行云部署成长之路 -- 慢 SQL 优化之旅 | 京东云技术团队
当项目的SQL查询慢得像蜗牛爬行时,用户的耐心也在一点点被消耗,作为研发,我们可不想看到这样的事。这篇文章将结合行云部署项目的实践经验,带你走进SQL优化的奇妙世界,一起探索如何让那些龟速的查询飞起来!
序章:EXPLAIN - 揭开查询的神秘面纱
EXPLAIN命令是数据库管理员和SQL开发人员的一项强大工具,它可以帮助理解MySQL如何执行特定的查询。它显示了MySQL执行查询的详细信息,包括如何连接表以及连接的顺序,是否使用了索引,以及每个表的读取行数等。通过这些信息,你可以判断查询性能瓶颈,并对查询或表结构进行相应的优化。
使用EXPLAIN的常见列解释:
?id:查询的标识符,如果是复杂查询,会有多个id,数字越大,优先级越高。
?select_type:查询的类型,比如SIMPLE(简单的SELECT查询),SUBQUERY(子查询中的第一个SELECT),DERIVED(派生表的SELECT)等。
?table:显示这一行的数据是来自哪个表的。
?partitions:如果查询涉及分区表,这一列显示分区的信息。
?type:显示连接类型,这是MySQL如何查找表中行的重要信息。性能由高到低排列 system > const > eq_ref > ref > ref_or_null > index_merge > range > index > ALL
?possible_keys:显示MySQL可能使用哪些索引来优化查询。
?key:实际使用的索引。如果没有使用索引,值是NULL。
?key_len:使用的索引的长度。较短的索引通常更优,因为它们占用更少的空间。
?ref:显示索引查找使用了哪些列或者常量。
?rows:MySQL预估的返回请求数据需要扫描的行数。
?filtered:表示返回结果的行数占扫描行数的百分比。
?Extra:包含不适合在其他列中显示的额外信息,如“Using index”表示表示查询能够使用一个覆盖索引(Covering Index)来获取数据。
使用EXPLAIN的例子:
假设我们有一个简单的查询:
EXPLAIN SELECT * FROM users WHERE name ='zhangsan';
这将返回一个表,显示上面提到的各种列的信息。如果你看到type列是ALL,这意味着MySQL正在进行全表扫描。如果possible_keys列指出了可以使用的索引,而key列是NULL,这意味着MySQL没有使用索引,这就是创建索引或者优化语句来提升查询速度的一个机会。
如何基于EXPLAIN的结果进行优化:
1.避免全表扫描:如果type列是ALL,考虑添加索引来减少扫描的行数。
2.使用正确的索引:possible_keys和key列可以帮助你知道可能使用哪些索引以及实际使用了哪些索引。如果没有使用索引,或者使用了不正确的索引,你可能需要重新考虑索引策略。
3.索引覆盖扫描:如果Extra列包含“Using index”,这意味着查询可以仅通过索引来获取数据,这通常是性能最好的查询之一。
4.优化子查询:如果select_type是SUBQUERY,你可能需要优化子查询。
5.减少读取的行数:rows列告诉你MySQL预计要扫描多少行来执行查询。减少这个数字通常会提高查询性能。
通过深入理解EXPLAIN的输出并据此进行调整索引和语句,可以显著提高查询的性能。不过需要注意的是EXPLAIN只是预测查询执行计划,并不总是100%准确,实际执行时可能会有所不同。因此,优化是一个迭代的过程,需要结合实际的查询执行结果来进行。
第一章:索引 - 数据库的速度之翼
想象一下,你是一个图书管理员,面前摆着成千上万的书籍,但是没有任何目录或索引,你要如何找到想要的书籍呢。这就是没有索引的数据库的真实写照。索引是优化查询的第一步,它能够让数据库引擎像猎鹰一样迅速地找到它的猎物——也就是你需要的数据。
1.1 索引的创建与运用
我们需要在经常参与查询的列上创建索引:
CREATE INDEX idx_column ON table_name(column_name);
1.2 索引的选择与剪枝
索引也并不是越多越好,再美味的食物,吃太多也会消化不良。每个额外的索引都会增加数据插入和更新时的负担,并且有些索引会干扰到数据库对选择索引的判断,导致查询变慢。所以,选择正确的索引和定期“剪枝”不必要的索引是至关重要的。
以下几种情况都是不合适建立索引的:
1.在WHERE条件中用不到的字段不需要索引
2.列里基本上都是重复数据的最好不要创建索引,比如逻辑删除字段deleted,只有0或1两个值
3.已经创建了联合索引的情况下基本不需要再单独创建索引
正好在近几天的优化中碰到了类似的问题:
在workflow表中有联合索引idx_status_type(status, apply_type)和索引idx_remind_deploy(has_remind_deploy)
我们可以看到这个下面这个sql完全达不到预期,简单的查询时间却来到308ms

