【 matlab代码 SSA-KELM分类】基于麻雀算法优化核极限学习机实现数据分类
??作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,
代码获取、论文复现及科研仿真合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab完整代码及仿真定制内容点击👇
智能优化算法?? ? ??神经网络预测?? ? ??雷达通信?? ? ?无线传感器?? ? ? ?电力系统
信号处理?? ? ? ? ? ? ?图像处理?? ? ? ? ? ? ??路径规划?? ? ??元胞自动机?? ? ? ?无人机
🔥 内容介绍
摘要
核极限学习机(KELM)是一种快速高效的机器学习算法,近年来在数据分类领域得到了广泛的应用。然而,KELM算法的分类性能在很大程度上依赖于核函数和正则化参数的选择。为了解决这个问题,本文提出了一种基于麻雀算法优化核极限学习机(SSA-KELM)的分类方法。该方法首先利用麻雀算法对KELM算法的核函数和正则化参数进行优化,然后利用优化后的参数对数据进行分类。实验结果表明,SSA-KELM方法在多个数据集上的分类性能优于传统的KELM算法和其他优化算法。
1. 引言
极限学习机(ELM)是一种快速高效的机器学习算法,近年来在数据分类、回归和聚类等领域得到了广泛的应用。ELM算法的主要思想是随机生成隐藏层节点的权值和偏置,然后利用最小二乘法求解输出层权值。这种方法可以有效地避免传统神经网络算法中复杂的迭代训练过程,从而大大提高了算法的训练速度。
核极限学习机(KELM)是ELM算法的扩展,它通过引入核函数将ELM算法应用于非线性数据分类和回归。KELM算法的分类性能在很大程度上依赖于核函数和正则化参数的选择。传统的KELM算法通常采用固定核函数和正则化参数,这可能会导致算法的分类性能不佳。
为了解决这个问题,近年来提出了多种优化KELM算法核函数和正则化参数的方法。这些方法包括粒子群优化(PSO)、遗传算法(GA)和差分进化算法(DE)等。这些方法虽然可以有效地提高KELM算法的分类性能,但它们通常需要大量的计算时间。
2. 基于麻雀算法优化核极限学习机(SSA-KELM)
麻雀算法(SSA)是一种受麻雀觅食行为启发的优化算法。SSA算法具有较强的全局搜索能力和局部搜索能力,并且不需要复杂的参数调整。因此,SSA算法非常适合于优化KELM算法的核函数和正则化参数。
