38、Flink 的CDC 格式:canal部署以及示例
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
本文详细的介绍了canal的部署、2个示例以及在Flink 中通过canal将数据变化信息同步到Kafka中,然后通过Flink SQL client进行读取。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,还依赖Flink 、kafka和canal环境好用。
一、Canal Format
1、canal 介绍
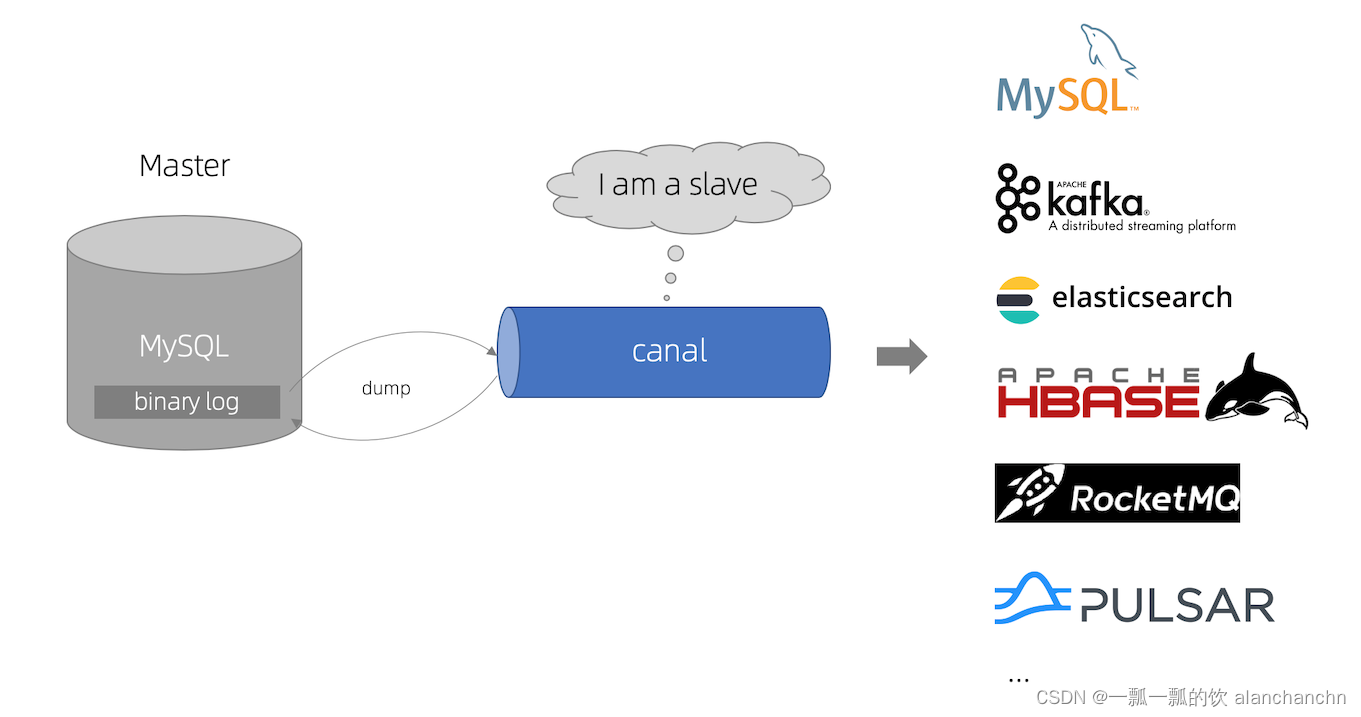
Canal 是一个 CDC(ChangeLog Data Capture,变更日志数据捕获)工具,可以实时地将 MySQL 变更传输到其他系统。Canal 为变更日志提供了统一的数据格式,并支持使用 JSON 或 protobuf 序列化消息(Canal 默认使用 protobuf)。
Flink 支持将 Canal 的 JSON 消息解析为 INSERT / UPDATE / DELETE 消息到 Flink SQL 系统中。在很多情况下,利用这个特性非常的有用。
例如
- 将增量数据从数据库同步到其他系统
- 日志审计
- 数据库的实时物化视图
- 关联维度数据库的变更历史,等等。
Flink 还支持将 Flink SQL 中的 INSERT / UPDATE / DELETE 消息编码为 Canal 格式的 JSON 消息,输出到 Kafka 等存储中。 但需要注意的是,截至 Flink 1.17版本 还不支持将 UPDATE_BEFORE 和 UPDATE_AFTER 合并为一条 UPDATE 消息。因此,Flink 将 UPDATE_BEFORE 和 UPDATE_AFTER 分别编码为 DELETE 和 INSERT 类型的 Canal 消息。
未来会支持 Canal protobuf 类型消息的解析以及输出 Canal 格式的消息。
2、binlog设置及验证
设置binlog需要监控的数据库,本示例使用的数据库是mysql5.7
1)、配置
本示例设置的参数参考下面的配置
[root@server4 ~]# cat /etc/my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
......