用explain看一下执行计划:可以看到,这里数据库选择的index_merge这种方式,而表里的has_remind_deploy只有0和1两个值,导致效率反而比只用idx_status_type降低

此时,考虑去掉索引idx_remind_deploy,强制索引idx_status_type后,果然速度变快
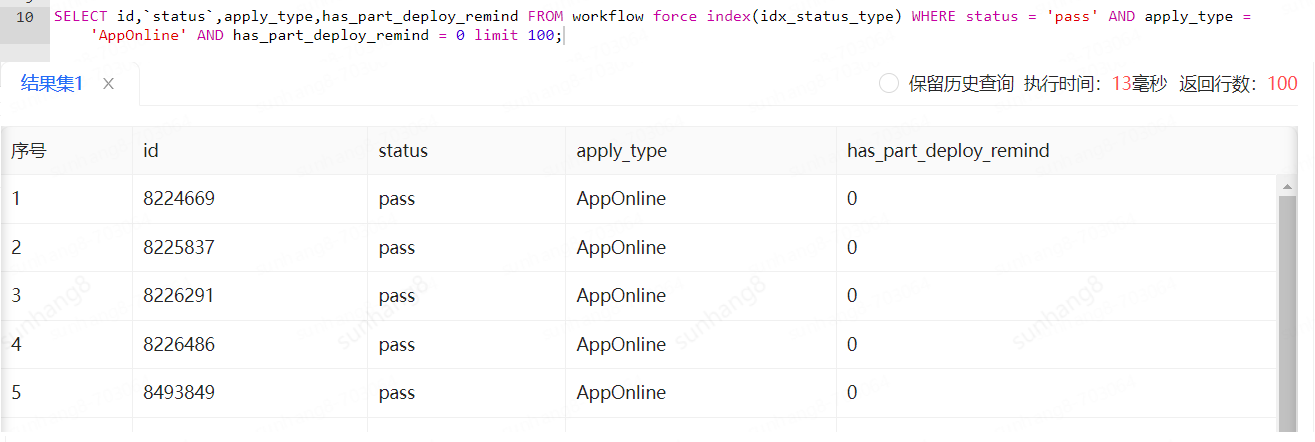
再看一下执行计划,type成为了ref。查询资料发现:index_merge查询时,当一个索引包含大量重复的值时,MySQL需要合并更多的行,这可能导致大量的随机I/O操作,因为它需要从不同的索引中检索和合并行。这种随机I/O通常比连续的I/O(如单个索引扫描)更慢

1.3 联合索引:如何实现1+1>2
当查询中需要根据两个或更多的列来检索数据时,联合索引显得尤为重要。它可以让数据库在多个列上同时进行高效的查找。注意,联合索引的第一项无需再单独建立索引:
CREATE INDEX idx_column1_column2 ON your_table (column1, column2);
联合索引需要注意:联合索引一般遵循最左匹配原则,例如
CREATE INDEX idx_sys_app_group ON groups (system_name, app_name, group_name);
#优化前 963ms
select * from groups where app_name = 'testApp' and group_name = 'testGroup';
#优化后 42ms
select * from groups where system_name= 'test' and app_name = 'testApp' and group_name = 'testGroup';
由此可以看出,当查询group_name时,必须带上联合索引的前两个列一起查询,也就是最左匹配原则,如果直接从联合索引的第二个字段开始查询的话,可能会走全表扫描,要小心这种1+1<2的情况
想要避免这种情况的话,不使用SELECT * 或许是一个不错的方法:
使用SELECT * 时,可以看到,查询走的全表扫描

如果只用app_name和group_name这俩创建了联合索引的列进行查询的话,就可以走索引啦!

