设计模式④ :分开考虑
一、前言
有时候不想动脑子,就懒得看源码又不像浪费时间所以会看看书,但是又记不住,所以决定开始写"抄书"系列。本系列大部分内容都是来源于《 图解设计模式》(【日】结城浩 著)。该系列文章可随意转载。
二、Bridge 模式
Bridge 模式 :将类的功能层析结构与实现层次结构分离。
1. 介绍
Bridge 模式的作用是将两种东西连接起来,它们分别是 类的功能层次结构 和 类的实现层次结构,但是通常来说,类的层次结构不应当过深。
- 类的功能层次结构 :在父类中具有基本功能,在子类中增加新的功能。这种层次结构成为 类的功能层次结构。
- 类的实现层次结构:父类通过声明抽象方法来定义接口,子类通过实现具体方法来实现接口。这种层次结构称为 类的实现层次结构。
Bridge 模式登场的角色
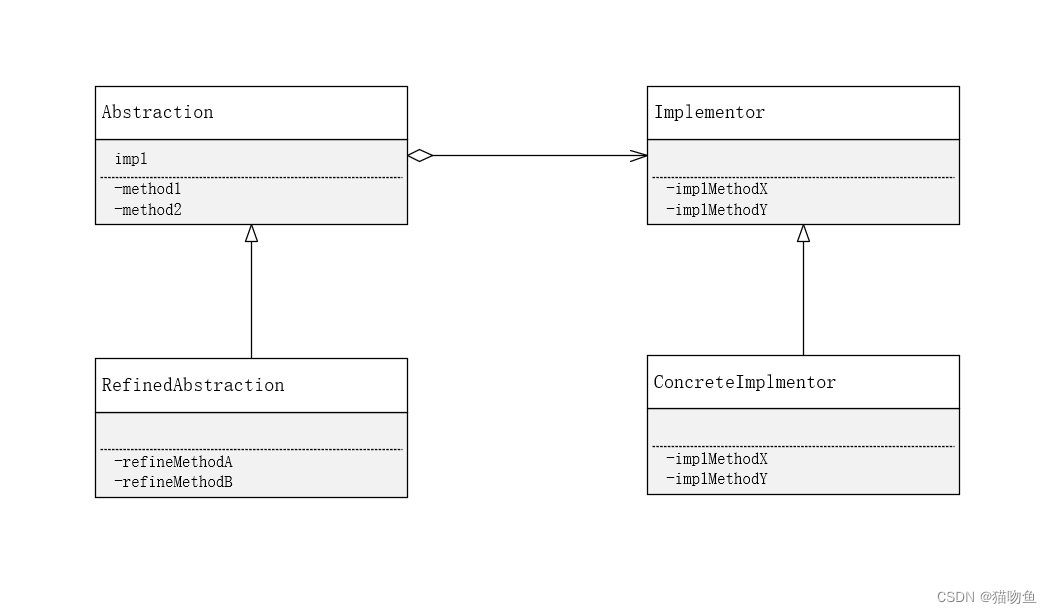
- Abstraction (抽象化) : 该角色位于“类的功能层次结构”的最上层,他使用 Implementor 角色的方法定义了基本的功能。该角色保存了 Implementor 角色的实例。在示例程序中,由 Display 类扮演此角色。
- RefineAbstraction (改善后的抽象化) :在 Abstraction 角色的基础上增加了新功能的角色。在示例程序中,由 CountDisplay 类扮演此角色。
- Implementor (实现者) :该角色位于“类的实现层次结构”的最上层,他定义了用于实现 Abstraction 角色的接口的方法。在示例程序中由 DisplayImple 类扮演此角色。
- ConcreteImplementor (具体实现者) :该角色负责实现在 Implementor 角色中定义的接口(API)。在实例程序中,由 StringDisplayImple 类扮演该角色。
类图如下,左侧的两个类构成了“类的功能层次结构”,右侧的两个类构成了“类的实现层次结构”。类的两个层次结构之间的桥梁是 impl 字段:
Demo 如下:
// 类的功能层次结构
public class Display {
private DisplayImpl impl;
public Display(DisplayImpl impl) {
this.impl = impl;
}
public void open() {
impl.rawOpen();
}
public void print() {
impl.rawPrint();
}
public void close() {
impl.rawClose();
}
}
// 类的实现层次结构
public interface DisplayImpl {
void rawOpen();
void rawPrint();
void rawClose();
}
// 类的实现层次结构
public class StringDisplayImpl implements DisplayImpl {
@Override
public void rawOpen() {
System.out.println("StringDisplayImpl.rawOpen");
}
@Override
public void rawPrint() {
System.out.println("StringDisplayImpl.rawPrint");
}
@Override
public void rawClose() {
System.out.println("StringDisplayImpl.rawClose");
}
}
// 类的功能层次结构
public class CountDisplay extends Display {
public CountDisplay(DisplayImpl impl) {
super(impl);
}
public void multiDisplay() {
for (int i = 0; i < 3; i++) {
print();
}
}
}
public class BridgeDemoMain {
public static void main(String[] args) {
Display display1 = new Display(new StringDisplayImpl());
Display display2 = new CountDisplay(new StringDisplayImpl());
display1.display();
System.out.println("--------------------------------");
display2.display();
System.out.println("--------------------------------");
