如何提高大模型的外推能力
如何提高大模型的外推能力
?
外推性
外推是指模型在处理或理解超出其训练数据范围内的信息时的能力。
通俗来说,就像是让一个人去处理他之前没有直接学习或经验的事情。
举个例子,假设你学过加减乘除,但没有学过代数。
如果有人问你一个代数问题,你可能会觉得困难,因为这超出了你之前学的范围。
但如果你能够运用你所学的知识,去理解和解决这个代数问题,那就说明你具有一定的“外推性”。
在大型语言模型的背景下,外推性指的是模型对于那些它在训练时没有直接接触过的新情况、新问题或更长的文本的处理能力。
一个具有良好外推性的模型能够在面对新颖或未曾直接训练过的数据时,仍然表现出较好的理解和处理能力。
?
增加外推能力的 3 种方法
-
增加上下文窗口的微调:这种方法是最直接的。它通过扩大模型的上下文窗口来适应长文本建模的需求。上下文窗口越大,模型就能够处理越长的文本序列。然而,这种方法有其局限性,因为仅仅增加窗口大小并不总是有效地提高模型处理长文本的能力,尤其是在模型需要理解非常长的序列时。
-
改进的位置编码(如 ALiBi, LeX):这些技术通过实现长度外推来扩展模型的能力,意味着它们可以在短的上下文窗口上进行训练,但在长的上下文窗口上进行推理。这使得模型能够更有效地处理比其训练时所见更长的序列。
-
插值法:这种方法通过将超出上下文窗口的位置编码压缩到预训练的上下文窗口中,允许模型处理比其原始设计更长的文本。这种技术在保持模型结构不变的情况下,通过对位置编码的智能处理来实现长文本处理的能力。
?
改进的位置编码
-
绝对位置编码 vs 相对位置编码
- 绝对位置编码:直接将位置信息融入模型输入,适用于特定任务和数据集,但可能不适用于超长序列。
- 相对位置编码:在自注意力机制中引入两个 token 之间的相对位置信息,例如 RoPE 和 ALiBi。
-
旋转位置编码 (RoPE)
- 概念:RoPE 是一种在 Transformer 模型中使用的技术,旨在增强模型处理长上下文的能力。
- 它通过绝对位置编码实现相对位置编码的效果。
- 工作原理:RoPE 通过将 token embeddings 映射到 3D 图表上,并利用旋转矩阵来表达不同 token 之间的相对位置。
- 优势:RoPE 能够处理超出模型预训练长度的输入,有效理解长文本。
-
ALiBi 与其他位置编码技术
- ALiBi (Attention with Linear Biases):一种相对位置编码技术,适用于处理长序列,并能在推理时处理超出训练长度的序列。
- 特点:ALiBi 不使用实际的位置嵌入,而是根据键和查询之间的距离调整注意力分配。
-
不同版本的 Baichuan 模型
- Baichuan-7B vs 13B:7B 版本使用 RoPE 编码,而 13B 版本采用 ALiBi 位置编码。
- 后者在处理长上下文窗口方面表现更佳。
?