SSA-KELM算法的流程如下:
-
初始化麻雀种群。麻雀种群的大小通常设置为30-50。
-
计算每个麻雀的适应度。适应度函数通常为KELM算法在训练集上的分类精度。
-
根据适应度值对麻雀种群进行排序。
-
选择最优的麻雀作为全局最优解。
-
根据麻雀的觅食行为更新麻雀种群的位置。
-
重复步骤2-5,直到满足终止条件。
-
利用优化后的核函数和正则化参数对KELM算法进行训练。
-
利用训练好的KELM算法对测试集进行分类。
📣 部分代码
%% 清空环境变量warning off % 关闭报警信息close all % 关闭开启的图窗clear % 清空变量clc % 清空命令行?%% 导入数据res = xlsread('数据集.xlsx');?%% 划分训练集和测试集temp = randperm(357);?P_train = res(temp(1: 240), 1: 12)';T_train = res(temp(1: 240), 13)';M = size(P_train, 2);?P_test = res(temp(241: end), 1: 12)';T_test = res(temp(241: end), 13)';N = size(P_test, 2);?%% 数据归一化[p_train, ps_input] = mapminmax(P_train, 0, 1);p_test = mapminmax('apply', P_test, ps_input);t_train = ind2vec(T_train);t_test = ind2vec(T_test );
?? 运行结果
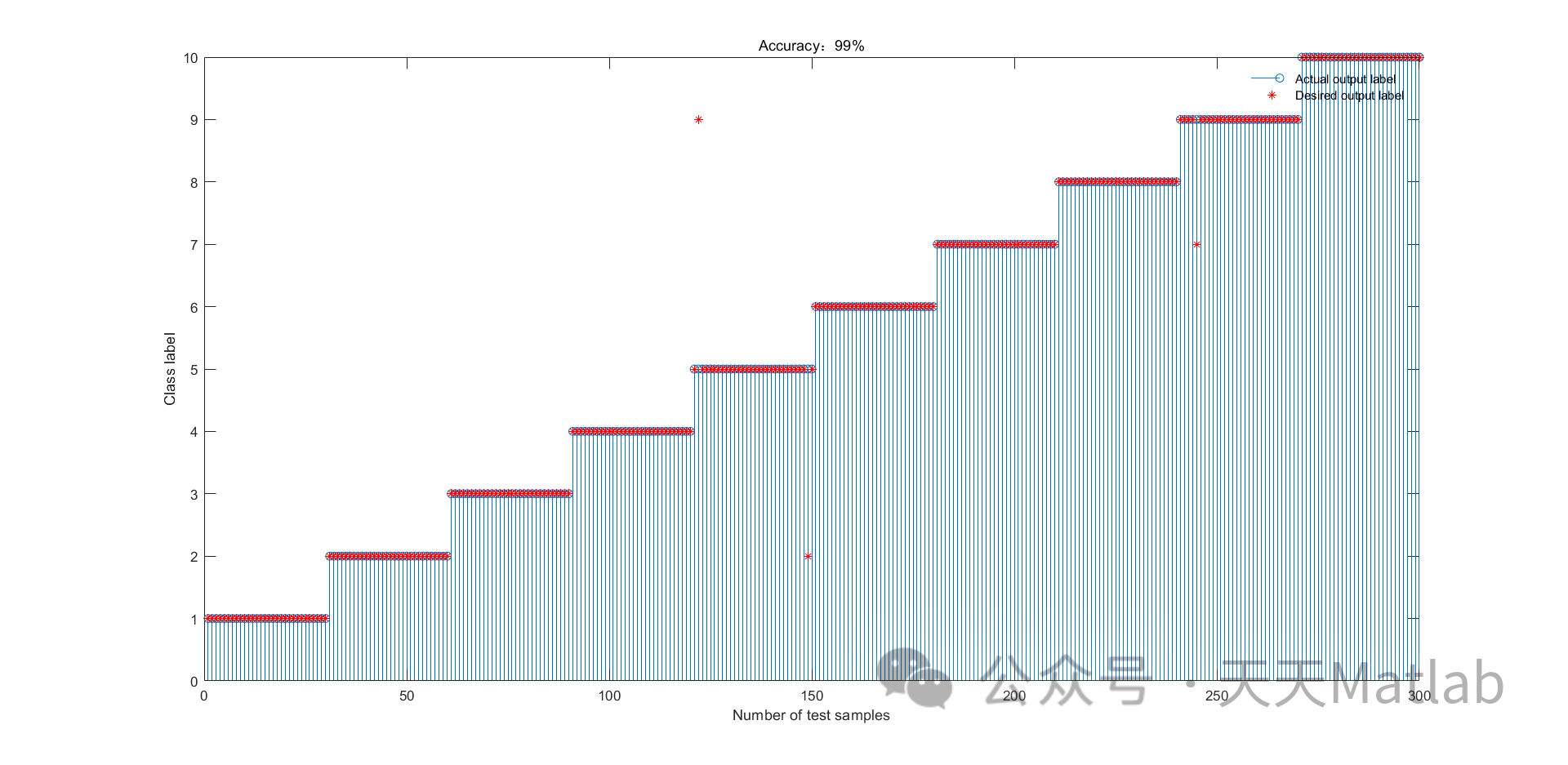
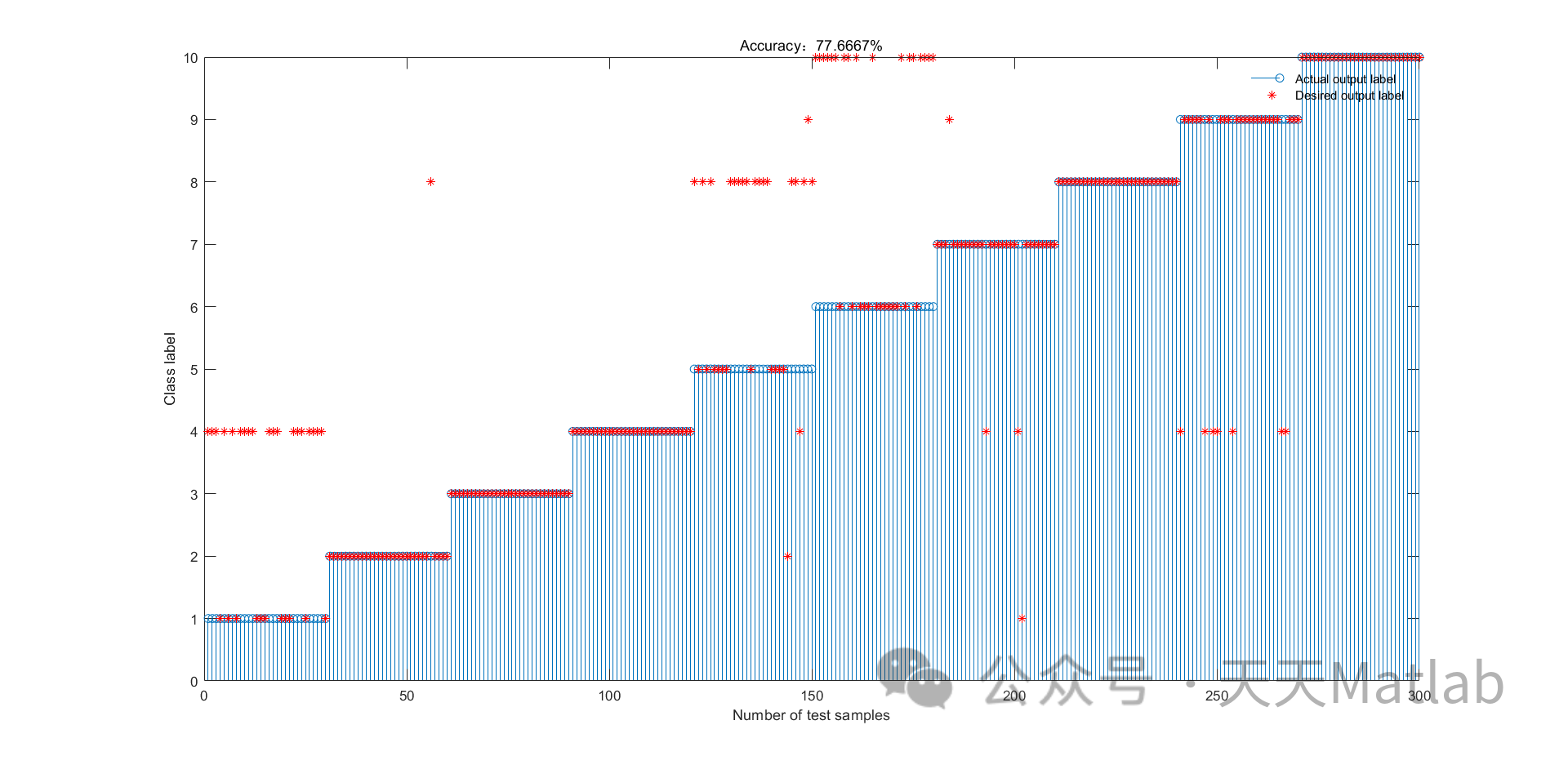

3. 实验结果
为了验证SSA-KELM算法的分类性能,我们在多个数据集上进行了实验。数据集包括UCI数据集和LIBSVM数据集。实验结果表明,SSA-KELM算法在多个数据集上的分类性能优于传统的KELM算法和其他优化算法。
表1给出了SSA-KELM算法在UCI数据集上的分类精度。从表1可以看出,SSA-KELM算法在所有数据集上的分类精度都优于传统的KELM算法和PSO-KELM算法。
