【ElasticSearch】 ElasticSearch serverless架构介绍(查询写入分离,计算存储分离)
ElasticSearch 推出了全新的serverless架构,将查询(search)和写入(indexing)分离,将计算(computing)和存储(storage)分离,极大提高了 ES 的可运维性,降低了学习成本。本文将先介绍下serverless含义,再介绍ElasticSearch serverless架构。
serverless介绍
在serverless架构下,用户只需关注业务逻辑,无需管理服务器,云提供商负责置备、维护和扩展服务器基础架构等例行工作,云提供商对用户进行按量计费。
Serverless 的定义
Serverless 不如 IaaS 和 PaaS 那么好理解,因为它通常包含了两个领域 BaaS(Backend as a Service)和 FaaS(Function as a Service)。
BaaS
BaaS(Backend as a Service)后端即服务,一般是一个个的 API 调用后端或别人已经实现好的程序逻辑,比如身份验证服务 Auth0,这些 BaaS 通常会用来管理数据,还有很多公有云上提供的我们常用的开源软件的商用服务,比如亚马逊的 RDS 可以替代我们自己部署的 MySQL,还有各种其它数据库和存储服务。
FaaS
FaaS(Functions as a Service)函数即服务。FaaS本质上是一种事件驱动的由消息触发的服务,FaaS供应商一般会集成各种同步和异步的事件源,通过订阅这些事件源,可以突发或者定期的触发函数运行。
优点
-
可运维性:无需管理服务器,比如操作系统的安全补丁升级、故障升级、高可用性,这些云服务(OSS,CDN)都帮着做了;
-
可扩展性:无需对资源做预估和考虑未来的扩展。横向扩展是完全自动的、有弹性的、且由服务提供者所管理
-
成本:按实际使用的资源付费,包括存储费用和请求费用,没有请求时不收取请求费用,通过使用iaas时是申请固定数量的服务器,即使低峰期服务器没有流量,也需要付费;运营成本也会降低,由于这个云服务使用者的数量会非常庞大,于是就会产生规模经济效应;服务的储存和计算被分开部署和收费
-
安全性:这样一个系统甚至看不到服务器,不需要通过 SSH 登录,DDoS 攻击也交给云服务来解决。
缺点
- 影响灵活性,不能做定制化的配置
- 受制于供应商技术锁定。即便您决定要更换提供商,也可能需要升级系统以符合新供应商的规范,而这无疑会增加成本。
问题
用户需要管理集群、配置分片、集群容量管理、配置ILM,这些配置较为复杂,没有专业经验难以配置好。
解决方法
推出elasticsearch新的serverless架构,利用最新的云原生服务,通过无忧管理提供优化的产品体验。它提供数据湖的存储容量,但具有与 Elasticsearch 相同的快速搜索性能,以及无需干预的集群管理和扩展的操作简单性。该架构基于四个关键原则