ALiBi
ALiBi,这是一种在 Transformer 模型中使用的相对位置编码技术。
不同于常规的位置编码方法,ALiBi 不在模型的 Embedding 层添加位置信息,而是在计算注意力权重时添加一个静态的、不可学习的偏置项。
理解 ALiBi 的核心在于它如何处理位置信息。
在传统的 Transformer 模型中,位置信息通常是通过添加一个可学习的位置向量到每个 token 的嵌入中实现的。

ALiBi 采用了一种不同的方法:
-
偏置项的引入:在计算注意力分数时,ALiBi 为 Softmax 函数的输入添加了一个偏置项。
- 这个偏置项是一个向量,其元素对应于 token 之间的相对位置。
-
偏置向量的形式:偏置向量的形式为 ( m ? [ ? ( i ? 1 ) , … , ? 2 , ? 1 , 0 ] ) ( m \cdot [-(i-1), \dots, -2, -1, 0] ) (m?[?(i?1),…,?2,?1,0]),其中 i i i 是序列中的位置, m m m 是一个斜率值,它对于模型中的不同注意力头是不同的。
- 这意味着,偏置向量是一个线性递减的序列,它从 ? ( i ? 1 ) -(i-1) ?(i?1) 开始,一直到 0。
-
斜率值 ( m ):斜率 m m m 对于模型中每个注意力头都是不同的,它定义为一个几何序列。
- 例如,在一个有 8 个注意力头的模型中,斜率可以是 1 2 1 , 1 2 2 , … , 1 2 8 \frac{1}{2^1}, \frac{1}{2^2}, \dots, \frac{1}{2^8} 211?,221?,…,281?。
- 这意味着每个注意力头将以不同的速率递减它的偏置值。
-
图解解释:图中左侧展示的是标准的注意力分数计算,即查询 q i \mathbf{q}_i qi? 和键 k j \mathbf{k}_j kj? 的点积。
- 右侧的图展示了应用偏置项后的影响,这个偏置项是一个随位置线性递减的矩阵。
- 当我们将这个偏置项与斜率 ( m ) 相乘后,它就会调整注意力分数,使得模型倾向于关注近处的 token 而非远处的。
-
归纳偏差:ALiBi 通过这种方式引入了一种归纳偏差,这种偏差倾向于更靠近查询的键。
- 换句话说,模型被设计为对近距离的 token 给予更多的注意力,而随着距离的增加,给予的注意力逐渐减少。
-
斜率参数的通用性:经过实验证明,这组斜率参数适用于不同的文本领域和模型大小,并且通常不需要根据新的数据集或模型架构进行调整。
通过这种方式,ALiBi 能够有效地处理长距离的依赖关系,同时减少计算复杂性,因为它不需要学习或更新位置编码。
?
旋转位置编码 RoPE
旋转位置编码 (RoPE) 是一种特定的位置编码方式,它使用复数和三角函数来编码单词在序列中的相对位置信息。
RoPE 的设计使得模型的注意力机制能够直接利用相对位置信息,而不是依赖于绝对位置。
RoPE 的核心是将位置编码与词嵌入相结合,形成一种旋转的效果,这有助于模型捕捉长距离依赖关系。
-
位置索引和嵌入向量:
- 在 Transformer 模型中,我们通常给每个词分配一个嵌入向量 x x x,这个向量包含了词的语义信息。
- 每个词还有一个位置索引 ( m ),表示它在文本中的位置。这个索引的取值范围是从 0 到 ( c-1 ),其中 ( c ) 是上下文窗口的大小,即模型能考虑的最大文本长度。
- 向量 ( x ) 的维度 ( d ) 对应于模型中一个注意力头的维度。
-
RoPE位置编码:
- RoPE使用复数运算来编码位置信息。在这里,( i ) 是虚数单位,不是索引。
- θ j \theta_j θj? 是一个根据维度 ( d ) 计算出来的值,这个值在编码过程中用来旋转每个维度的位置信息。具体来说,$\theta_j$ 的值会随着维度的增加而减小,这是通过预设的公式 1000 0 ? 2 j / d 10000^{-2j/d} 10000?2j/d 计算得出的。
-
注意力分数的依赖:
- 在标准的Transformer模型中,注意力分数取决于词之间的相对位置,RoPE通过一种特别的方式来确保这一点,即使得这些分数仅依赖于词之间的距离,而非它们在文本中的绝对位置。
-
外推能力问题:
- 当直接尝试扩展上下文窗口大小(即使模型处理更长的文本)时,RoPE位置编码可能会遇到问题。这通常会导致模型的困惑度(一种衡量模型性能的指标)急剧增加,这意味着模型变得不那么确定它的预测。
-
三角函数和基函数:
- 在数学中,三角函数(如正弦和余弦)可以用来拟合多种函数。这里, ? j ( s ) \phi_j(s) ?j?(s) 被视为基函数,它可以用来通过系数 h j h_j hj? 拟合注意力分数计算中的相对位置效应。
- ( s ) 表示查询和键之间的相对距离。
- h j h_j hj? 是一个复系数,依赖于查询 ( q ) 和键 ( k ) 的特定维度值。
-
RoPE的拟合能力和插值结果:
- 使用 RoPE,模型能够拟合几乎任何关于位置的函数,但如果没有训练,它可能在上下文窗口之外产生不理想的效果,例如,对于那些距离较远的词,模型可能给出过大的注意力分数。
- 相比之下,位置插值方法可以产生更加平滑且数值稳定的结果。
?
