影像组学介绍
影像组学介绍
1 影像组学介绍
其实就是想把图像处理领域的知识点,应用到医学图像里面。当初影像组学方法是,现在人工智能方法也是。
随着精准定量医学影像技术的快速发展、图像识别技术和数据算法的不断更新,医学图像大数据的挖掘和分析得以实现,极大程度扩展了医学图像的信息量。基于对图像信息进行纹理分析后能够得到高通量的特征的特点,受基因组学以及肿瘤异质性的启发,2012年荷兰学者Lambin在先前学者工作的基础上提出了**影像组学(Radiomics) **的概念[1]。
Radiomics: Extracting more information from medical images using advanced feature analysis

Lambin认为“高通量地从医学影像中提取大量特征,通过自动或半自动分析方法将影像学数据转化为具有高分辨率的可挖掘数据空间”医学影像可以全面、无创、定量地观察肿瘤的空间和时间异质性。Kumar等[3]又对影像组学的定义进行了拓展,**影像组学是指从CT、PET或MRI等医学影像图像中高通量地提取并分析大量高级且定量的影像学特征。**这个理念的提出在随后的七年迅速被越来越多的学者改进与完善。
影像组学,一共4个常见字。但4个字加在一起是啥意思?好吧,拆成“影像”和“组学”两个词来说。“影像”通常指的就是放射影像,主要包括了CT、MR影像,当然,现在也陆续有加入了PET、US影像研究。组学(Omics),专门百度了一下,通俗理解就是把与研究目标相关的所有因素综合在一起作为一个“系统”来研究。目前主要包括基因组学(Genomics),蛋白组学Proteinomics,代谢组学(Metabolomics),转录组学(transcriptomics),免疫组学(Immunomics),RNA组学(RNomics),影像组学(Radiomics)等。
影像组学流程:
影像组学本质上来说其实是一种分析思路方法,从临床问题出发,最后回到解决的临床问题。一般分为五个主要处理步骤:
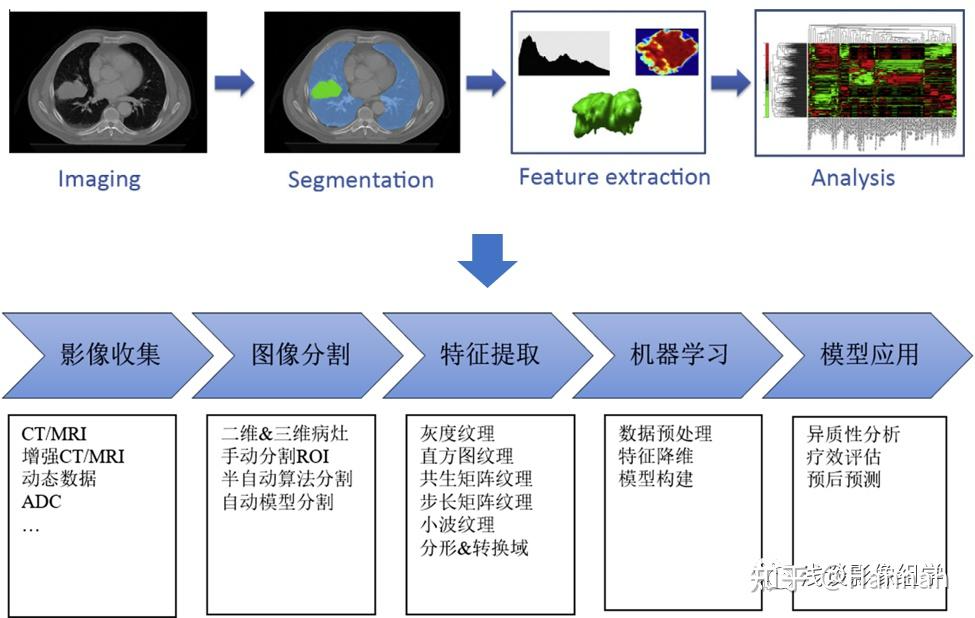
- 标准医学影像数据获取和筛选:数据收集前,首先需要根据明确的研究方向进行数据筛选,例如做肿瘤分型或肺炎分型的鉴别诊断,所选影像数据是否有病理或病原学检测金标准进行对照;做影像学疗效评估时,是否具有多期治疗相应的影像资料匹配等。
- 图像分割:指将图像分成若干个特定、具备独特属性的区域并提取感兴趣目标的技术和过程。根据研究目的的不同,图像分割的目标可以是病灶、正常参考组织或是组织解剖结构,可以是三维也可以是二维区域,影像组学随后的分析研究都围绕这些从图像内分割出来的区域进行。