((CountDisplay)display2).multiDisplay();
}
}
输出结果:
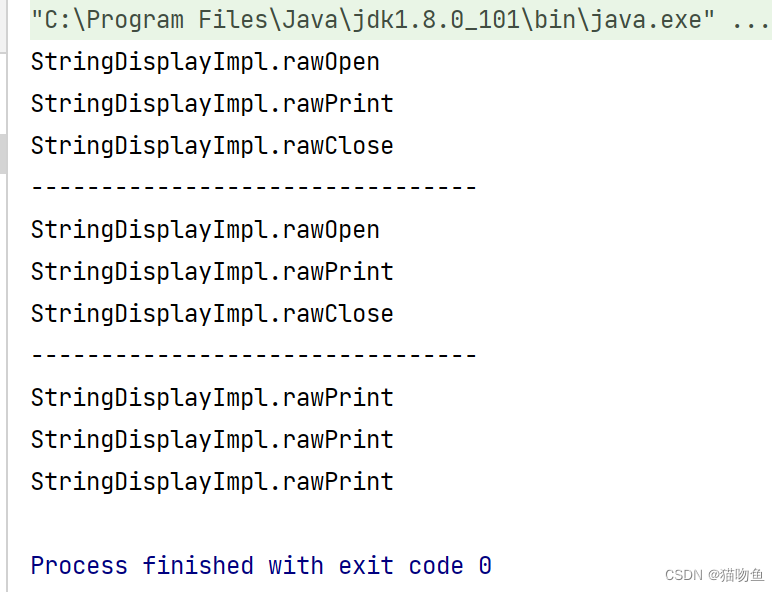
综上:通过 CountDisplay 类完成了对 Display 类的方法扩展,即类的功能层次结构扩展。通过 DisplayImpl 类完成了与 Display 的解耦,Display 将 open、print、close 方法委托给了 impl 来实现,即类的实现层次结构扩展。
2. 应用
-
Spring 中的 BeanPostProcessor 接口:在 Spring 中 Bean 创建前后会调用 BeanPostProcessor 的方法来对 Bean进行前置或后置处理,而 BeanPostProcessor 具有很多子接口,如 InstantiationAwareBeanPostProcessor 、MergedBeanDefinitionPostProcessor 等,其子接口都各自增加了自己的方法。如下接口定义:
public interface BeanPostProcessor { @Nullable default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException { return bean; } @Nullable default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException { return bean; } } public interface InstantiationAwareBeanPostProcessor extends BeanPostProcessor { @Nullable default Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException { return null; } default boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException { return true; } @Nullable default PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) throws BeansException { return null; } @Deprecated @Nullable default PropertyValues postProcessPropertyValues( PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeansException { return pvs; } }
个人使用:该部分内容是写给自己看的,帮助自身理解,因此就不交代项目背景了,读者请自行忽略(???):
-
项目A中需要对文件进行解析,当时为了兼容各种文件,定义了文件解析委托类,并且在此基础上进行了扩展,如下,不同的文件类型基于自身的特性实现不同的接口来完成基础功能的解析:
// 接口, 文件解析委托类 public interface DocDelegate extends Closeable { /** * 读取全部内容 * * @return */ <K> K readContent(); /** * 关闭 * * @throws IOException */ @Override default void close() { } } // 用于解析可以按行读取的文件,如 Excel public interface DocLineDelegate<T> extends DocDelegate { /** * 按行分割 内容 * * @return */ List<T> readLineContent(); } // 用于解析可以按页读取的文件,如Word public interface DocPageDelegate<T> extends DocDelegate { /** * 获取当前页数 * * @return */ int getNumberOfPages(); /** * 读取某一页的内容 * * @param page * @return */ T readPage(int page); }
3. 总结
Bridge 模式的特征是将“类的功能层次结构” 和“类的实现层次结构”分离开了。当想要增加功能时,只需要在“类的功能层次结构” 一侧增加类即可。不必对“类的实现层次结构”做任何修改,而且增加够的功能可以被“所有的实现”使用。