log-bin=mysql-bin # log-bin的名称,可以是任意名称
binlog-format=row # 推荐该参数,其他的参数视情况而定,比如mixed、statement
server_id=1 # mysql集群环境中不要重复
binlog_do_db=test # test是mysql的数据库名称,如果监控多个数据库,可以添加多个binlog_do_db即可,例如下面示例
# binlog_do_db=test2
# binlog_do_db=test3
.....
-
STATEMENT模式(SBR)
每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题) -
ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。 -
MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
2)、重启mysql
保存配置后重启mysql
service mysqld restart
3)、验证
重启后,可以通过2个简单的方法验证是否设置成功。
mysql默认的安装目录:cd /var/lib/mysql
[root@server4 ~]# cd /var/lib/mysql
[root@server4 mysql]# ll
......
-rw-r----- 1 mysql mysql 154 1月 10 2022 mysql-bin.000001
-rw-r----- 1 mysql mysql 1197 1月 16 12:21 mysql-bin.index
.....
- 查看mysql-bin.000001文件是否生成,且其大小为154字节。mysql-bin.000001是mysql重启的次数,重启2次则为mysql-bin.000002
- 在test数据库中创建或添加数据,mysql-bin.000001的大小是否增加
以上情况满足,则说明binlog配置正常
3、canal部署
1)、下载
去其官网:https://github.com/alibaba/canal/wiki下载需要的版本。
本示例使用的是:canal.deployer-1.1.7.tar.gz
2)、解压
先创建需要解压的目录/usr/local/bigdata/canal/
tar -zvxf canal.deployer-1.1.7.tar.gz -C /usr/local/bigdata/canal/
[alanchan@server3 canal]$ ll
总用量 20
drwxr-xr-x 2 root root 4096 1月 16 05:30 bin
drwxr-xr-x 5 root root 4096 1月 17 00:45 conf
drwxr-xr-x 2 root root 4096 11月 28 08:56 lib
drwxrwxrwx 4 root root 4096 11月 28 09:23 logs
drwxrwxrwx 2 root root 4096 10月 13 06:09 plugin
4、示例1:canal CDC 输出至控制台
本示例是将mysql变化的数据在控制台中显示,做该步操作需要自行编写代码,也就是做canal的client。
1)、修改canal的配置
需要修改2个配置文件,即
/usr/local/bigdata/canal/conf/canal.properties
和
/usr/local/bigdata/canal/conf/example/instance.properties。
- canal.properties修改
由于本处是通过client的控制台展示,所以需要将该配置文件中的canal.serverMode = tcp - instance.properties
修改配置文件的
canal.instance.master.address=192.168.10.44:3306 # 监控的数据库
canal.instance.dbUsername=root # 访问该数据库的用户名
canal.instance.dbPassword=123456 # 访问该数据库的用户名对应的密码
canal.instance.filter.regex=.\… #该参数是监控数据库对应的表的监控配置,默认是全表
2)、启动canal
[root@server3 bin]$ pwd
/usr/local/bigdata/canal/bin
[root@server3 bin]$ startup.sh
......