第二章:查询重写 - 用巧妙的笔触画出高效SQL
2.1 别让数据库“吃撑”:告别SELECT *,享受轻盈查询
在日常写代码的途中最好能够避免使用SELECT *,在餐厅点餐时,我们也不会把菜单上的菜都来一份,使用SELECT *就像是点了一份满汉全席,而你却只想吃其中几道。请明确告诉数据库你需要的数据,以减轻它的负担。
如果表数据量很大,又需要查所有数据的情况下,可以先查出对应数据的主键id列表,再根据id列表查询;
2.2 给 GROUP BY 和 ORDER BY 减负
在使用GROUP BY或ORDER BY时,请先确保涉及的列已经建立索引。此外,避免在其中使用复杂的表达式或函数,会影响查询速度。
#优化前 1840ms
SELECT app_name,group_name,COUNT(*) FROM groups GROUP BY CONCAT(app_name,'-',group_name);
#优化后 42ms
SELECT app_name,group_name,COUNT(*) FROM groups GROUP BY app_name,group_name;
在使用group by分组时,最好先用where条件过滤掉不需要的数据后再分组,而不是分组后再用having筛选
#优化前 431ms
select * from groups group by app_name having app_name like 'jdos%';
#优化后 122ms
select * from groups where app_name like 'jdos%' group by app_name;
2.3 大分页查询的优化:赢在起跑线上
在处理大分页查询时,使用传统的LIMIT OFFSET方法会先扫描offset+limit行,然后再丢弃掉前offset行,再返回需要的limit行数据。而基于游标的分页则是将起跑线置于终点附近,通过使用上一页最后一条记录的ID来避免OFFSET,可以大幅提高分页的效率,不过这种方式只适合滚动加载或者迭代查询的情况,在需要跳页查询的情况下基本不太能使用。
#优化前 563ms
SELECT * from groups order by id limit 300000,100;
#优化后 78ms
SELECT * from groups where id > 976797 order by id limit 100;
对于需要跳页的大分页的数据,考虑不用一次查出所有数据,可以先查出主键id,再根据id列表查询详情
#优化后 72ms
SELECT id from groups order by id limit 300000,100;
2.4 EXPLAIN的妙用,分析sql执行计划,选择最佳索引
明明app_name和wf_version都有索引,数据量也不是很大,为啥执行时间这么慢呢

用explain看下执行计划,发现用到了wf_version索引,但是由于需要判空会扫描572353行

优化一下sql语句,使索引能够走到app_name,查询速度来到了50ms

再看下查询计划,发现走app_name索引的话只需要扫描289行就可以了

查询的时候,最好能让索引落在能够筛掉最多数据的列上
2.5 JOIN和IN怎么都不走索引?编码集搞的鬼
不知道大家有没有遇到过join或者in的查询,明明应该走索引的情况下,数据库却一直宁愿全表扫描也不走索引,正好最近排查了一个类似问题,在这里分享一下。
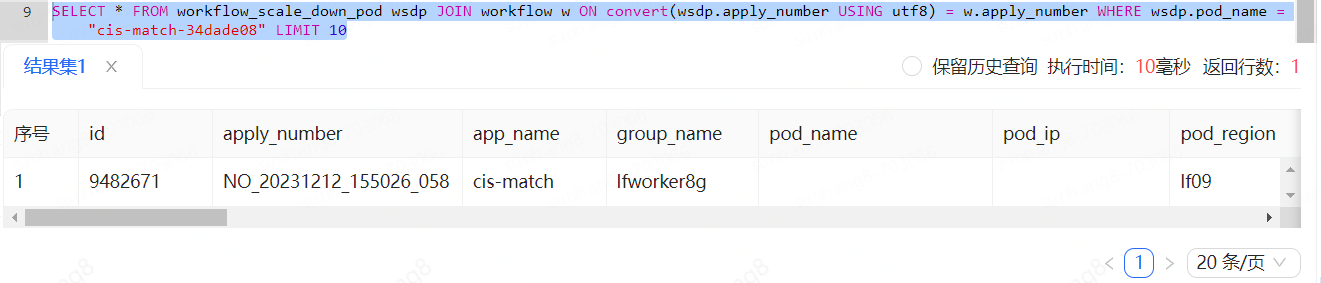
下面的查询中,workflow和workflow_scale_down_pod表中都有apply_number这个索引,关联查询的时候明明只返回一条数据速度却非常慢,这里选择join查询进行演示,可以看到,在两表都有索引的情况下只返回一条数据也耗时1900ms

于是分析一下执行计划,发现右表workflow根本没走索引!甚至用上强制索引也不选择索引:

难道是mysql又在抽什么风了?更改语句,用apply_number筛选右表,强制走索引,发现扫描行数也大有问题,明明左表中只有一条数据,右表却扫描了771034行,能看出来只有like的部分走了索引