需要注意的是,虽然使用“继承”也很容易扩展类,但是类之前形成了一种强关联关系,如果需要修改类之前的关系,使用继承就不合适了,因为每次改变都需要修改原程序。这是便可以使用"委托"来代替“继承关系”。如上述Demo中,Display 将 open、print、close 方法委托给了 impl 来实现,如果需要改变关联关系,在创建 Display 时传入新的 Impl 实现即可。
三、Strategy 模式
Strategy 模式 : 整体地替换算法
1. 介绍
Strategy 模式登场的角色:
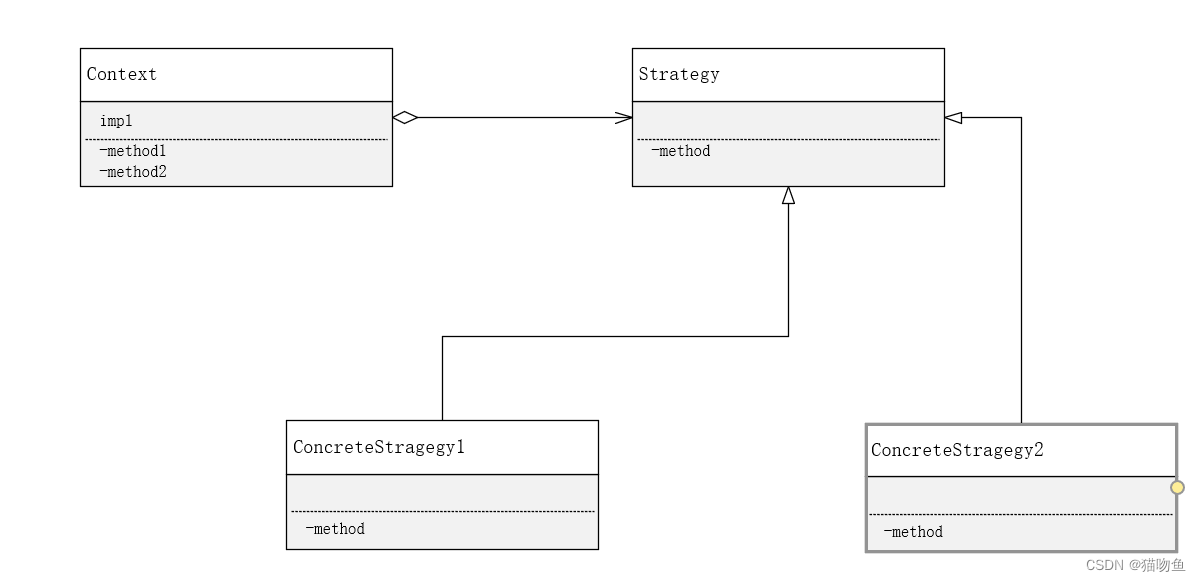
- Strategy (策略):Strategy 角色负责决定实现策略所必需的接口(API)。
- ConcreteStrategy(具体的策略):ConcreteStrategy角色负责实现 Strategy 角色的接口,即负责实现具体的策略。
- Context(上下文):负责使用Strategy 角色。Context 角色保存了 ConcreteStrategy 角色的实例,并使用ConcreteStrategy 角色去实现需求。
类图如下:
Demo如下:
// 策略接口
public interface Strategy {
int getNumber();
}
// 获取随机奇数
public class OddNumberStrategy implements Strategy {
@Override
public int getNumber() {
int number;
do {
number = RandomUtils.nextInt();
} while (number % 2 == 0);
return number;
}
}
// 获取随机偶数
public class EvenNumberStrategy implements Strategy {
@Override
public int getNumber() {
int number;
do {
number = RandomUtils.nextInt();
} while (number % 2 != 0);
return number;
}
}
//策略上下文,持有所有策略
public class StrategyContext {
private EvenNumberStrategy evenNumberStrategy = new EvenNumberStrategy();
private OddNumberStrategy oddNumberStrategy = new OddNumberStrategy();
public int getEventNumber(){
return evenNumberStrategy.getNumber();
}
public int getOddNumber(){
return oddNumberStrategy.getNumber();
}
}
public class StrategyDemoMain {
public static void main(String[] args) {
// 选择合适的策略执行
StrategyContext strategyContext = new StrategyContext();
final int oddNumber = strategyContext.getOddNumber();
final int eventNumber = strategyContext.getEventNumber();
System.out.println("oddNumber = " + oddNumber);
System.out.println("eventNumber = " + eventNumber);
}
}
2. 应用
-
线程池的任务拒绝策略:在我们自定义线程时是需要传入一个任务拒绝处理器,Java默认提供了多种拒绝策略的实现,通过选择不同的策略可以在线程池满任务时选择对应的处理方式,如丢失任务、抛出异常等。如下,可以通过传入不同的 RejectedExecutionHandler 来实现不同的拒绝策略。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; } -
Dubbo的负载均衡策略: Dubbo 通过 LoadBalance 接口完成负载均衡,而负载均衡有多种方案可以选择,如随机、轮询、按比重等等,Dubbo 对每种情况实现了各自的 LoadBalance ,然后根据配置选择合适的 LoadBalance 策略来完成负载均衡。
