scrapy post请求——百度翻译(十四)
发布时间:2023年12月18日
scrapy处理 post 请求
爬取百度翻译界面
目录
1.创建项目及爬虫文件
scrapy startproject scrapy_104
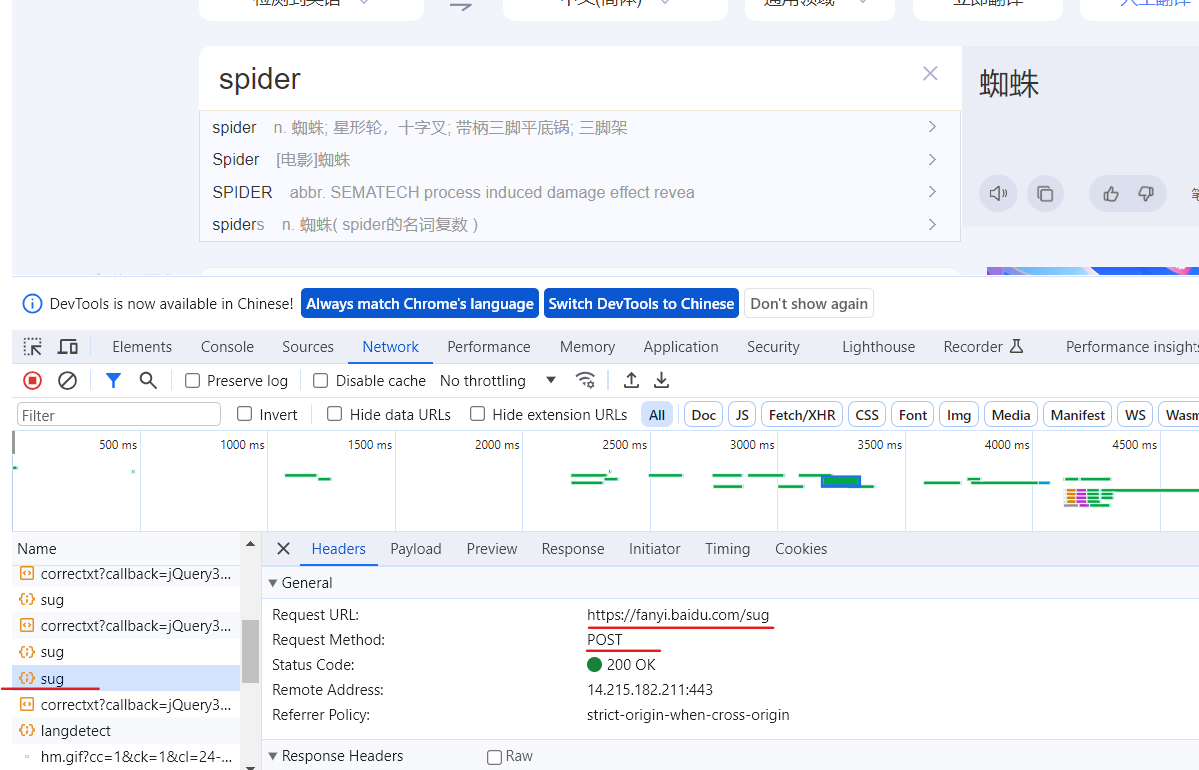
scrapy genspider translate?fanyi.baidu.com
2.发送请求
post请求需要传递参数,所以就不能用start_urls和parse函数了,这里使用start_requests函数给url添加参数。
class TranslateSpider(scrapy.Spider):
name = 'translate'
allowed_domains = ['fanyi.baidu.com']
# start_urls = ['http://fanyi.baidu.com/']
def start_requests(self):
url = 'http://fanyi.baidu.com/sug'
data = {
'kw':'spider'
}
yield scrapy.FormRequest(url=url, formdata=data,callback=self.parse_second)
def parse_second(self, response):
content = response.text
# print(content) # 存在编码问题
obj = json.loads(content,encoding='utf-8')
print(obj)这样就获取到了

文章来源:https://blog.csdn.net/m0_45447650/article/details/134463124
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 崩坏:星穹铁道藿藿为了成为合格判官,做了哪些胆量锻炼
- 关于C语言整型提升的讲解
- 大模型增量学习 (1)
- 进阶学习——Linux系统LVM逻辑卷的建立与磁盘配额
- Redis 之父锐评 LLM 编程:全知全能 && Stupid|一周IT资讯
- excel统计分析——Lilliefors正态性检验
- RuoYi-Vue-Plus 5.X登录前流程及解密
- 【获取/etc/passwd文件后的入侵方式】
- RabbitMQ的关键概念解析
- Python3 中常用字符串函数介绍