后面经过一段时间查找资料发现可能是编码集问题导致索引失效,于是排查两表的编码集,发现确实不一样,workflow用的是utf8而workflow_scale_down_pod用的是utf8mb4

转换一下编码后再join,分析一下执行计划,看样子终于对了

执行一下看看所需时间,发现来到了9ms,真是可喜可贺
2.6 VARCHAR类型不走索引
与2.5类似,在表字段为varchar类型,存储的数据是数字时,直接用int类型查也会导致不走索引,需要加上引号用String类型来查询
第三章:数据库设计 - 优化的基石
上面我们说完了查询方面的优化,接下来说一下对表整体的优化。设想你的数据库表是一座精心设计的高效工厂,每个表都是一个生产线,它们的设计直接影响着整个工厂的产出效率。垂直分表和水平分表是两种让生产线更高效的设计策略。
3.1 垂直分表:各司其职
垂直分表就像是对工厂的生产线进行专业化改造,将一个多功能生产线拆分成几个高度专业化的小团队,每个团队都只负责一部分任务。这样可以减少每次查询加载的数据量,从而提高效率。举个常用的例子:概览表和详情表,一般情况下用户只需要知道概览就可以了,当需要看某一条数据的具体情况时,再通过概览关联的详情id单独去查详情表
-- 原始表
CREATE TABLE task (
id INT,
name VARCHAR(100),
operator VARCHAR(64),
detail VARCHAR(2000)
);
-- 垂直分表
CREATE TABLE task (
id INT,
name VARCHAR(100),
operator VARCHAR(64),
detail_id INT
);
CREATE TABLE task_detail (
id INT,
detail VARCHAR(2000)
);
3.2 水平分表:各得其所
水平分表,像是将一个超负荷的生产线拆分成几个并行的小生产线,每条线都在做相同的事情,但只处理一部分产品。这样可以大大减轻每条生产线的压力,提高整体的处理能力。根据一定的规则将原表拆成几个表结构相同的表,查询时根据一定的路由规则分配到对应的表里,让每个表的数据都不会过于臃肿
-- 原始表
CREATE TABLE task (
id INT,
name VARCHAR(100),
operator VARCHAR(64),
detail VARCHAR(2000)
);
-- 水平分表 按年份分表
CREATE TABLE task_2022 (
id INT,
name VARCHAR(100),
operator VARCHAR(64),
detail VARCHAR(2000)
);
CREATE TABLE task_2023 (
id INT,
name VARCHAR(100),
operator VARCHAR(64),
detail VARCHAR(2000)
);
3.3 数据归档:轻装前行
数据归档和水平分表类似,是将基本不可能用到的数据移到备份表中,对数据库来一次“断舍离”。举个例子:现在数据库表删除数据时基本上都是逻辑删除,当表里的数据非常多,而且被删除的数据和还存在的数据差不多的时候,就可以考虑将逻辑删除的数据移到备份表中,这样不仅缩小了表的数据量,还可以在查询的时候去掉对逻辑删除字段的筛选,查询更快人一步。
结语:持续的优化之路
优化SQL查询是一个动态且持续的过程,它要求我们不断地进行监控、评估和调整。每一次微小的调优都有可能使数据库的查询速度显著提升。现在,你已经了解了优化的相关知识,准备好了吗?是时候启动引擎,让你的数据库和行云部署一样起飞了!
讨论:欢迎分享
大家在SQL优化方面还遇到过哪些有趣或棘手的场景呢?请在评论区畅所欲言,让我们一起学习、探讨和解决这些问题。相信大家的经验会为大家带来启发和帮助,让我们共同进步,成为SQL优化的高手!
同时,如果你有任何关于数据库优化的问题,也可以在评论区提问,我们也会尽力为大家解答。让我们互相学习,共创美好未来!
作者:京东科技 孙航
来源:京东云开发者社区 转载请注明来源
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Nginx 可视化神器!
- 移动神器RAX3000M路由器变身家庭云之二:安装vsftpd
- 你好,C++(4)2.1.3 我的父亲母亲:编译器和链接器 2.1.4 C++程序执行背后的故事
- 遭遇[[MyFile@waifu.club]].wis勒索病毒?了解[[MyFile@waifu.club]].wis病毒及其解决方案
- (二十三)MySQL分表篇:该如何将月增上亿条数据的单表处理方案优雅落地?
- mysql数据库的SQL语句详解
- 面试常见知识点--树的遍历
- Linux shell编程学习笔记39:df命令
- vue中的防抖和节流
- 【UE5.1】程序化生成Nanite植被