7.2 1D PARALLEL CONVOLUTION—A BASIC ALGORITHM
正如我们在第7.1节中提到的,所有输出(P)元素的计算可以在卷积中并行完成。这使得卷积成为并行计算的理想问题。根据我们在矩阵-矩阵乘法方面的经验,我们可以快速编写一个简单的并行卷积内核。为了简单起见,我们将从1D卷积开始。
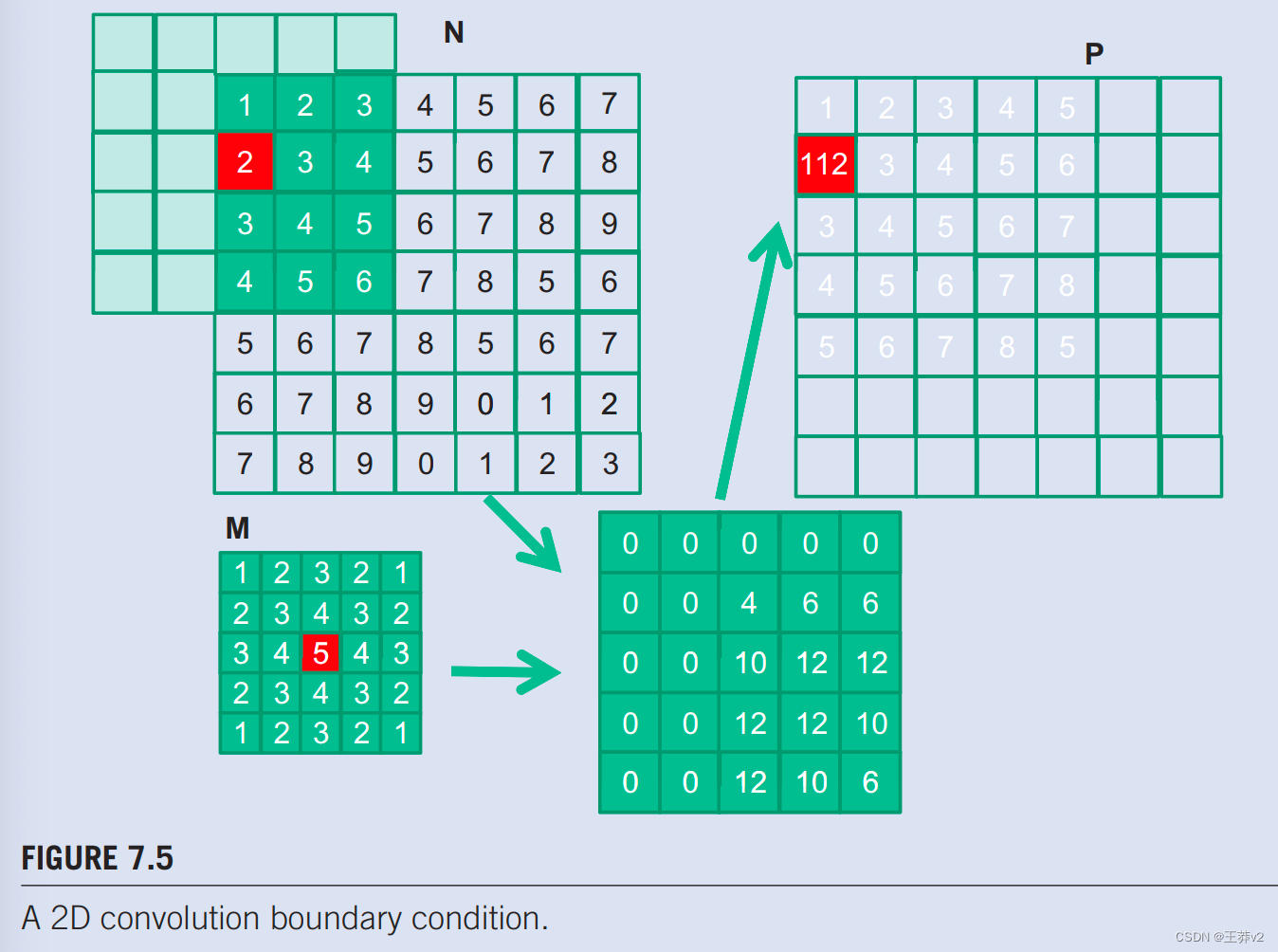
第一步是定义内核的主要输入参数。我们假设1D卷积内核收到五个参数:指向输入数组N的指针,指向输入掩码M的指针,指向输出数组P的指针,掩码Mask_Width的大小,以及输入和输出数组宽度的大小。因此,我们有以下设置:
__global__ void convolution_1D_basic_kernel(float *N, float *M,
float *P,
int Mask_Width, int Width) {
// kernel body
}
第二步是确定并实现线程到输出元素的映射。由于输出数组是ID,一个简单而好的方法是将线程组织成一个1D网格,并将每个线程放在网格中来计算一个输出元素。读者应该认识到,就输出元素而言,这与向量加法示例的安排相同。因此,我们可以使用以下语句从每个线程的块索引、块尺寸和线程索引中计算输出元素索引:
int i = blockIdx.x*blockDim.x + threadIdx.x;
一旦我们确定了输出元素索引,我们就可以使用输出元素索引的偏移量访问输入N元素和掩码M元素。为了简单起见,我们假设Mask_Width是一个奇数,卷积是对称的,即Mask_Width是2*n + 1,其中n是整数。P[i]的计算将使用 N[i-n], N[i-n+1],…, N[i-1], N[i], N[i+1], N[i+n-1], N[i+n]。我们可以使用一个简单的循环在内核中进行此计算:

