SparkSQL——DataFrame
发布时间:2024年01月17日
DataFrame
-
Dataframe 是什么
DataFrame是SparkSQL中一个表示关系型数据库中表的函数式抽象, 其作用是让Spark处理大规模结构化数据的时候更加容易. 一般DataFrame可以处理结构化的数据, 或者是半结构化的数据, 因为这两类数据中都可以获取到Schema信息. 也就是说DataFrame中有Schema信息, 可以像操作表一样操作DataFrame.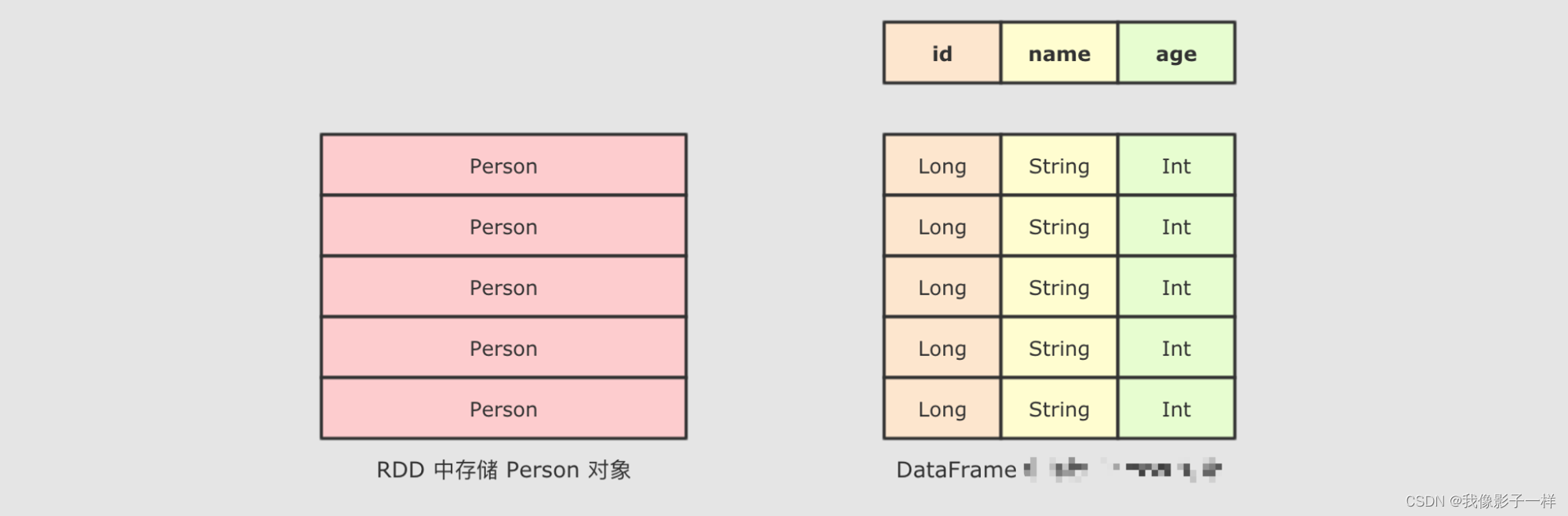
DataFrame由两部分构成, 一是row的集合, 每个row对象表示一个行, 二是描述DataFrame结构的Schema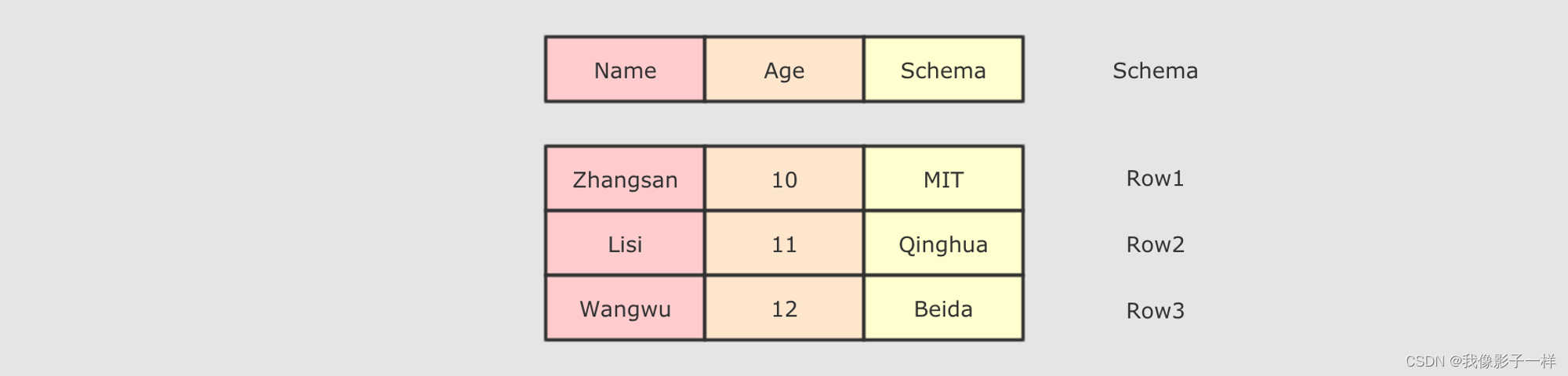
DataFrame支持SQL中常见的操作, 例如:select,filter,join,group,sort,join等- code
@Test def dataframe1(): Unit = { // 1. 创建 SparkSession 对象 val spark = SparkSession.builder() .master("local[6]") .appName("dataframe1") .getOrCreate() // 2. 创建 DataFrame import spark.implicits._ val dataFrame: DataFrame = Seq(Person("zhangsan", 15), Person("lisi", 20)).toDF() // 3. 看看 DataFrame 可以玩出什么什么花样 // select name from t where t.age >10 dataFrame.where('age > 10) .select( 'name) .show() } case class Person(name: String, age: Int)
-
DataFrame 如何创建
DataFrame如何创建数据集【BeijingPM20100101_20151231_noheader.rar】
@Test def dataframe2():Unit = { val spark = SparkSession.builder() .master("local[6]") .appName("dataframe2") .getOrCreate() import spark.implicits._ val personList = Seq(Person("zhangsan", 15), Person("lisi", 20)) // 创建 DataFrame 的方法 // 1.toDF val df1 = personList.toDF() val df2 = spark.sparkContext.parallelize(personList).toDF() // RDD.toDf() // 2. createDatFrame val df3 = spark.createDataset(personList) // 3. read val df4 = spark.read.csv("./dataset/BeijingPM20100101_20151231_noheader.csv") df4.show() } case class Person(name: String, age: Int)

-
DataFrame 操作 (案例)
DataFrame操作数据集[BeijingPM20100101_20151231.rar]
需求:查看 PM_Dongsi 每个月的统计数量
