《PySpark大数据分析实战》-06.安装环境准备
📋 博主简介
- 💖 作者简介:大家好,我是wux_labs。😜
热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。
通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP)、TiDB数据库认证SQL开发专家(PCSD)认证。
通过了微软Azure开发人员、Azure数据工程师、Azure解决方案架构师专家认证。
对大数据技术栈Hadoop、Hive、Spark、Kafka等有深入研究,对Databricks的使用有丰富的经验。- 📝 个人主页:wux_labs,如果您对我还算满意,请关注一下吧~🔥
- 📝 个人社区:数据科学社区,如果您是数据科学爱好者,一起来交流吧~🔥
- 🎉 请支持我:欢迎大家 点赞👍+收藏??+吐槽📝,您的支持是我持续创作的动力~🔥
《PySpark大数据分析实战》-06.安装环境准备
《PySpark大数据分析实战》-06.安装环境准备
前言
大家好!今天为大家分享的是《PySpark大数据分析实战》第2章第1节的内容:安装环境准备。

安装环境准备
Spark是运行在JVM上的,JVM是跨平台的,所以Spark可以跨平台运行在各种类型的操作系统上。但是在实际使用中,通常都将Spark安装部署在Linux服务器上,所以需要准备好用来安装Spark的Linux服务器,本专栏内容以Ubuntu 20.04作为目标操作系统。本地模式下,需要1台服务器;独立集群模式下,至少需要3台服务器;Spark on YARN模式下,至少需要3台服务器;云环境模式下,不需要自己准备服务器,在创建集群的时候可以选择集群规模需要多少节点。
准备3台服务器,用来安装Hadoop、Hive、Spark等集群,主机名称以及IP地址分别是node1(10.0.0.5)、node2(10.0.0.6)、node3(10.0.0.7),并在3台服务器上完成基础配置,所有服务器按统一规划配置,供后续安装配置集群使用。
再准备1台服务器,用来安装后续会使用到的MySQL、Kafka等其他组件,主机名称以及IP地址是node4(10.0.0.8)。
以下环境准备步骤,需要在3台服务器上同步进行,保证3台服务器的环境信息一致。
操作系统准备
安装Spark环境的操作系统需要统一完成最基本的设置,包括创建统一用户、配置域名解析及设置免密登录。
创建安装用户
操作系统用户统一使用hadoop、软件安装目录统一使用${HOME}/apps,所以需要在系统中创建hadoop用户并在hadoop用户的home目录下创建apps目录。使用root用户创建hadoop用户,命令如下:
# 创建hadoop用户
useradd -m hadoop -s /bin/bash
# 修改密码
passwd hadoop
# 增加管理员权限
adduser hadoop sudo
使用hadoop用户登录,创建apps目录,命令如下:
$ mkdir -p apps
配置域名解析
Spark集群的配置文件中涉及到节点的配置都使用主机名称进行配置,为了保证3台服务器能够正确识别每个主机名称对应的正确IP地址,需要为每台服务器配置域名解析。域名解析配置在/etc/hosts文件中,在3台服务器上分别编辑该文件输入IP与主机名称的映射关系,命令如下:
$ sudo vi /etc/hosts
域名解析配置内容如下:
10.0.0.5 node1
10.0.0.6 node2
10.0.0.7 node3
10.0.0.8 node4
配置免密登录
在集群模式下,多台服务器共同协作,需要配置各个节点之间的免密登录,避免节点之间交互时需要输入密码。在node1上生成密钥对,将密钥对复制到所有节点上,确保执行ssh连接到任意节点不会要求输入密码。配置免密登录及密钥对复制的命令如下:
$ ssh-keygen -t rsa
$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
$ ssh node1
$ ssh node2
$ ssh node3
$ scp -r .ssh hadoop@node1:~/
$ scp -r .ssh hadoop@node2:~/
$ scp -r .ssh hadoop@node3:~/
Java环境准备