[root@server3 ~]# jps
20330 CanalLauncher
出现上面的进程名称,说明启动成功。
3)、maven依赖
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
</dependencies>
4)、代码实现
本处仅仅是解析binlog文件内容,以及将解析的内容输出。
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.protocol.Message;
/*
* @Author: alanchan
* @LastEditors: alanchan
* @Description:
*/
public class TestCanalDemo {
public static void main(String[] args) {
// 创建链接
// 这里填写canal所配置的服务器ip,端口号,destination(在canal.properties文件里)以及服务器账号密码
// ip 是 canal的服务端地址
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.10.43", 11111),
"example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
// connector.subscribe(".*\\..*");
connector.subscribe("test.*"); // test 数据库
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN
|| entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
5)、验证
需要 先启动canal服务端,再启动java应用程序。
为简单起见,已经在mysql创建好test数据库和在该数据库下创建的userscoressink表,其表结构如下:
CREATE TABLE `userscoressink` (
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`scores` float NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
应用程序启动后,先删除该表的数据,然后新增数据和修改数据。
控制台输出如下
empty count : 1
empty count : 2
================> binlog[mysql-bin.000063:6811] , name[test,userscoressink] , eventType : DELETE
name : alanchan update=false
scores : 10.0 update=false
================> binlog[mysql-bin.000063:7090] , name[test,userscoressink] , eventType : DELETE
name : alan update=false
scores : 20.0 update=false
name : alanchan update=true
scores : 20.0 update=true
empty count : 1
empty count : 2
================> binlog[mysql-bin.000063:8477] , name[test,userscoressink] , eventType : INSERT
name : alanchanchn update=true
scores : 30.0 update=true
empty count : 1
================> binlog[mysql-bin.000063:8759] , name[test,userscoressink] , eventType : UPDATE
-------> before
name : alanchanchn update=false
scores : 30.0 update=false
-------> after
name : alanchanchn update=false
scores : 80.0 update=true
empty count : 1
empty count : 2
empty count : 3
至此,已经完成了canal控制台的输出验证。
5、示例2:canal CDC 输出值kafka
该步骤需要已经安装好kafka的环境。
1)、修改canal配置
需要修改2个配置文件,即
/usr/local/bigdata/canal/conf/canal.properties
和
/usr/local/bigdata/canal/conf/example/instance.properties。
- canal.properties修改
由于本处是通过client的控制台展示,所以需要将该配置文件中的
canal.serverMode = kafka
kafka.bootstrap.servers = 192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092
其他的使用默认即可,如果需要的话,根据自己的环境进行修改。 - instance.properties
修改配置文件的
canal.instance.master.address=192.168.10.44:3306 # 监控的数据库
canal.instance.dbUsername=root # 访问该数据库的用户名
canal.instance.dbPassword=123456 # 访问该数据库的用户名对应的密码
canal.instance.filter.regex=.\… #该参数是监控数据库对应的表的监控配置,默认是全表
canal.mq.topic=alan_canal_to_kafka_topic # kafka接收数据的主题
canal.mq.partition=0 # kafka主题对应的分区
2)、启动canal
如果之前已经启动了canal,则需要先stop。
[root@server3 bin]$ pwd
/usr/local/bigdata/canal/bin
[root@server3 bin]$ startup.sh
......
[root@server3 ~]# jps
20330 CanalLauncher
3)、验证
需要 先启动canal服务端,再启动java应用程序。
为简单起见,已经在mysql创建好test数据库和在该数据库下创建的userscoressink表,其表结构如下:
CREATE TABLE `userscoressink` (
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`scores` float NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
应用程序启动后,先删除该表的数据,然后新增数据和修改数据。
- 启动kafka命令行消费模式
kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_canal_to_kafka_topic --from-beginning
- 在mysql中操作表, 观察kafka输出结果
{
"data": [{
"name": "alanchanchn",
"scores": "30.0"
}],
"database": "test",
"es": 1705385155000,
"gtid": "",
"id": 5,
"isDdl": false,
"mysqlType": {
"name": "varchar(255)",
"scores": "float"
},
"old": [{
"name": "alan"
}],
"pkNames": null,
"sql": "",
"sqlType": {
"name": 12,
"scores": 7
},
"table": "userscoressink",
