences"},{"title": "The Attention Mechanism","url": "https://docs.cohere.com/docs/the-attention-mechanism"},{"title": "Transformer Models","url": "https://docs.cohere.com/docs/transformer-models"}]?# Create instances of your classesdocuments = Documents(sources)chatbot = Chatbot(documents)?# Streamlit appdef main():st.title("AI Chatbot")?# User message inputuser_message = st.text_input("Enter your message:", key="user_message")?# Chatbot responseif st.button("Send"):with st.spinner('Generating response...'):response = chatbot.generate_response(user_message)for event in response:st.write(event.text) # Display the chatbot's response?# Run the appif __name__ == "__main__":main()
参考文献:
[1]?https://medium.com/@fbanespo/how-to-build-a-rag-powered-chatbot-with-chat-embed-and-rerank-a6d8236d7be7
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue学习day_02
- 【PostgreSQL】数据查询-组合查询(UNION,INTERSECT,EXCEPT)
- 用友GRP-U8 UploadFile 文件上传漏洞
- 深入理解Java中的内部类和匿名类
- Java中的日期类
- RNN与NLP
- HTTP介绍
- zxz-uni-data-select插件,表单回显时,无法显示数据,原因是后端返回的数据是字符串,要把这个字符串转成number类型,就能显示了
- ElasticSearch的DSL查询语法解析
- 使用Watchtower自动更新Dcoker镜像与容器,像手机APP一样进行软件自动更新、选择性升级、手动升级、自动升级