- 特征提取:影像组学的核心步骤就是提取高通量的特征来定量分析ROI的实质属性。基于Image Biomarker Standardization Initiative (IBSI)标准[4]统计划分,常将影像组学特征分为形状特征(Shape features)、一阶统计学特征(First order statistics features)、纹理特征 (texture-basedfeatures)、高阶特征(high-order features)以及基于模型转换的特征。
- 机器学习:特征选择,上述通过特征提取,提取到的特征数量可能有几百到几万不等,而并不是每一个特征都与要解决的临床问题相关联;另一方面,在实践中,由于特征数量相对较多,而样本数量较少,容易导致随后的模型出现过拟合的现象,从而影响模型的准确率。特征选择是根据某些评估准则,从特征集中直接选取合适的子集,或者将原有的特征经过线性/非线性组合,生成新的特征集,再从新特征集中选取合适的子集过程。
- 模型应用:针对医生具体的临床问题,在临床研究问题标签的基础上建立由上述特征筛选出来的关键特征,或进一步结合影像组学以外的特征(如临床体征、病理、基因检测数据)组合而成的预测模型。
2 具体提取影像组学方法流程及工具代码:
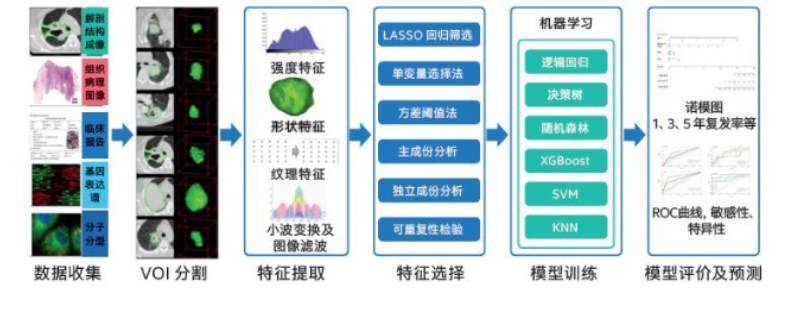
具体影像组学的流程如下:
1,影像数据准备
2,感兴趣区域分割
3,特征提取与特征选择
4,建模分析
5,结果展示
2.1 影像数据获取
不同设备厂商、同一厂商不同型号的影像设备在图像扫描和重建协议上往往存在着很大的差异,迄今为止仍然缺乏统一的采集标准规范。这就可能给包含影像组学在内的众多医工结合项目造成了潜在的影响。尽管对数据存储传输、图像勾画和算法运行速度带来诸多不便,但为了最后的建模评估步骤能达到更好的效果,仍然推荐入组分辨率更高、信息量更为丰富的薄层数据。这些数据最好具有相同(或相近)的采集参数,以尽可能降低数据质量被各种成像因素的干扰。目前,国内很多医院都开展过肿瘤的影像组学相关项目,比如肺癌、肝癌、结直肠癌等等。但随着组学科研在全国乃至世界范围内发生“内卷化”,课题总数据量和多中心研究都已经成为审稿中的决定性因素。这时,在繁杂的医院数据中,既要严控数据入组条件,同时也要满足项目所需的样本数量,只有兼顾两者才可能取得最优的效果。
此外,多模态影像组学时代的开启给医工两方面的研究者都提出了更大的挑战。数据量的成倍增加、算法工程师的影像专业背景,都可能成为项目推进的阻力。这里有非常重要的一点,要求影像医生做好数据筛选:所有的影像医工交叉项目,数据量的一大原则都是“贵精不贵多”——除了保留与病灶相关的必要序列外,不要有任何冗余的图像,否则会成为后续工作中非常不利的因素。至于质量不过关(如包含伪影、扫描序列不完整)、缺乏完整临床指标的样本,都是应该被排除在项目之外。