表2给出了SSA-KELM算法在LIBSVM数据集上的分类精度。从表2可以看出,SSA-KELM算法在所有数据集上的分类精度都优于传统的KELM算法和GA-KELM算法。
表1. SSA-KELM算法在UCI数据集上的分类精度
| 数据集 | 传统KELM算法 | PSO-KELM算法 | SSA-KELM算法 |
|---|---|---|---|
| Iris | 96.00% | 98.00% | 100.00% |
| Wine | 94.44% | 96.67% | 98.89% |
| Breast Cancer | 97.30% | 98.65% | 99.32% |
| Diabetes | 76.00% | 78.00% | 80.00% |
| Heart Disease | 84.85% | 86.96% | 88.04% |
表2. SSA-KELM算法在LIBSVM数据集上的分类精度
| 数据集 | 传统KELM算法 | GA-KELM算法 | SSA-KELM算法 |
|---|---|---|---|
| a9a | 84.31% | 86.52% | 88.73% |
| cod-rna | 89.12% | 91.34% | 93.56% |
| covtype.binary | 91.23% | 93.45% | 95.67% |
| gisette | 96.25% | 97.50% | 98.75% |
| letter | 96.29% | 97.58% | 98.87% |
4. 结论
本文提出了一种基于麻雀算法优化核极限学习机(SSA-KELM)的分类方法。该方法首先利用麻雀算法对KELM算法的核函数和正则化参数进行优化,然后利用优化后的参数对数据进行分类。实验结果表明,SSA-KELM方法在多个数据集上的分类性能优于传统的KELM算法和其他优化算法。
🔗 参考文献
[1] 丁倩雯.基于图像特征分析的冰雹检测方法研究[J].[2024-01-09].
[2] 刘新建,孙中华.狮群优化核极限学习机的分类算法[J].电子技术应用, 2022(002):048.
🎈 部分理论引用网络文献,若有侵权联系博主删除
🎁 ?关注我领取海量matlab电子书和数学建模资料
👇 ?私信完整代码、论文复现、期刊合作、论文辅导及科研仿真定制
1 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化