"ts": 1705385629948,
"type": "UPDATE"
} {
"data": [{
"name": "alan_chan",
"scores": "40.0"
}],
"database": "test",
"es": 1705385193000,
"gtid": "",
"id": 6,
"isDdl": false,
"mysqlType": {
"name": "varchar(255)",
"scores": "float"
},
"old": null,
"pkNames": null,
"sql": "",
"sqlType": {
"name": 12,
"scores": 7
},
"table": "userscoressink",
"ts": 1705385668291,
"type": "INSERT"
} {
"data": [{
"name": "alan_chan",
"scores": "40.0"
}],
"database": "test",
"es": 1705385489000,
"gtid": "",
"id": 7,
"isDdl": false,
"mysqlType": {
"name": "varchar(255)",
"scores": "float"
},
"old": null,
"pkNames": null,
"sql": "",
"sqlType": {
"name": 12,
"scores": 7
},
"table": "userscoressink",
"ts": 1705385963893,
"type": "DELETE"
} {
"data": [{
"name": "alan_chan",
"scores": "80.0"
}],
"database": "test",
"es": 1705385976000,
"gtid": "",
"id": 8,
"isDdl": false,
"mysqlType": {
"name": "varchar(255)",
"scores": "float"
},
"old": null,
"pkNames": null,
"sql": "",
"sqlType": {
"name": 12,
"scores": 7
},
"table": "userscoressink",
"ts": 1705386450899,
"type": "INSERT"
} {
"data": [{
"name": "alan_chan",
"scores": "80.0"
}],
"database": "test",
"es": 1705386778000,
"gtid": "",
"id": 10,
"isDdl": false,
"mysqlType": {
"name": "varchar(255)",
"scores": "float"
},
"old": null,
"pkNames": null,
"sql": "",
"sqlType": {
"name": 12,
"scores": 7
},
"table": "userscoressink",
"ts": 1705387252955,
"type": "DELETE"
} {
"data": [{
"name": "alan1",
"scores": "100.0"
}],
"database": "test",
"es": 1705387290000,
"gtid": "",
"id": 14,
"isDdl": false,
"mysqlType": {
"name": "varchar(255)",
"scores": "float"
},
"old": null,
"pkNames": null,
"sql": "",
"sqlType": {
"name": 12,
"scores": 7
},
"table": "userscoressink",
"ts": 1705387765290,
"type": "INSERT"
}
以上,完成了通过canal监控mysql的数据变化同步到kafka中。
二、Flink 与 canal 实践
为了使用Canal格式,使用构建自动化工具(如Maven或SBT)的项目和带有SQL JAR包的SQLClient都需要以下依赖项。
1、maven依赖
该依赖在flink自建工程中已经包含。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.17.1</version>
</dependency>
有关如何部署 Canal 以将变更日志同步到消息队列,请参阅上文的具体事例或想了解更多的信息参考 Canal 文档。
2、Flink sql client 建表示例
Canal 为变更日志提供了统一的格式,下面是一个从 MySQL 库 userscoressink表中捕获更新操作的简单示例:
{
"data": [{
"name": "alanchanchn",
"scores": "30.0"
}],
"database": "test",
"es": 1705385155000,
"gtid": "",
"id": 5,
"isDdl": false,
"mysqlType": {
"name": "varchar(255)",
"scores": "float"
},
"old": [{
"name": "alan"
}],
"pkNames": null,
"sql": "",
"sqlType": {
"name": 12,
"scores": 7
},
"table": "userscoressink",
"ts": 1705385629948,
"type": "UPDATE"
}
有关各个字段的含义,请参阅 Canal 文档
MySQL userscoressink表有2列(name,scores)。上面的 JSON 消息是 userscoressink表上的一个更新事件,表示 id = 5 的行数据上name 字段值从alan变更成为alanchanchn。
消息已经同步到了一个 Kafka 主题:alan_mysql_bycanal_to_kafka_topic2,那么就可以使用以下DDL来从这个主题消费消息并解析变更事件。
具体启动canal参考本文的第一部分的kafka示例,其他不再赘述。下面的部分仅仅是演示canal环境都正常后,在Flink SQL client中的操作。
-- 元数据与 MySQL "userscoressink" 表完全相同
CREATE TABLE userscoressink (
name STRING,
scores FLOAT
) WITH (
'connector' = 'kafka',
'topic' = 'alan_mysql_bycanal_to_kafka_topic2',
'properties.bootstrap.servers' = 'server1:9092,server2:9092,server3:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'canal-json' -- 使用 canal-json 格式
);
将 Kafka 主题注册成 Flink 表之后,就可以将 Canal 消息用作变更日志源。
-- 验证,在mysql中新增、修改和删除数据,观察flink sql client 的数据变化
Flink SQL> CREATE TABLE userscoressink (
> name STRING,
> scores FLOAT
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'alan_mysql_bycanal_to_kafka_topic2',
> 'properties.bootstrap.servers' = 'server1:9092,server2:9092,server3:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'earliest-offset',
> 'format' = 'canal-json'
> );
[INFO] Execute statement succeed.