当然,你如果没有私有数据集的话,也有一些比赛公开了数据集。或者你可以用公开数据集做泛化性分析:
如:https://github.com/linhandev/dataset
这个项目地址公开了很多医学影像数据集:
2.2 感兴趣区域分割
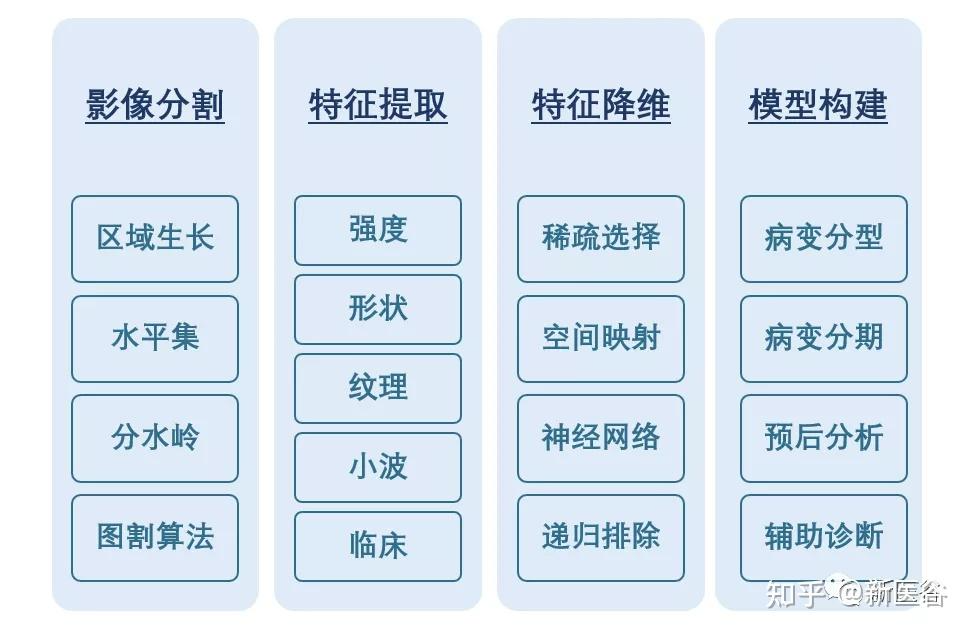
影像准备完毕,接下来的重要步骤是病灶ROI的勾画,从而对照影像序列,进一步开展后续的特征提取。医学图像分割经过几十年的发展,目前仍然保持了两大类别:手动/半自动分割,以及全自动分割。
由于病灶的特质性和不规则性,手动/半自动分割仍然是现有条件下的最佳选择,即使手动分割耗时较大,它仍然是金标准获取的唯一途径。课题中既可以采用3D Slicer、ITK-SNAP等传统分割软件,也可以尝试像Pair等新兴工具,甚至可以使用工作站日常诊断中的三维重建结果。全自动分割算法包括阈值/区域生长、分水岭、水平集等,也有近年来非常火热的深度学习算法。
但很遗憾,尽管学术界和工业界都付出了相当大的努力,但迄今为止,仍然没有高精度、全自动的通用分割模型可以完美地应用于影像科研的日常流程和基础IT架构中,自动分割后ROI还是要医生手动调整确认以保证项目的精度效果。
如果当你面对大量数据集的标注时,你可以使用半自动+人工检验的方式进行金标准的制作。
或者你使用公开数据集的话,公开数据集本身就有分割标注,也不用你进行分割了。
2.3 特征提取与降维选择
2.3.1 特征提取:
影像组学特征由一系列传统图像特征的合集构成,既包含了一阶梯度特征(区域内统计信息)、形状特征(如形态学参数、圆形度等)、纹理特征(灰度共生矩阵、灰度区域大小矩阵、灰度游程矩阵),也包含了各种图形滤波变换后的特征,比如高斯-拉普拉斯变换、小波变换、平方根滤波等。这些特征都曾经在医学图像分析中有过较为成功的运用,而影像组学正是把高阶的图像特征聚集在一起、进一步提高分析结果质量的方法。每个影像组学特征都有着独立的计算公式,现在在网上已经可以找到丰富的特征提取工具直接调用,而无需自行学习理解公式、手动编程计算。
时下流行的时是PyRadiomics组学工具包。使用起来方便快捷,而且是基于python。

PyRadiomics的官方文档:https://pyradiomics.readthedocs.io/en/latest/
具体使用代码可以参考:
【使用pyradiomics提取影像组学特征【详细】】
https://blog.csdn.net/weixin_46428351/article/details/123592586
2.3.2 特征降维(特征选择)
面对大量的特征,我们不可能对其直接进行模型构建,我们需要对数据进行降维,给数据“瘦身”,从成千上万的特征数据中获取最为有价值的特征数据。