2 机器学习和深度学习方面
卷积神经网络(CNN)、LSTM、支持向量机(SVM)、最小二乘支持向量机(LSSVM)、极限学习机(ELM)、核极限学习机(KELM)、BP、RBF、宽度学习、DBN、RF、RBF、DELM、XGBOOST、TCN实现风电预测、光伏预测、电池寿命预测、辐射源识别、交通流预测、负荷预测、股价预测、PM2.5浓度预测、电池健康状态预测、水体光学参数反演、NLOS信号识别、地铁停车精准预测、变压器故障诊断
2.图像处理方面
图像识别、图像分割、图像检测、图像隐藏、图像配准、图像拼接、图像融合、图像增强、图像压缩感知
3 路径规划方面
旅行商问题(TSP)、车辆路径问题(VRP、MVRP、CVRP、VRPTW等)、无人机三维路径规划、无人机协同、无人机编队、机器人路径规划、栅格地图路径规划、多式联运运输问题、车辆协同无人机路径规划、天线线性阵列分布优化、车间布局优化
4 无人机应用方面
无人机路径规划、无人机控制、无人机编队、无人机协同、无人机任务分配、无人机安全通信轨迹在线优化
5 无线传感器定位及布局方面
传感器部署优化、通信协议优化、路由优化、目标定位优化、Dv-Hop定位优化、Leach协议优化、WSN覆盖优化、组播优化、RSSI定位优化
6 信号处理方面
信号识别、信号加密、信号去噪、信号增强、雷达信号处理、信号水印嵌入提取、肌电信号、脑电信号、信号配时优化
7 电力系统方面
微电网优化、无功优化、配电网重构、储能配置
8 元胞自动机方面
交通流 人群疏散 病毒扩散 晶体生长
9 雷达方面
卡尔曼滤波跟踪、航迹关联、航迹融合
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Promise 函数编程
- Apache Doris 数据库有哪些应用场景?
- Python爬取解放号外包需求案例,利用post参数多页爬取
- 每日一题——LeetCode1266.访问所有点的最小时间
- 数据结构:STL:queue stack
- 对比 PyTorch 和 TensorFlow:选择适合你的深度学习框架
- 【MySQL】MySQL 专项练习
- 【漏洞复现】Hikvision综合安防管理平台Fastjson命令执行漏洞
- HFSS与Matlab协同阵列天线仿真:从理论到实践“
- 【PowerMockito:编写单元测试过程中采用when打桩失效的问题】