变量Pvalue将允许将所有中间结果累积在寄存器中,以节省DRAM带宽。for循环累积了从相邻元素到输出P元素的所有贡献。循环中的if语句测试使用的任何输入N元素是否是幽灵单元,位于N数组的左侧或右侧。由于我们假设0值将用于幽灵细胞,我们可以简单地跳过幽灵细胞元素及其相应的N个元素的乘法和累积。循环结束后,我们将P值释放到输出P元素中。我们现在在图7.6.中有一个简单的内核。

我们可以对图7.6中的内核进行两项观察。首先,将有控制流发散。计算P数组左端或右端附近的输出P元素的线程将处理幽灵单元格。正如我们在第7.1节中展示的那样,每个相邻的线程都会遇到不同数量的幽灵细胞。因此,在if声明中,它们都将是一些不同的决定。计算P[0]的线程将跳过大约一半的乘法累积语句,而计算P[1]的那个会少跳过一次,以及以此为由。控制发散的成本将取决于输入数组大小的宽度和掩码大小的mask_width。对于大型输入阵列和小型掩码,控制发散只发生在一小部分输出元素中,这将保持控制发散的影响很小。由于卷积通常应用于大型图像和空间数据,我们通常期望收敛的效果是适度的或微不足道的。
一个更严重的问题是内存带宽。在内核中,浮点算术计算与全局内存访问的比率仅约为1.0。正如我们在矩阵-矩阵乘法示例中看到的,这个简单的内核只能以峰值性能的一小部分运行。在接下来的两节中,我们将讨论减少全局内存访问次数的两个关键技术。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 5G阅信在教研行业应用场景有哪些?
- Linux第35步_在“移植uboot”前安装libncurses5-dev
- docker小白第七天
- 【Proteus仿真】【51单片机】光照强度检测系统
- uni-app订单详情页导航栏交互
- 24年初级会计报名注意事项及报名详细流程,快查收,错过再等一年
- 二维码智慧门牌管理系统升级解决方案:费用缴纳更便捷
- IDEA好用的插件
- 【RocketMQ每日一问】rocketmq事务消息原理?
- CSDN规则详解——如何上热榜