插值法
位置插值法的核心思想是调整模型理解位置的方式,而不是从头开始重新训练模型。
这个方法像是在数学上进行缩放操作,将一个很长的序列“压缩”成模型能够处理的大小。
这就好比你有一条很长的尺子,但是你的工具箱只能放下一把小尺子。
位置插值法就是将这条长尺子上的刻度间距缩小,这样它就能适应小尺子的长度了。
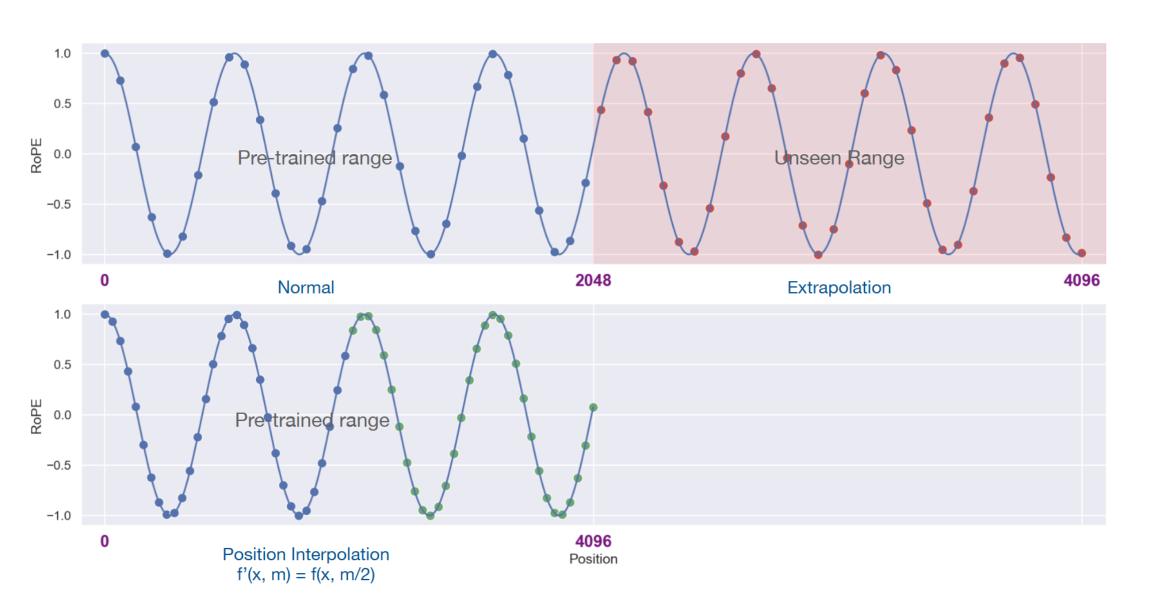
具体来说,位置插值法通过以下步骤工作:
-
缩小位置索引:将较长序列中的位置索引缩小(或者说“重映射”),使得序列的最大位置索引与模型在预训练阶段的上下文窗口限制相匹配。这样做,模型就能理解原本超出其处理范围的长序列。
-
微调:通过微小的调整(微调),来进一步优化模型的参数,以适应这种新的位置索引方式。这个过程远比完全重新训练模型来得快速和经济。
-
保持原有功能:这种方法的一个重要好处是,它允许模型在扩展其上下文窗口的同时,仍然保持原有的任务处理能力。这意味着模型不会因为能够处理更长的文本而失去其在其他任务上的效能。
-
重用现有模型和方法:通过位置插值,我们可以继续使用现有的预训练模型和优化方法,而不需要大规模的改动。这使得将模型应用到实际中变得更加容易和吸引人。
位置插值是一个巧妙的技术,它允许现有的预训练大型语言模型理解和处理比它们原本设计时更长的文本,而无需进行昂贵的重训练过程。
这为大型模型的实际应用和灵活性提供了极大的便利。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python&Matplotlib七:使用Matplotlib完成3D绘图
- python项目使用docker的方式部署,docker compose的方式启动
- 关于大模型学习中遇到的3
- 私有仓库工具Nexus Maven如何部署并实现远程访问管理界面
- 32位AT&T风格汇编语言输出数组中最大值
- Python学习之路-多任务:进程
- 详解ajax、fetch、axios的区别
- 云服务器安装宝塔详细教程
- docker里安装conda,并source本地已有的虚拟环境包
- Java数据结构与算法:排序算法之选择排序