- 计算和存储解耦
- 单独的搜索层和写入层
- 作为记录系统的廉价对象存储
- 低延迟查询
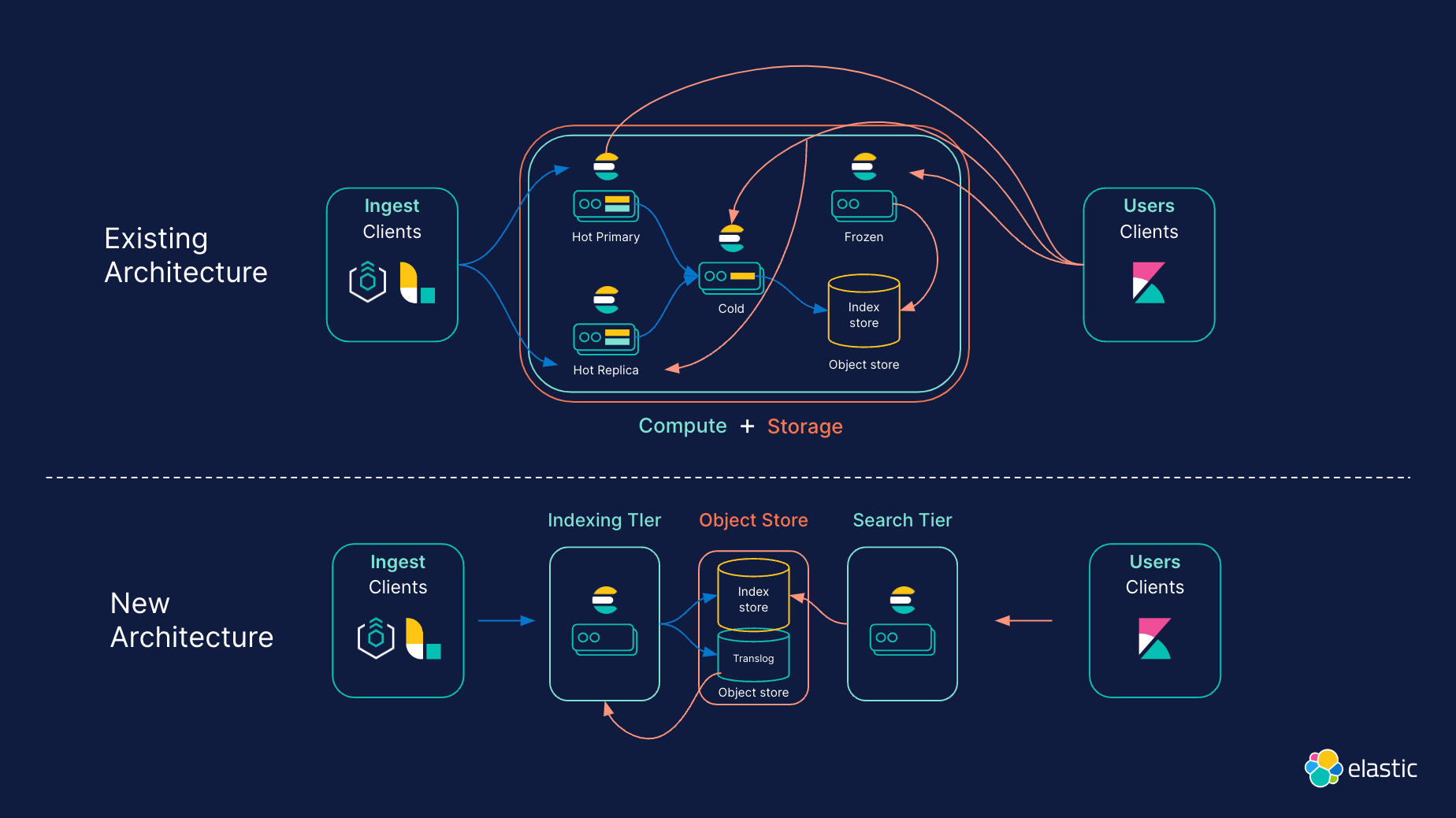
计算存储完全分离
当前数据层分为hot, warm, cold, and frozen,来更好的分配数据给硬件。新架构下不存在这些数据层。并且支持更好的平衡查询效率和存储成本效率,支持快速扩展任何工作负载(我认为是计算(search和indexing)和存储(计算存储)可以分开扩容)
分开indexing层和search层
新架构支持分开indexing层和search层(这和上一点不一样,indexing和search都是计算compute),这意味着不同的工作负载(indexing和search)可以独立扩容,可以针对每个用例选择和优化硬件。
这解决了indexing和search相互影响的问题,使得日志场景下用户可以避免大查询影响写入;搜索场景用户可以使用大量索引时间功能来提高相关性和搜索性能而不影响搜索性能
更便宜的对象存储
新架构为了扩展性和存储成本使用廉价的对象存储。因为这点,ES通过持久化segment并在对象存储上复制segment,是的不需要复制indexing operation到多个replica节点并且节点仍需构建segment,因此减少了indexing成本。
大规模低延迟查询
对象存储可以支持大量数据,但不以速度或低延迟而闻名。为了解决引入多一层对象存储的延迟,在查询对象存储时ES支持了segment级别的并行查询,之前是单个分片一个查询线程从本地磁盘拉数据。通过可重用性和针对每种数据类型利用最佳 Lucene 索引格式,缓存也变得“更加智能”
参考
https://www.elastic.co/blog/elastic-serverless-architecture
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大数据深度学习ResNet深度残差网络详解:网络结构解读与PyTorch实现教程
- ansible的脚本—playbook剧本
- 详细教程 - 从零开发 鸿蒙harmonyOS应用 第四节 (鸿蒙Stage模型 登录页面 ArkTS版 推荐使用)
- 如何使用ArcGIS Pro拼接影像
- ASP.NET Core基础之用扩展方法封装服务配置
- 【Vue3】2-3 : 选项式API的编程风格与优势
- 跟着暄桐林曦老师读《宝贵的人生建议》,重视心这颗种子
- 千寻位置北斗高精度定位方案获40多家车企品牌订单
- ReactRouter6的用途和好处
- 【数组Array】力扣-304 二维区域和检索 - 矩阵不可变