Flink SQL> select * from userscoressink;
+----+--------------------------------+--------------------------------+
| op | name | scores |
+----+--------------------------------+--------------------------------+
| +I | name | 100.0 |
| +I | alan | 80.0 |
| +I | alanchan | 120.0 |
| -U | alanchan | 120.0 |
| +U | alanchan | 100.0 |
| -D | name | 100.0 |
-- 关于MySQL "userscoressink" 表的实时物化视图
-- 按name分组,对scores进行求和
Flink SQL> select name,sum(scores) from userscoressink group by name;
+----+--------------------------------+--------------------------------+
| op | name | EXPR$1 |
+----+--------------------------------+--------------------------------+
| +I | name | 100.0 |
| +I | alan | 80.0 |
| +I | alanchan | 120.0 |
| -D | alanchan | 120.0 |
| +I | alanchan | 100.0 |
| -D | name | 100.0 |
3、Available Metadata
以下格式元数据可以在表定义中公开为只读(VIRTUAL)列。
只有当相应的连接器转发格式元数据时,注意格式元数据字段才可用。
截至版本1.17,只有Kafka连接器能够公开其值格式的元数据字段。

以下示例显示了如何访问Kafka中的Canal元数据字段:
---- 建表sql
CREATE TABLE userscoressink_meta (
origin_database STRING METADATA FROM 'value.database' VIRTUAL,
origin_table STRING METADATA FROM 'value.table' VIRTUAL,
origin_sql_type MAP<STRING, INT> METADATA FROM 'value.sql-type' VIRTUAL,
origin_pk_names ARRAY<STRING> METADATA FROM 'value.pk-names' VIRTUAL,
origin_ts TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL,
name STRING,
scores FLOAT
) WITH (
'connector' = 'kafka',
'topic' = 'alan_mysql_bycanal_to_kafka_topic2',
'properties.bootstrap.servers' = 'server1:9092,server2:9092,server3:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'canal-json'
);
---- 验证
Flink SQL> CREATE TABLE userscoressink_meta (
> origin_database STRING METADATA FROM 'value.database' VIRTUAL,
> origin_table STRING METADATA FROM 'value.table' VIRTUAL,
> origin_sql_type MAP<STRING, INT> METADATA FROM 'value.sql-type' VIRTUAL,
> origin_pk_names ARRAY<STRING> METADATA FROM 'value.pk-names' VIRTUAL,
> origin_ts TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL,
> name STRING,
> scores FLOAT
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'alan_mysql_bycanal_to_kafka_topic2',
> 'properties.bootstrap.servers' = 'server1:9092,server2:9092,server3:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'earliest-offset',
> 'format' = 'canal-json'
> );
[INFO] Execute statement succeed.
Flink SQL> show tables;
+---------------------+
| table name |
+---------------------+
| userscoressink |
| userscoressink_meta |
+---------------------+
2 rows in set
Flink SQL> select * from userscoressink_meta;
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+-------------------------+--------------------------------+--------------------------------+
| op | origin_database | origin_table | origin_sql_type | origin_pk_names | origin_ts | name | scores |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+-------------------------+--------------------------------+--------------------------------+
| +I | cdctest | userscoressink | {name=12, scores=7} | (NULL) | 2024-01-19 04:56:28.144 | name | 100.0 |
| +I | cdctest | userscoressink | {name=12, scores=7} | (NULL) | 2024-01-19 05:09:45.610 | alan | 80.0 |
| +I | cdctest | userscoressink | {name=12, scores=7} | (NULL) | 2024-01-19 05:09:55.529 | alanchan | 120.0 |
| -U | cdctest | userscoressink | {name=12, scores=7} | (NULL) | 2024-01-19 05:10:12.051 | alanchan | 120.0 |
| +U | cdctest | userscoressink | {name=12, scores=7} | (NULL) | 2024-01-19 05:10:12.051 | alanchan | 100.0 |
| -D | cdctest | userscoressink | {name=12, scores=7} | (NULL) | 2024-01-19 05:10:21.966 | name | 100.0 |
4、Format 参数

5、重要事项:重复的变更事件
在正常的操作环境下,Canal 应用能以 exactly-once 的语义投递每条变更事件。在这种情况下,Flink 消费 Canal 产生的变更事件能够工作得很好。 然而,当有故障发生时,Canal 应用只能保证 at-least-once 的投递语义。 这也意味着,在非正常情况下,Canal 可能会投递重复的变更事件到消息队列中,当 Flink 从消息队列中消费的时候就会得到重复的事件。 这可能会导致 Flink query 的运行得到错误的结果或者非预期的异常。因此,建议在这种情况下,将作业参数 table.exec.source.cdc-events-duplicate 设置成 true,并在该 source 上定义 PRIMARY KEY。 框架会生成一个额外的有状态算子,使用该 primary key 来对变更事件去重并生成一个规范化的 changelog 流。
6、数据类型映射
目前,Canal Format 使用 JSON Format 进行序列化和反序列化。 有关数据类型映射的更多详细信息,请参阅 JSON Format 文档。
以上,本文详细的介绍了canal的部署、2个示例以及在Flink 中通过canal将数据变化信息同步到Kafka中,然后通过Flink SQL client进行读取。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Mesh网格撞击变形
- 罚函数法处理不等式约束
- 生物信息学导论-北大-马尔可夫模型
- Spring Boot注解大全:从入门到精通,轻松掌握Spring Boot核心注解!
- TypeScript基础知识:类和继承
- SparkSQL的编程模型(DataFrame和DataSet)
- <软考高项备考>《论文专题 - 49 范围管理(8) 》
- OpenHarmony4.0Release系统应用常见问题FAQ
- 走进golang
- torch.cat()函数的理解