提取完毕的影像组学特征,少则成百上千;有些“噱头”概念也会在多模态+各种图像预处理后形成高达十万数量级的特征维度;目前还有一种流行的方法是将组学特征和临床数据相互结合,以便最大化综合各种层面的信息优势。这个时候就需要采用一些特征降维和筛选的手段来对特征数目进行一定的限制,避免冗余数据影响机器学习模型的精确和稳定性。
常见的降维和筛选方法有主成分分析、相关性分析以及基于L1惩罚项的特征选择法等——其实当维度达到一定级别的时候,再增加特征对最终的结果影响已经降到很低,反而严重增加了完成组学流程的时间和空间复杂度。
2.4 建模分析:
课题中需要将样本分为训练集和测试集(遵循着7:3或8:2的原则),如果是多中心课题,可以根据不同医院区分样本,以其它医院的数据做外部验证的测试集,评价建模的鲁棒性。
建模时首先使用训练集,通过学习一个函数,找到各类样本的最佳区分“界面”。常用的分类器包括了决策树、逻辑回归、随机森林、支持向量机(SVM)等。在建模过程中,为了减少过拟合和选择偏差、保证更好的模型性能,常常会引入交叉验证(Cross Validation)的方法。交叉验证将数据的训练集样本切割成若干较小子集,然后先在一个子集上做分析,而其它子集则用来做后续对此分析的验证,并确定一些模型的参数。
2.5 结果分析
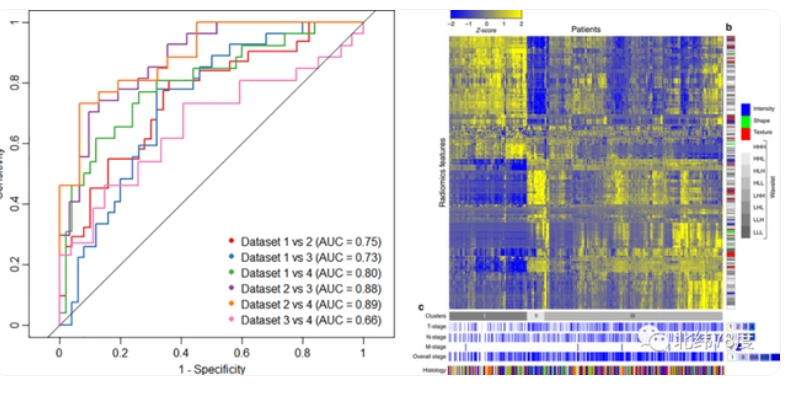
模型训练完毕后,再采用测试集进行组学预测结果和临床标签的对比,进行性能评估。常用于展现影像组学结果的图或数值有ROC曲线、(95%置信区间下的)AUC值、敏感度、特异度、特征贡献度、相关系数热图等。
参考:
【影像组学初学者指南】
https://zhuanlan.zhihu.com/p/462293882
【组学浅析之通俗理解影像组学的定义】
https://zhuanlan.zhihu.com/p/352750421
【影像组学十周年:技术,应用与展望】
https://baijiahao.baidu.com/s?id=1719918690339298767
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 柏曼、好视力、书客护眼台灯值得入手吗?热门台灯多方位测评对比
- php-fpm运行一段时间,内存不足
- Unity 编辑器篇|(六)编辑器拓展EditorGUI类 (全面总结 | 建议收藏)
- Python+django+selenium搭建简易自动化测试
- novnc的vnc_lite输入框明文处理办法
- QT 文本框的绘制与复选框组键
- 如何在Shopee平台上进行产品选品并提高成功率?
- UnicodeUtil.java
- MATLAB break语句||MATLAB continue语句
- Lazada商品详情API(lazada.item_get)获取商品的图片信息