Spark是用Scala语言编写的,运行在JVM环境上,需要在安装Spark的服务器上安装并配置Java。根据集群的规划,给集群中的每一个节点都安装Java环境,安装版本需要是Java 8及以上的版本。在Ubuntu操作系统中,可以通过命令来安装Java 8,命令如下:
$ sudo apt-get update
$ sudo apt-get install -y openjdk-8-jdk
安装完成后需要配置环境变量,命令如下:
$ vi .bashrc
环境变量配置内容如下:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
Python环境准备
Spark提供了对Python的支持,提供了PySpark库,本z专栏内容以Python作为主要开发语言,需要在服务器环境中需要安装Python 3。Linux服务器通常自带Python环境,低版本的Linux自带的Python环境通常是Python 2,高版本的Linux自带的Python环境有可能是Python 3。如果自带的环境是Python 2,需要重新安装Python 3,命令如下:
$ sudo apt-get install -y python3.8
如果使用其他方式安装Python 3,推荐使用Anaconda 3安装。Anaconda 3安装过程,参考官方文档https://docs.anaconda.com/anaconda/install/linux/。
安装完成以后,确保服务器上执行python3命令不会报错。
Spark安装包下载
在安装Spark之前,需要通过官方网站下载Spark的安装包, Spark的官方下载地址是https://spark.apache.org/downloads.html,下载页面如图所示。

直接点击下载链接将安装包下载到本地,再将安装包上传到需要安装Spark的Linux服务器上。
除了直接下载,还可以复制下载链接,在安装Spark的Linux服务器上通过wget等命令进行安装包的下载,wget下载命令如下:
$ wget https://dlcdn.apache.org/spark/spark-3.4.0/spark-3.4.0-bin-hadoop3.tgz
也可以通过国内镜像下载,命令如下:
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.4.0/spark-3.4.0-bin-hadoop3.tgz
下载完成的安装包存放在用户目录下。
Hadoop安装包下载
数据文件的存放依赖于HDFS,Spark on YARN模式的部署依赖YARN,这些都需要用到Hadoop集群,所以需要下载Hadoop安装包。通过Hadoop的官方网站下载Hadoop 3.3.x的安装包,Hadoop的官方下载地址是https://hadoop.apache.org/releases.html,下载页面如图所示。
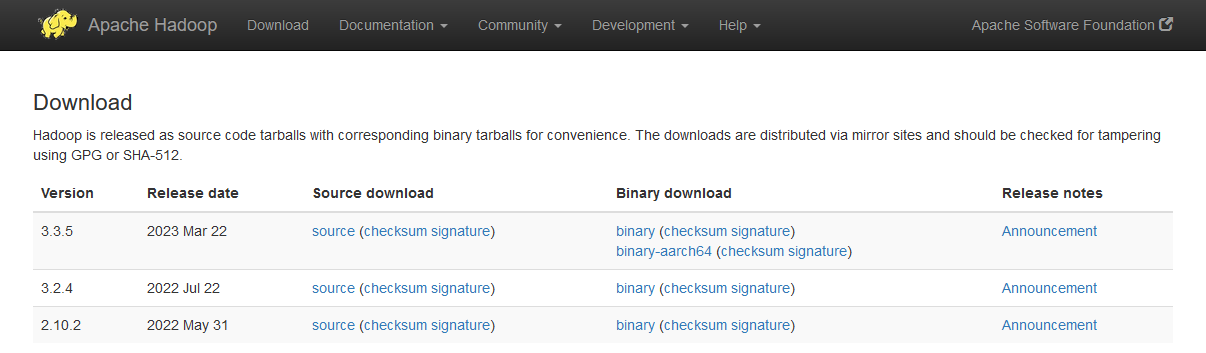
直接点击下载链接将安装包下载到本地,再将安装包上传到需要安装Hadoop的Linux服务器上。
除了直接下载,还可以复制下载链接,在安装Hadoop的Linux服务器上通过wget等命令进行安装包的下载,wget下载命令如下:
$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
也可以通过国内镜像下载,命令如下:
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
下载完成的安装包存放在用户目录下。
结束语
好了,感谢大家的关注,今天就分享到这里了,更多详细内容,请阅读原书或持续关注专栏。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- “喜欢自己”的意思是不喜欢自己也可以
- CE314 Computer Science NLP
- ChartGPT程序猿必备的软件,让你拥有一个免费的人工智能
- Linux--学习记录(3)
- 【Spring】SpringBoot 配置文件
- 路由的传参有哪些?
- 动手学深度学习一:环境安装与数据学习
- 堪比Postman!这款IDEA插件真好用!
- <软考高项备考>《论文专题 - 7 论文的项目背景之技术架构》
- 【c/python】用GTK实现一个带菜单的窗口