// AbstractLoadBalance 中,子类 LoadBalance 实现 doSelect 方法来实现自己的策略。 @Override public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) { if (CollectionUtils.isEmpty(invokers)) { return null; } if (invokers.size() == 1) { return invokers.get(0); } return doSelect(invokers, url, invocation); } protected abstract <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation);
个人使用:该部分内容是写给自己看的,帮助自身理解,因此就不交代项目背景了,读者请自行忽略(???):
-
项目A 中需要对文件进行解析读取,对于同一份文件,在不同的用途时需要解析获取的数据也不同,此时会为每种目的建立不同的读取策略,通过不同的策略来获取不同的信息。
-
项目B 中需要手动提供一个 TraceId 进行数据记录,对于这种情况肯定是通过AOP 完成,除此之外,为了普适性,额外提供了一个 TraceId 生成的策略类,如果某个项目需求不同,需要生成不同格式的 TraceId,则可以通过实现策略类来完成。如下:
public interface TraceIdStrategy { /** * 获取 id * * @return */ String getTraceId(); /** * 获取id * * @param traceId * @return */ String getTraceId(String traceId); } //提供一个默认的策略 public class DefaultTraceIdStrategy implements TraceIdStrategy { @Override public String getTraceId() { return UUID.randomUUID().toString(); } @Override public String getTraceId(String traceId) { return traceId; } } // 注入MDC @Order(Integer.MIN_VALUE) public class MDCTraceConfigurer implements WebMvcConfigurer { private final TraceIdStrategy traceIdStrategy; public MDCTraceConfigurer(ObjectProvider<TraceIdStrategy> traceIdStrategyOp) { this.traceIdStrategy = traceIdStrategyOp.getIfAvailable(DefaultTraceIdStrategy::new); } @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new MDCTraceInterceptor(traceIdStrategy)).addPathPatterns("/**"); } }
3. 总结
相关设计模式:
- Flyweight 模式 :有时会使用Flyweight 模式让多个地方可以共用 ConcreteStrategy 角色。
- Abstract Factory 模式 :使用 Strategy 模式可以整体替换算法,使用 Abstract Factory 模式则可以整体地替换具体工厂、零件和产品
- State 模式:使用Strategy 模式和 State模式都可以替换被委托对象,而且他们的类之间的关系也很相似。但是这两种模式的目的不同。Strategy 模式中 ConcreteStrategy 角色是代表算法的类。在 Strategy 模式中,可以替换被委托的对类。而在 State模式中,ConcreteState 角色是表示 “状态” 的类。在 State模式中,每次状态变化时,被委托对象的类都必定会被替换掉。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 编程笔记 html5&css&js 012 HTML分块
- 尝试使用深度学习识别百度旋转验证码
- 关于Switch和Random用法
- 窗口看门狗和独立看门狗的异同
- ABC208(A-C)
- 命令大杂烩
- Element Ui 表格自定义滚动条,以及自定义滚动条后出现空白问题
- 揭秘人工智能:探索智慧未来
- RHEL8_Linux使用podman管理容器
- htonl()、htons()、ntohl()、ntohs()四个函数