object DataFrameTest { def main(args: Array[String]): Unit = { // 1. 创建SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("pm_analysis") .getOrCreate() import spark.implicits._ // 2. 读取数据集 val sourceDF = spark.read .option("header",true) // 把表头读取出来 .csv("./dataset/BeijingPM20100101_20151231.csv") //sourceDF.show() //查看DataFrame 的 schema 信息,要意识到 DataFrame 中是有结构信息的,叫做Schema sourceDF.printSchema() // 3. 处理 // 1. 选择列 // 2. 过滤 NA 的 PM记录 // 3. 分组 select year, month, count(PM_Dongsi) from .. where PM_Dongsi != NA group by year, month // 4. 聚合 // 4. 得出结论 sourceDF.select('year,'month,'PM_Dongsi) .where('PM_Dongsi =!= "NA") // 过滤 NA 的 PM记录 .groupBy('year,'month) .count() .show() // action // 是否能支持使用 SQL 语句进行查询 println("---------接下来是SQL语句查询的--------------") // 1. 将 DataFrame 注册为临时表 sourceDF.createOrReplaceTempView("pm") // 2. 执行查询 val resultDF = spark.sql("select year, month, count(PM_Dongsi) from pm where PM_Dongsi != 'NA' group by year,month") resultDF.show() spark.stop() } }
总结
- DataFrame 是一个类似于关系型数据库表的函数式组件
- DataFrame 一般处理结构化数据和半结构化数据
- DataFrame 具有数据对象的 Schema 信息
- 可以使用命令式的 API 操作 DataFrame, 同时也可以使用 SQL 操作 DataFrame
- DataFrame 可以由一个已经存在的集合直接创建, 也可以读取外部的数据源来创建
小Tips
一般处理数据都差不多是ETL这个步骤
- E -> 抽取
- T -> 处理转换
- L -> 装载,落地
Spark代码编写的套路:
- 创建DataFrame Dataset RDD,制造或者读取数据
- 通过DataFrame Dataset RDD的API来进行数据处理
- 通过DataFrame Dataset RDD进行数据落地
文章来源:https://blog.csdn.net/m0_56181660/article/details/135637206
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Web3社交治理:用户参与决策的新模式
- LVS-DR模式部署
- 为什么需要在bean上使用@EqualsAndHashCode(callSuper = true)这个注解
- SOLIDWORKS CSWA考试说明
- 三年Java开发的技术职业规划
- TSINGSEE视频智能解决方案边缘AI智能与后端智能分析的区别与应用
- 第五章[列表]:5.7:列表排序
- 计算机毕设论文|基于网络超市商品销售管理系统的设计与实现
- 物理服务器的价位 如何选择性价比更高
- JAVA的面试题四